AI看片,Nano Banana最令人欣慰的能力,远不止于P图那么简单
之所以将代码编辑器从vscode切换为trae,是因为最近vscode越来越卡,经过一番搜索之后,得知是微软在后台启动了一个报告进程,这个常驻进程会消耗大量的内存和计算资源,虽然可以关掉,但是copilot以及很多扩展无法拒绝,即使勉强使用,还是会越来越卡。而且vscode用国内的编程助手(我用的灵码),会在后台启进程,在活动查看器发现开销非常大,也是拖慢编辑器的原因之一。而现在的trae性能非常好,它自带了AI Agent,可以连MCP,不需要额外挂扩展,因此节省额外的开销,所以,现在赶紧用起来性能就非常好。当然,后续它会不会像剪映一样搞收费,或者功能越加越多也变慢,这个先不管咯,等到那时,在物色一个新编辑器就好了。
即使强如google,也在Safari的视频播放上折戟沉沙
前几天我写了《Safari中无法播放视频,“Failed to load resource: 插件处理的载入” 或 “尝试载入资源时发生错误。”》一文,本来是记录自己在开发过程中遇到的问题和解决过程。然而,今天我在访问gemini特设的veo3页面时,发现视频也都无法播放。在访问replicate的详情页,也遇到了相同问题。没想到,就连google、replicate这样的大公司,竟然也都不在safari上做测试。
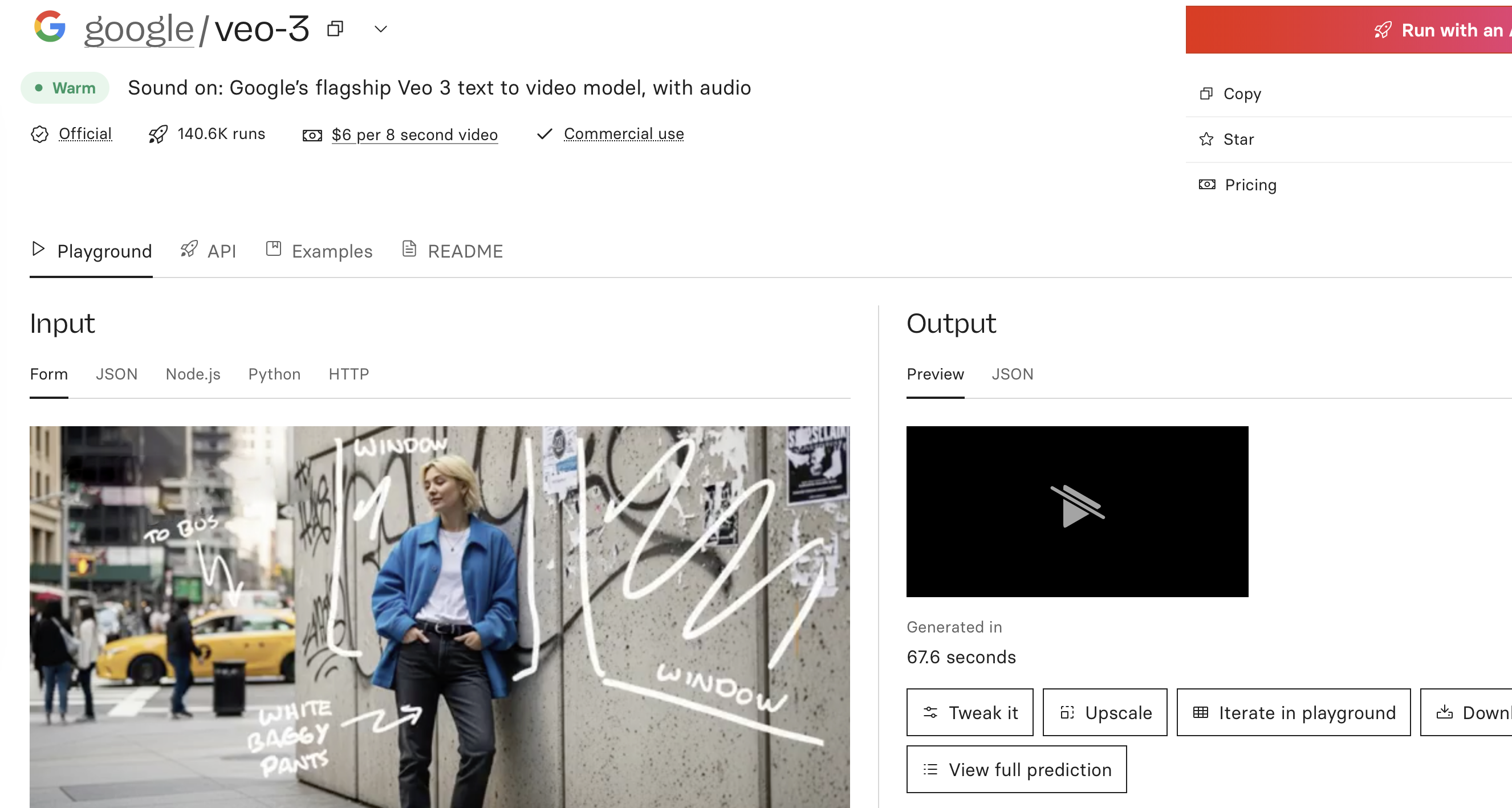
右侧这个视频无法播放的界面,是safari标志性的“侮辱”信号。

在上一篇文章中,其实我已经详细阐述了造成这个问题的原因,是safari特殊的视频资源读取逻辑。它严格按照Range Request的模式来请求视频资源,而且同时,它会在第一个请求时读取0-1 bytes来得到完整长度,而且立马丢掉(请求呈红色),然后再重新计算后严格按照Range Request来读取视频的buffer进行播放。
基于Range来读取视频数据虽然理想丰满,但是现实骨感。我打开网络面板,找到了卡住的Range请求,如下:

在这一个请求中,后端要返回14.2M的数据包,这……也太坑了吧,既然你都用Range请求了,为啥不请求一个只有1M的Range呢?而Range包的大小,则是由浏览器(也就是safari)发出的Range请求头决定的,后端也无法决定。
