ScopedQuery: 查询你需要的数据,剪裁无用字段
作为前端,你肯定经常有这样的烦恼:我明明只需要这几个字段,结果你全部给我返回了,何必呢?今天我发了一个包 scopedquery 以解决这个问题。这里 scoped 的意思是“限定的”,也就是你进行的查询是在限定的内容里面。它基于一个新的语言,样子大概如下:
query "https://xxx.com/api/articles/:id" -> {
article_title
create_time: date('YYYY-MM-DD')
article_content
view_count: number
comments: [
{
comment_author
comment_content
comment_time: data('YYYY-MM-DD')
}
]
}
上面这段代码所表达的意思是,往 “http….” 发送了一个请求,这个请求要求返回的结果的形状,以及节点上对节点值的格式,需要按照 -> 后面的内容进行返回。
它看上去和 graphql 有点像,但又很不同。它是一个描述性语言,类似 JSON,而非一个编程性语言,即 graphql。graphql 虽然很好,但是,它依赖底层的建设和比较难理解的语法组织。而 ScopedQuery 则纯粹是为了解决数据裁剪而生,不负责底层库的查询,因此,它更轻量,且开箱即用。
npm i scopedquery
安装好后,在业务代码中这样写作:
import { Query } from 'scopedquery'
const data = await Query.run(`
query "http..." -> {
// 支持注释
// 裁剪后的内容
}
`)
默认情况下,内部会使用全局的 fetch 进行 ajax 请求,但是你可以自己定义:
const query = new Query({
fetch(url, params) {
// ...
}
})
const data = await query.run(`...`)
在 node 端,可以使用 Query.parse 方法直接裁剪数据:
const data = Query.parse(dataFromBackend, `{
name: string
age: number
}`)
冒号后面的 string, number 看上去是类型,实际上是格式化工具,它们可以被自定义,让开发者自己觉得不同情况下怎么返回值。
基于 webpack 的能力,我们可以把这些 query 文本单独保存,这样我们可以极为清晰的了解每一个接口对于前端而言,需要的是哪些内容,且有值描述,对于前后端而言,都可以作为参考,辅助前后端在开发过程中进行沟通。
certbot依赖变动导致https失效
今天进博客发现https又失效了,内心个崩溃,莫非终有一天我还是会走上付费的道路吗?之前记录过一次由于certbot依赖版本低导致的无法自动更新证书,今天再次用那个方法,发现没有用。遇到的错误提示如下:
Attempting to renew cert from produced an unexpected error: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:645). Skipping.
然后去外网搜索,找到一个线索,是由于依赖的DST_Root_CA_X3.crt过期了,这个DST_Root_CA_X3.crt应该是大部分服务器都一样,所以可以通过以下的方法解决:
sudo apt-get update
sudo apt-get upgrade
sudo sed -i 's/\(.*DST_Root_CA_X3.crt\)/!\1/' /etc/ca-certificates.conf sudo update-ca-certificates sudo certbot renew
通过这个方法,就可以更新证书了。
前端如何优雅建模?
这篇文章放在“杂”栏目下面,说明会是一篇不成体系的文章。我想谈一下如何在前端优雅的建模。直入正题!