因此,最后其实不是google工程师没有考虑到,而是safari坑。
随后,我将默认浏览器切换成了chrome。
我的mackbook pro是2017年底去香港苹果店买的,到今天已经用了8年了,时间如此之快,恍如昨天。虽然是2017年的电脑,但是现在用来还是很正常,不会有太多的卡顿。不足之处有两点,一是intel的芯片拖后腿,比起现在的M芯片,不仅耗电厉害,而且由于时代久远,稍微跑一点吃计算的程序就风扇呼呼响,开始卡;二是电池,得一直插着电源。我还是很喜欢这台笔记本的,不过电池问题一直是给心头结,没法带着电脑出去装X,有点失望。在纠结很久之后,终于在网上下单了一组电池,今早自己动手给换了,虽然有点笨手笨脚,但是靠着狗屎运没有出一点岔子,现在已经非常愉快的丢开电源用了,内心还是挺喜悦的。芯片没法改,就不计较了,毕竟我现在一直在mini上工作,这台电脑就是偶尔应急或者手持来装的,感觉还能再战10年。
“什么是Agent”的终极解释
2025年的今天,我们终于可以给出Agent的终极定义,即“智能化自动化的应用程序或服务”。
首先,Agent是应用或服务,而非AI。虽然,我们现在默认AI是驱动Agent的基础,但是,Agent不只意味着AI,那些对AI(特别是LLM)简单套壳的应用不是Agent。Agent本身依赖AI,但不必须依赖特定AI,AI只是它的一个组件,且可以随时切换为更高智能的AI。Agent本质上是应用,就像Java程序以来数据库服务一样,Agent依赖AI,但不参与AI本身的开发。
其次,Agent具有自主性,即无需人工干预自主实现目标。与以往应用程序需要程序员撰写精确逻辑的代码不同,Agent应用中,程序员不实现业务逻辑本身,而是实现逻辑的调度,通过这个调度让程序自动选择业务逻辑节点去执行,如果在Agent框架的加持下,程序员甚至不需要实现这个调度,而只需要实现业务逻辑的节点,应用启动后,每个业务节点在什么时候被执行,完全是由Agent根据用户的输入和当前的状态来决定。
最后,Agent具有单一通识能力,即一个Agent就可以帮用户解决所有问题,包括不同专业领域、不同业务场景、不同目标需求。比如,用户既可以让Agent为自己下一个外卖单(生活场景),也可以让它帮自己完成数据统计(工作场景)。虽然目前来说,市面上的Agent大部分还是倾向于专业能力,例如cursor专注于编程,但是这主要是发展程度不够决定的,未来,cursor这样的工具一定会被淘汰。
历经2个月,我的第一款真正意义上的AI产品上线
大家好,这两个月我完成了一款产品——Videa。虽然过去一年,我做了很多东西,但是部分是套壳,部分是把别人的想法做出来,真正我一直想做的,其实是一款借助AI创作短视频的产品。现在,我把它做出来了。
下面,我将聊一聊我做这款产品的想法。
生成模型不是产品
我们现在已经有很多图片、视频的生成模型,图片领域有最早的SD、Flux,现在又有了recraft、ideogram等,而且国产的kolors等也获得好评,这几天flux kontext的发布再次震撼了业界;视频生成领域除了最早的Gen2、Pika、PixVerse,到Sora、Voe3,以及国内的混元、可灵、海螺、通义,都已经非常成熟。在如此激烈的生成模型竞争中,我发现,创作者要完成自己的短视频制作,仍然很难。
视频生成模型的厂商们在自家App中提供的视频生成功能,虽然在它们的演示中表现的非常抢眼,然而在实际使用中,普通用户很难一次性得到符合预期的结果。更重要的是,创作这件事本身,是有非常复杂的程序和时间因素的。而生成模型只能创建短时间的随机的视频,通过prompt是无法真正做到按预期生成视频的。
市面上出现了一些Agent模式的产品,例如skyreels,通过Agent来规划和制作长视频。然而其随机性大大增加,如果没有正确识别用户的创作意图,工具甚至会产出与用户意图背道而驰的作品。
总而言之,生成模型虽然好,但是只能解决从0到1的问题,而无法解决1到100的问题。模型本身很难直接成为产品,作为底层的支撑,在模型之上构建真正符合实际使用场景的产品,则是我的想法。
讲好故事而非视觉艺术
在得知AI生成视频的能力已经非常强的时候,我们跃跃欲试的心终于按捺不住,开始尝试将自己积压已久的想法制作成短视频。然而,很快我们就会发现,我们把事情想得过于简单,而工具们又把问题想得太复杂。实际上,我们的核心痛点,是想将我们内心的“故事”用短视频的形式表达出来,这种欲而不得的焦虑,促使我们对现有的AI工具产生质疑。
制作视频本身是一项技术的工作,优秀的视频剪辑,让视频非常出彩,专业的视频制作让一个博主、品牌具有强烈的人设。但是,作为普通人,很难在不以视频为自身主业的情况下,制作出令人称赞的视觉效果。那么,我们能否退而求其次,用朴素的视频,也可以传递我们想要表达的内容呢?