前端建模包括两个层面的建模:业务领域建模和交互领域建模。这两者基本上没有本质联系,但是在前端这个场景下,有的时候又有一些特殊的情况。我们来看看如何在这两个层面建模。
业务领域建模
简单讲,业务领域建模,就是把业务实体与其逻辑进行建模。在知乎有小伙伴留言说,前端不怎么适合DDD,因为前端是贫血模型。但在我实际实践中,我更多是充血模型。业务模型需要包含字段本身,以及复杂的业务逻辑。你可能会讲,业务逻辑会被放在后端,但是实际上前端也要这个业务逻辑,比如当一个订单的负责人是组织中的某个职位的角色时,需要在订单推进过程中填写审核时间这个信息。那么,在前端,必须去判断当前用户是否是该角色,或者获得当前用户的某个权限。这个逻辑是跑不掉的。
最近,我升级了tyshemo,支持了装饰器的方式进行meta的定义。现在,你可以这样定义自己的模型:
import { Model, meta, state } from 'tyshemo'
class OrderModel extends Model {
@meta({
type: {
user_id: String,
},
})
master = null
@meta({
type: Number,
})
total_price = 0
@state()
role = 'member'
canFillDate() {
return this.role === 'admin'
}
}
通过@meta来装饰字段,通过@state来装饰状态属性。这样撰写模型,会有更舒服的感觉,而且可以更好的兼容typescript,避免以前使用static属性定义时,无法与typescript很好结合的问题。
简单讲,通过业务建模,我们得到了一些模型,这些模型是独立的,自治的,在不被使用的时候,它独立描述了该业务对象的各种字段及其逻辑,但由于不在具体的业务场景中被使用,因此也只能表现有限的业务信息,它只能告诉读代码的人“我有什么,能做什么”,而不能告诉“我做了什么”。只有使用这些模型的实例,放到具体的业务模块中,才能完成真正的模块编程。所以,单纯讲,业务建模虽然重要且有用,但是如果不被适当的人使用,就会非常混乱,毫无头绪。
建立业务模型,可以把有关需求文档中,有关核心业务的东西分出一层。
交互领域建模
这是后端没有的东西。直白讲,交互领域建模就是写类似Vue一样的View Model,但是没有template那块。简单说,就是建立一个模型,考虑到将来在view层使用它,所以该模型的所有api,都是为view设计的,主要目标,是和需求文档中有关交互相关的描述一一对应。在交互模型中,实例化业务模型,把业务模型变成交互模型内部的状态。当在view中实例化交互模型,就看不到业务模型了,view拿着交互模型的接口进行渲染和事件回调。
我在nautil中提供了可用于建立交互模型的一个体系。举个例子:
import { Component } from 'nautil'
import { SomeController } from './some.controller' // 写好的交互模型
class MyPage extends Component {
controller = new SomeController() // 实例化交互模型
SubmitButton = this.controller.turn((props) => {
const { someModel } = this.controller // 读取交互模型内的某个业务模型
const { total_price } = someModel // 读取业务字段值
return (
<button className={total_price > 100 ? 'sale-count' : undefined}>Submit</button>
)
})
render() {
const { SubmitButton } = this // 读取定义好的组件
}
}
上面这段代码中,SomeController是一个交互模型,里面使用了另外一个SomeModel业务模型。但是,对于view层而言,你不需要知道它是一个业务模型,你只需要调用它即可。
Nautil在controller中提供了turn方法,用于把一个用到controller的普通的组件转化为一个被controller控制的组件,当controller中某些特定信息发生变化时,这些组件就会自动更新。
分层
前端代码分层管理,从代码量上,并不比铁板一块的管理多多少,毕竟所有的代码,都来自产品的需求描述。但是,分层管理所带来的灵活性、可维护性是不可估量的。
如果你写一个有很多块的页面的vue组件,你就会发现,你的这个组件会越来越多交织在一起的代码,从一开始很容易理解,这几个状态和这几个方法是关于最顶上这一块的,但是,随着页面其他块的交互代码的增多,你就会发现,这个状态会在哪块用?这个方法会在什么情况下调?能不能删?可不可以改?都需要上下反复读代码来确认。
而如果你采取代码分层,你会先针对业务本身的实体进行建模,然后对业务中的交互进行建模,最后才是view层的编写。此时,view层的代码会清晰很多,因为它不再去管理属于业务的逻辑,而更多的是用和回调。
依赖
在view层,我们用vue或react来写,我更多使用react,因为react没有使用Proxy或defineProperty,可以使得我们建模时,使用更多魔法。但是,有些时候,由于view层的特殊机制,导致我们如果完全脱离框架进行建模时,不得不提供一些多余的接口,来帮助和view进行依赖绑定。
以我工作的项目为例,我们使用angularjs作为主体框架,如果我单纯使用ESModule的模块,就没有办法直接使用$rootScope等这种angularjs内置的服务,但是如果我提供一个angular factory,就会牺牲模型的可移植性,为之后跨平台复用带来问题。所以,nautil中提供了controller.turn这个方法来实现模型层和视图层的连接,简单说就是在框架层面调用forceUpdate来实现重新渲染。
Typescript中如何表达一个类是继承至某个类的?