我的理解是,对于绝大多数有此冲动的人们而言,
短视频的本质是讲好一个故事,而非纷繁复杂的视觉艺术。
制作视频来讲述我们内心的故事,并不一定要让我们的视频具有多么高级的视觉艺术,我们都不是导演,拍不出电影级的视觉盛宴。我们的短视频,只是一个普普通通讲故事的人。这是一种表达欲的延伸,是互联网原始的初衷,是网络冲浪中敢于表达自身的内在需求。
在过去很长很长一段时间,文字或更高级的图文内容,充分展示了人们的内心世界。但在多媒体时代,这种表达,被媒体制作的技术要求所约束,以至于让网络平台成为某些人独有的话语权。
我们这个世界需要故事,而现在普通人通过AI,讲好自己的故事已经成为可能。我们绝大部分情况下,不会尝试去制作电影级的视觉效果,我们会用最朴素的节奏和配音,来把我们脑海中的故事,一点点的揉捏出视频的形。这个故事,可以是关于一个天真孩子看到神奇现象时脑海中的奇妙历险,可以是一个经过生活打磨后的中年打工人对年轻人的寄语,可以是科幻爱好者对未来星际旅行的人类空间城的设想,可以是策划人寻找与用户情感共鸣的广告设计,可以是文人们对历史回音里的控诉的无声传递。我们本质上想要短视频把90%的力量用在讲好故事,剩下的10%留给视觉和技巧带来的吸引力。
创作者们的工作流
在生成模型的基础上,创作者们构建了一套行之有效的工作流。总体而言,可以总结为如下:
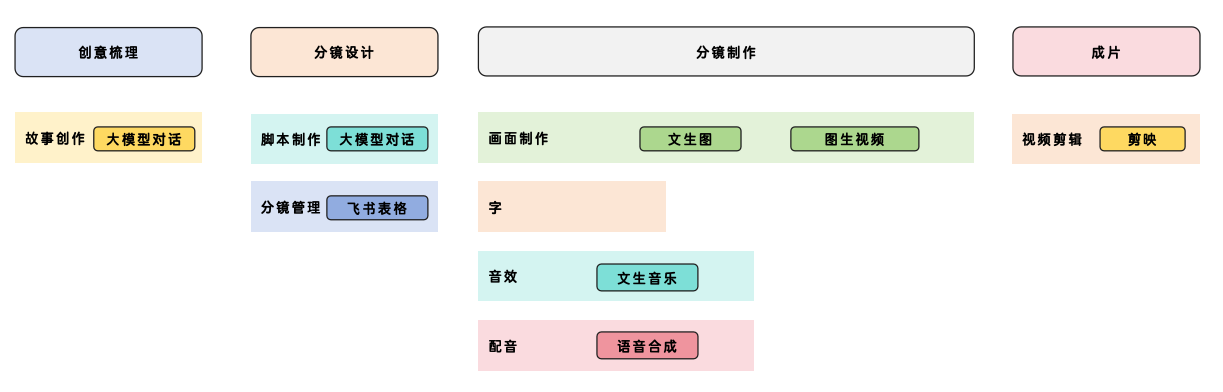
在抛开需要在视频出现人物,并且保持人物一致性的情况下,这套工作流让创作者们可以利用AI工具,创作尽可能还原自身意图的短视频。而且,这套工作流的厉害之处在于,如果有足够的毅力,甚至可以制作出一部几十分钟的中长片,甚至电影级时长也不是没可能,毕竟即使电影的后期,也需要几个月的制作时间。
而对于AI工具的选择,则不同的创作者倾向不同,文生图有直接在本地部署Flux的,也有在即梦充会员的,音乐生成有网易云和qq音乐的对应平台,也可以去国外的suno等。总之,不同的工具选择,并不影响这一套工作流的具体实施。而这种灵活的组织模式,也可以让创作者们在实现创作的同时,尽可能压缩自己的成本。
化无形为有形
如何做出一款产品,将已知的概念,落地为切实的存在呢?我只抓住一个点,即前文所说的“短视频的本质是讲好一个故事”。从技术层面,短视频的制作中有一个非常重要的要素,就是“时间”,即视频这种形式与其它载体形式的最大区别就是在时间延续上的连贯性,画面的连贯性、声音的连贯性、意境情绪的连贯性。让“故事”在“时间”上行游,就是Vdiea这款产品的原始创意。
说的人话些,Videa的界面第一眼看上去就像一个视频编辑器。它由多个区域组成,其中最占视野的就是中间的视频画布区域和底下的轨道控制区域,轨道控制区域与几乎所有的视频编辑器大致相同。不同的地方在于:
- Videa没有其它视频编辑器所拥有的素材控制
- 没有其它视频编辑器的特效和转场
- 没有其它视频编辑器的超强剪辑能力
它不是一个编辑工具,不是一个编辑工具,不是一个编辑工具!在我看来,它本质上是一个管理工具,你可以直接在Videa中完成上述工作流的全部内容,包括但不限于:
- 与AI对话来进行故事创作、脚本制作等
- 通过文生图、文生视频、图转视频等来获得画面素材
- 通过语音合成来创建配音
- 无需分镜管理,因为它主动提供了“分镜”类型的轨道
- 集成了“剧本”类型轨道来获得连续的文案和配音
对于“讲故事”的创作者们而言,视频编辑器上的众多特效特技我们用不上,这种时间轴轨道的形式,仅仅是为了以“时间”的维度来管理我们的分镜和素材,我们会更多的将精力放在我们的故事创作上,用故事的内核(而非视频外在)打动我们的读者/观众,用朴素的方式,传递我们内心的声音。