在平时写代码时,我们常常会有这样的写法:
class BaseClass {}
function init(SomeClass) {
if (isInherited(SomeClass, BaseClass)) {
...
}
}
上面代码中,表示的是,init这个函数的参数,只接收继承自BaseClass的类,那么这种表达,在typescript中如何表示呢?
function init(SomeClass: ???) {
...
}
你看,这比较麻烦吧。你可能会想到:
function init(SomeClass: BaseClass): void
但这显然是不对的,这样表达的意思是SomeClass是BaseClass的实例,而不是类。
正确的表达是如下:
function init(SomeClass: new () => BaseClass): void
其中 new() 是 typescript 中的特殊表达形式,表示以该类型作为具体类进行实例化(需要注意,在typescript中,某个class既是类型,也是值)。而 new () => BaseClass 这句话的意思就是实例化之后得到的实例的类型是BaseClass,或者说,实例化之后是BaseClass的实例(由于在typescript中,某个class既是类型,也是值,因此,比较难用纯粹类型语言进行表达)。这样一来,我们就可以表达出“SomeClass是继承至BaseClass”这一要求。
Web性能指标
https://bitsofco.de/web-performance-metrics-cheatsheet/
SFCJS的实现思路
单文件组件(SFC)及语法
Vue 和 svelte 都具有自己的文件格式,在 .vue 或 .svelte 文件中,我们描述了一个组件的完整上下文。单文件组件这种组织方式特别适合单一功能的组件发布,你可以通过比较少的代码量,表达一个 UI 交互要做什么事情。
因此,我在写 sfcjs 时借鉴 svelte 的语法设计,在不改变原始 html, js 和 css 语法的基础上,增加了一些特定的形式。一个 sfc 包含三个部分 script, style, html,具体如下:
<script> let a =10;functionincrease() { a ++; } </script> <style> .foo { font-size: [[a]]px; } </style> <div> <span class="foo">{{a}}</span> <button @click="increase()">inc</button> </div>
这份示例代码中包含了组件内变量的声明和使用、动态 css 语法、动态 html 语法。由于 sfcjs 只是一个 POC,很多细节没有深入,所以只能展示一些比较粗浅的例子。
我们将上面这段代码放在一个 .htm 文件中,这样编辑器可以帮助我们为代码高亮。这个 .htm 文件即我们的一个组件文件。
基于AMD加载组件
我一开始想直接用 seajs 做加载引擎,但后来觉得没必要,因为我不需要严格的遵循 AMD 规范。但基于其实现原理,我们可以在需要的时候加载 sfc,实现文件异步加载和组件异步实例化。
在一个组件中引用另外一个组件,需要特殊的引用协议。
<script>
import SomeComponent from 'sfc:../components/some-component.htm'
const title = 'xxx'
</script>
<div>
<some-component :title="title"></some-component>
</div>在 import from 时,使用 sfc: 作为协议前缀,遇到一个路径时就认为是一个组件,然后在 html 模板中使用这个组件。SomeComponent 如果依赖了其他组件,它不会立即去请求这些组件的 sfc,而是会等到 SomeComponent 实例化的时候,再去请求。
运行时编译
组件 sfc 的语法显然是无法在浏览器直接运行的,我们需要做一个编译,而这个编译,我们直接在前端做。我们利用 webworker 或 webassembly 等技术,不占用 js 运行时线程,编译完之后,输出编译好的 js 脚本。输出的脚本以 blob 的形式,作为 script 进行载入,此时,利用 AMD 的 define,就可以让这个组件加入到我们的备选组件中。
整个加载编译过程如下:

这里的问题在于:1. 运行时编译,会不会性能不好?2. 安全性?