结束语
从故事出发,一点一点地构砌那个属于我们自己的讲述,一帧一帧画面的跳动,干净而朴素,故事娓娓道来,然后结束。作为一个独立开发者,我有很多故事可以讲,而Videa就像一位老朋友,它慢慢的倾听,并把我的故事用短视频的方式,呈现给每一个恰到好处相遇的人。
AI让原本需要很专业才能做到的事,如今成为每一个普通人手到擒来的。Videa默认配置下可以完全免费使用,当免费的AI能力不能满足时,你可以通过购买资源包来升级,资源包是按量扣费,而且Fuu AI全站可用。无需邀请码。电脑上打开使用:
在使用过程中,如果你遇到什么问题,或者发现有什么地方还做得不够好,你可以在下方留言,让我可以知道。也可以点击下面阅读原文,分享到电脑上打开后收藏,与我保持长期互动,不放过你的每一个想法。关注本公众号,获取更多使用技巧。
好了,就到这里,祝你愉快😀
-
邮箱登录收不到验证码#1359 卡布 2025-06-05 10:24
-
关注一下垃圾邮箱哦,邮箱服务是国外的,可能比较慢#1362 回复给#1359 否子戈 2025-06-13 19:25
兜兜转转,弃用edge,用回chrome
最早从chrome换到edge的原因,是因为chrome越来越吃内存,同时,账号同步功能受到限制,而edge使用了相同内核,微软的账号又没有受到限制。但随着时间的推移,已经持续用了几年edge了,发现它越来越重,不仅版本跟不上chrome,而且账号问题反而影响使用——当正常使用时,由于网络问题,账号没有连上,它竟然会弹出一个强制性的弹窗盖在原有窗口上,导致原有窗口关不掉,虽然这个弹窗可以直接关闭,但是过一会儿又会弹出来,真的是太恶心。包括它新加的AI功能,统统都用不上。对于我而言,浏览器的重要功能是要调试方便,而chrome就像初恋一样,又成了我的心头好。
facebook生产有技术深度的垃圾
facebook从10年前开始在技术领域作出了非常大的贡献,在前端领域,出现了react,之后又出现了LLaMA。然而,随着时间的流逝,facebook这家公司正在衰亡,伴随而来的,是以前的一些项目的维护人员逐渐流失,因为无法维护,导致很多问题。今天要指出的,是两个非常有技术深度的,却没人维护的,让我非常后悔采用的两个东西:faiss和rocksdb。
我在几年前采取了这两个工具,但是现在,这两个工具成为我的项目毒瘤。我现在每次在一台新机器上执行yarn,都感到心惊肉跳,这两个东西都需要编译,而现在总是无法正常编译。对了,yarn也是facebook的东西。在用了这么多年之后,我不得不因为这两个没人理会的垃圾寻找出路,rocksdb我使用leveldb替代,要改代码。faiss-node我自己fork了一个,发了一个新包faiss-node-napi8,如果你也在用faiss-node,你可以在package.json中这样写:
... "faiss-node": "npm:faiss-node-napi8@^0.5.1", ...
虽然这是过渡方案,但是起码能跑起来。
这件事让我开始反思,我们在做技术选型的时候,应该要考虑到这种问题。随着nodejs、webpack、vite等基础设施的升级,很多以前的技术实现会出现不兼容的情况,而如果此时项目无人维护,而你的项目又重度依赖,那么就非常非常痛苦。你看,即便是强如facebook这样的大公司,也有很多当时有技术创新,却最后沦落为无人理睬的垃圾的项目。那么,就更无法对个人的项目库更加信任。因此,我们应该挑选那种社区比较大的开源项目作为技术选型,只有当社区足够大,才能支持项目可以持续维护。