我相信你了解过 vite,简单说,vite 将 bundle 转化为单一文件网络,对每个文件进行编译,当该模块被使用时,发出 http 请求该文件,http 到达服务器时,对该文件进行编译后返回编译后的代码。从这个点上讲,运行时编译用的是客户端的资源,可能比 vite 还快。相反,前端的性能瓶颈,可能在加载巨大的 bundle 的时候更明显。至于安全性,在 compile 之前做一次 check 也是应该的,这看具体场景,因为 sfc.htm 的内容不是直接运行的脚本,只有它被编译为 js 之后,才会真正运行。
利用 web components 的设计
和 react 要用 render 函数来启动应用不同,sfcjs 如下启动一个组件:
<sfc-view src="./app.htm"></sfc-view>理论上,你可以在任意 web 应用中使用这个句式来渲染一个 sfcjs 的组件,包括但不限于在 react 或 vue 中。组件的渲染结果,将被放在该元素的 shadowRoot 中,包含样式。
样式隔离
腾讯前端框架 Omi 是基于 web components 的,可以比较好的隔离样式,你可以借助它开发自己的 custom element 来实现自己的 UI 组件。但是,这里有一个问题在于,如果一个组件依赖于另一个组件,那么必须把这两个组件打包在一起,甚至,被依赖的组件在特定条件下并不会被用到。几乎大部分框架和 omi 一样,都不是开箱即用的(除了 jquery 或 alpine.js),我们没法马上体验它的开发效果,而且,更要命的是,部分框架具有传染性,某些情况下,你只需要其中的某一个功能或组件,但是,你不得不在外面给它一个很大的运行时(例如 react-dom),并且它不兼容(或很难)其他的技术栈。而基于 web components 则可以比较好的实现外围运行时无关,无论你在 react 中,还是 angular 中,都可以使用基于 web components 写的组件。
我在写 sfcjs 时,想到这一点,组件应该是自治的,开发者不应该去思考,当前这个组件是否会(在样式上)影响其他组件的运行。你可以看下基于 sfcjs 写的两个组件:
<style>
.bar {
color: #ccc;
}
</style>
<button class="bar">ok</button><style>
.bar {
color: #999;
}
</style>
<button class="bar">yes</button>上面这两个组件都定义了 .bar 这个类,但是它们在同一个页面中使用时,不会相互污染。
它的原理是,基于 shadowDOM 完成渲染,因此,样式不会对其他元素产生影响。
响应式动态样式
通过修改变量可以让布局的部分变更,那样式呢?在 vue 的一个提案中,提出可以通过某种方式实现样式的响应式编程,具体如下:
<template>
<div class="text">hello</div>
</template>
<script>
export default {
data() {
return {
color: 'red'
}
}
}
</script>
<style vars="{ color }">
.text {
color: var(--color);
}
</style>也就是通过在 css 中使用 var 来标记变量。它基于css 变量这个被广泛支持和接受的技术,但 vue 的提案我觉得仍然暴露太多实现细节,在 sfcjs 中,结合语法,其响应式写法如下:
<script>
let age = 10;
function grow(e) {
// change variables may cause rerender
age ++;
}
</script>
<style>
.name {
color: #ffe;
}
.age {
color: rgb(
/* use js expression with `var('{{ ... }}')` */
var('{{ age * 5 > 255 ? 255 : age * 5 }}'),
var('{{ age * 10 > 255 ? 255 : age * 10 }}'),
var('{{ age * 3 > 255 ? 255 : age * 3 }}')
);
/* use variables with [[]] */
font-size: [[age]]px;
}
</style>在 sfc 文件中,上下文是流畅的一体,在 <script> 中定义的变量,在 style 和 html 中直接使用。当变量变化时,对应的样式值也发生变化。
其具体原理是,我在 shadowRoot 中建立了两块 <style> 一块用于提供变量(会被动态更新内部文本),另一块使用这些变量(永远不变)。

在对应的变量发生变化的时候,第一块整个内容都会被重建,而第二块内容中会使用重建后的样式重新渲染,从而达到动态更新样式的效果。
无 virtual dom 的响应式
进入 2021 年,新出现的几个热门框架都不在基于 virtual dom 实现响应式,一个重要的原因在于 virtual dom 的成本巨大,且性能上并不占优。
和 solidjs 一样,sfcjs 在编译时收集每一个 DOM 节点所依赖的变量,当对应的变量发生变化的时候,去重新计算对应的值,并与当前状态进行比较,最后更新 DOM 节点。这里的不同在于两点:1. 发生变化的变量对应的 DOM 节点才会去计算,其他 DOM 节点即使依赖变量,但没有变化,不用计算。2. 直接对单个 DOM 节点进行是否需要更新的计算,而不再拿整个组件的节点树来进行 diff。
这个实现不算创新,甚至在早几年的时候就有人这么做过。
对于 sfcjs 来说,魔法在于,基于原始语法不需要做过多的编译,和 svelte 不提供(或几乎没有)运行时不同,sfcjs 在运行时前置了一个很小的响应式内核框架,所有组件的编译结果代码实质上是依赖于这个内核框架的。而这个内核框架在设计 API 的时候,完全是为了搭配编译过程设计,所以,编译过程,就是把源代码通过匹配、token 化等处理,做了代码转化,甚至都没有用到 AST 那一套。
当然,这样做,并不是为了性能,完全是为了尝试一条无 virtual dom 的道路,为了乐趣。
现代前端UI框架反思
背景
最近了解了一门新框架 alpine.js,再惊叹其简洁的同时,开始反思前端框架(特指 vue react 之类的 UI 框架),真如我们所需要的吗?如果我还在用 jquery,你或许会说我老古板,但是,网络上曾经流传一个段子,“2019年你如何启动前端开发”,nodejs, webpack, babel, cli… 各类工具充斥着我们的视野,以至于让我们开启一个前端应用开发,需要九牛二虎之力,花费大量力气去解决、配置各种编译打包工具。虽然工具给我们在工程化方面带来了很多可能性,甚至衍生出 typescript,以及前两天字节开源的 modern.js 这样的项目,但不可否认,纯粹前端魔法的乐趣,在这些工具面前逐渐被消磨了,慢慢的,前端开发,特别是在特定项目中的前端开发,编程了工具配置和框架使用的纯搬砖工作,所以面试只需要面工具和框架,就好了,有点太偷懒了。我开始疑惑,10 年前刚开始玩前端时候的乐趣和惊叹去哪里了?

我们从来都是在这条曲线上前行,在“乐趣-工程”和“严谨-魔法”这两个象限的探索也并非没有过,却基本上属于前端的异类。实际上,前端除了常见的信息流系统外,还有类似游戏、绘图等其他类应用,但它们却不在主流前端的队伍中。市面上 100 家公司招前端,有 100 家要求熟悉特定的前端框架,这使得类似 figma 或 photopea 这样的应用在国内显有遇见。
我在过去两年没事的时候,就会把玩一些框架,感受它们的奇特之处。比如 cycle.js 或者前面提到的 alpine.js,会有一些体会。随着框架技术的普及,不同的公司,可以轻轻松松出自己的框架,比如阿里的 rax,比如 taro 等等。2020 年微前端话题火了,我又开始看相关的框架,自己也造了一个 mfy,直到 webpack foundation 出来,我彻底懵了,这和 sea.js 有本质区别吗?这刺激我思考,是不是技术兜兜转转又回到了从前,或者用优雅的词描述叫“螺旋式上升”?前段时间在某乎表达了对某 v*t* 工具的看法,马上就被它的作者猛怼了两段话,我原本以为能写出这么优秀的工具的作者应该是会用技术说服人,没曾想热度大压死人,哎。。。如果说 bundless 是接下来的趋势,那我在想,为什么还要服务端去 compile 那一下呢?我们全部人都写 ESModule 的代码不就好了吗?“以前的 npm 遗留问题”,不就是用 export 包一下的事情吗?bundless 个啥?
这些略带情绪的想法,促使我思考,前端领域的种种所谓工程化、工具链,是否真正为开发人员或产品本身解决了问题,还是带来的问题更多一些?今天刚看到一个叫 livewire 的项目,以及最近接触《数据密集型应用系统设计》一书,感觉整个前端是否真的为技术系统的发展带来了什么价值,没有了前端,或者说,没有了时下那么复杂的 modern 前端,这些应用系统是不是没法设计出来,或者出来也很难用?我想答案是否定的,可以说,即使没有现在这么复杂的前端工程化,只需要利用 livewire 这类工具,就可以让后端人员独立完成大部分数据驱动的应用(类似 figma 或 photopea 这样的应用则后端无力)。这么来看,前端这些年,轰轰烈烈的发展,发展了个响?
Web 技术过时了
现在 2021 年,似乎很多 web 技术都过时了。比如基于 css 的阴影、过渡动画、圆角、栅格等等,这些具体的东西,在前端越来越少人提及,大家一开口都是 css in js,或者 styled-components,甚至现在提出来 dynamic styles 等等。几年前我们所依赖的 web 基础技术,现在好像过时了,虽然每年都有国际国内的 css 大会,但是,并不是主流,而在众多前端大会中,大家都在讨论的是低代码、工程化、跨平台开发、 设计、serverless 等等。新概念层出不穷,各类架构设计狠狠内卷,看上去一派繁荣景象,实则令人担忧。
在过去的几年里,web 前端技术确实发展了。例如 PWA、WebAssembly、WebRTC 等技术的出现,HTML5 和 CSS3 的演进,但很多技术,对于趴在框架上完成业务系统的开发者们而言,它们的出现或发展对于自己的工作几乎没有任何帮助,内心毫无波澜,甚至觉得是在乱搞飞机。与其说 web 技术式微,不如说其下沉。例如 webrtc 等技术,如果不用封装库,一般开发者根本不知道怎么用,甚至不知道有这玩意。离开了高级的封装库,一些开发者根本不知道该怎么使用,比如在 jQuery 时代,很多人不会原生的 DOM 操作,而到了 react 时代,甚至不知 DOM 为何物。
除了 web 应用之外,基于 web 技术的跨端实现也层出不穷,react native 开头,后面衍生了一大堆基于原有 web 写法的原生应用开发方式。但这类跨端方案只能写 UI,需要调用系统层组件的能力全都做不到。基于 JS 运行时的客户端,性能又不怎么样,美其名曰更少的人力做更多事,实则是用三流的人写三流的应用。
或许,不是 web 过时了,而是不带这些低劣的人和应用们一起玩了,随着 webassembly 的发展,逐渐把 web 应用转交给其他语言的开发者,让这些搞来搞去在搞各种工具链自以为是的前端开发好自为之。
没有性能,不成方圆
现在一个应用打包之后几个 M 再正常不过了。代码中充斥着 O(n2) 的多层遍历,美其名曰“先抗住再优化”,这种论调我可以理解为“功能我实现了,不到万不得已,你根本不知道我堆了一堆屎”。除非团队有明确的指标和负责任的技术领导,否则,一个项目的性能永远会失控。而这些毫不在意的性能,正在慢慢毁掉软件领域的优秀积累,一代比一代差,到最后,上个世纪的软件开发能力和素质,将被望尘莫及,最后封神,但实际上,却是一代一代堕落而至。
在数据结构和算法上欠下的债,总有一天会在重构中还回来。
All in JS 的赌徒心态
把所有东西都写在一个 js 文件里,导致代码功能混杂在一起,自以为是增加了灵活性,实际上是不知所措的愚蠢表现。
例如,市面上所有的 UI 组件库都声称自己是在统一设计语言下的产物,比如 antd 是 ant design,比如 semi design,但是从它们的官网,我完全读不出它们的 design 究竟为何物。说白了,他们是先有所谓的组件库代码,然后再来谈设计。所以,在他们的资料中,设计语言是附属品,代码,而且是特定条件下的代码才是主体。
真正的 UI 组件库,一定是让使用者先了解设计,再有通用的 css,最后才是各种框架的封装库,而框架的封装应该是可远的,而不是主体。本末倒置是这个时代,不单单是前端领域,的核心竞争力。就像前几天某大厂买星项目一样,为了完成 kpi 而毫无敬畏之心,这样的公司,你能肃然起敬?
抛弃 css 成为前端乐此不疲的事,说明前端(或者整个行业)越来越不在乎(或者说没有话语权)应用的设计与性能的平衡。说白了,就是懒。
类似 styled-components 这类方案的流行,本质上就是牺牲性能和合理组织的偷懒行为,因为你可以把样式用 js 来写,从而不用去思考写东西该怎么去实现,其他交给工具,不管是编译时,还是运行时。
结语
近几年这种前端发展的风气,反过来说明前端的问题在于天花板低(门槛也低),就和一些低门槛没有利润的行业一样,看上去琳琅满目,实际上一地鸡毛。而且,由于惯性,这种局面基本上是不可能打破了,让人感到无比凄凉。不过,好在越来越多的后端技术栈开始去兼容前端,这也就意味着未来的应用形态也会慢慢重回统一,在一个架构中去实现,而非前后端分离。而且,我相信这种前后端一致性,才是未来的趋势。
-
前端确实很多时候都是在折腾,圈地自萌,但这也是前端社区的一部分,让前端生态变得相当繁荣。但从另一个角度看,很多东西不做也不知道有没有用。#1101 rxliuli 2021-11-04 14:32
-
另外 vite 挺好用的,比它的前辈 snowpack 兼容性好得多#1102 回复给#1101 rxliuli 2021-11-04 14:59
-
楼主用心思考了,说得很好,切中行业弊端。alpine.js是一个非常优秀的框架,感兴趣的话可以了解下一个比它设计更加简单易用的前端框架:https://daggerjs.org,编码方式十分贴近原生js,同时又提供了数据绑定和监听功能。非常赞。#1250 隔壁老王 2022-11-11 19:21
SSO统一用户管理系统设计
我以前在《同一公司下多个产品共享用户的权限设计系统》和《独立产品权限体系设计》两篇文章中讨论过用户权限系统,但是,两篇文章更多是从工作经验角度出发,今天读到一片硕士论文,从理论层面探讨了这一设计的可能性。
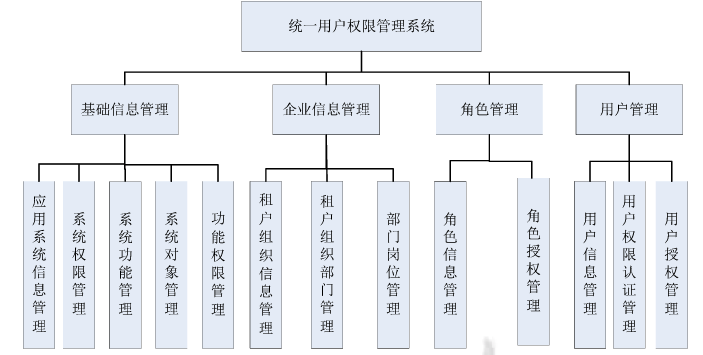
来源 https://www.docin.com/p-1419313536.html
而且这篇文章还给出了具体的数据库表设计:

从上图可以看出,该论文的作者,和我考虑的是一致的。SSO是,你的多个产品,使用统一的用户认证、权限体系。这和我前面第一篇文章提到的方式是一致的。而且,该论文更加坚定了我把应用的权限也设计到整个用户权限体系中统一设计的思路。
-
赞#1103 东 2021-11-04 22:18
前端框架发展脉络与趋势预测
前两天做了一个视频,聊了前端框架的话题,包括上一期robust也聊了前端框架的话题。对前端框架的发展的梳理,我觉得已经做的不错了。
本文再简单总结一下。

我把整个前端框架的发展,分为3个大阶段,其中黄色的框是jquery为王的阶段,典型框架有angularjs, backbone等,这一阶段的框架实际上也是数据驱动,比如angularjs和backbone,所以,我们不能用数据驱动来划分它们和后来的react、vue的区别。
绿色的框这一阶段有两个特征,一个是react、vue大行其道,另一个是类似babel、webpack这样的工具是开发工作的基础。在16、17年时,流行起来一句话,叫“学不动了”,意思是前端发展太快,冒出来很多东西,其中包括了对新框架的谈笑。但是,从上图可以看出,其实在这一阶段(上图中没有列举出类似cyclejs这类框架),并没有像上一个阶段一样那么多框架林立,而是被react、vue、angular统治,所以,有的时候,我们的感觉和实际的情况有一些差别。和上一个阶段不同,这一个阶段react作为主导框架,追求的是某种极客层面的快发体验,特别是react,在runtime上探索出了时间切片等。但是,react持续在runtime上下功夫,或许会错过下一个阶段。
蓝色框是第三个阶段,也是我们当下正所处的阶段。这一阶段的特征是基于编译的框架开始大行其道。以svelte为典型,vue3跟进,框架们都在想办法,让开发者在源码中使用比较特殊且体验更好的语法来写组件,然后通过编译器,把这一写法转化为运行时放到浏览器中跑。甚至,像alpine这类框架,直接在运行时进行解析和运行。这种基于编译的模式(实际上,angular2+的模板语法也是这种模式),可能是接下来这段时间前端框架的主要方式。
windows10 C盘后面有一个恢复分区,无法扩展C盘的解决办法
今天公司给装了一个新的500G的盘,导致我电脑瞬间多出很大一块空间。而看着越来越小的C盘,想到我以前也有拿D盘补C盘的操作,这次我索性把整个D盘干掉,来一个500G的C盘,岂不是爽歪歪。网上搜索了一下方法,windows自带的磁盘管理工具就可以满足,于是开开心心的打开磁盘管理,把D盘删了,然后按照指示,右键C盘扩展卷,然后,M的,这个选项是灰色的,用不了……
这么尴尬吗?我一看,在C盘后面还有一个很小的分区,写着“恢复分区”,大概是系统故障的时候跑一个特殊的小系统来做引导的吧。这个我没意见,但是你为啥插在C盘和D盘之间??磁盘管理工具又不能把它和D盘调换个位置。难道就这么卡住了?
又搜索了一下,https://www.diskgenius.cn/ 这个工具可以调整磁盘,于是下载下来试试。折腾了一下,发现可以采用一种变通的方法来处理。它可以调整磁盘大小,而且很诡异的是,调整磁盘大小时使用拖拽的形式,两边都可以拖,这就可以直接通过这个能力,把哪个“恢复分区”搞到最后面,把空出来没有的部分和C盘连在一起。

通过上面这个地方调整“恢复分区”大小,进入之后可以看到如下界面:

通过拖动的方式,把这个分区搞到最后面去,这样把空的空间留了下来。
这样愉快的调整完“恢复分区”之后,我想,继续用这个软件调整C盘的大小,结果,同样的方法提示这个磁盘加密,没法搞。难道没办法了?
这时,我又突然想到,回磁盘管理工具试试,在磁盘管理工具中使用右键扩展卷功能,竟然成功了。于是,我就有了一个接近500G的C盘,爽歪歪~
-
这样恢复分区的大小会改变吗,调整完以后会不会出问题呢#1126 历史进程 2021-12-05 15:40
-
不会,没什么影响,就是你自己要做好数据备份先#1127 回复给#1126 否子戈 2021-12-05 22:05
-
太感谢了。弄好了!#1156 回复给#1127 路兹 2022-01-14 10:33
-
太感谢了,非常管用~~特别是中间说到的那个:磁盘大小调整时可以拖拽,刚开始还不敢拉,后边会拉了果然很好玩,果然诡异哈哈哈#1191 吾 2022-05-09 07:11
-
感谢感谢#1205 zain 2022-06-28 14:35
-
太对了哥,事情办成了大的小的全保住了。完美!你TN就是个天才!
-
你是我的神#1254 zbvb 2022-11-22 22:16
-
夸张了#1255 回复给#1254 否子戈 2022-11-22 22:26
-
试了一下,成功了……真是个莫名其妙的方法🤣#1263 嘟噜噜 2022-12-16 20:11

