如何彻底杀死child_process.exec子进程
最近在尝试使用child_process来跑一些子任务时,调用了yarn的命令来启动一个服务,但是发现怎么调接口都无法kill,子任务还在跑。后来灵光一闪,spawn在运行yarn命令的时候,是不是再在它的上面包了一层。顺藤摸瓜,发现网上也有同样的说法。原来,spawn在运行子命令的时候,首先要选一个shell来跑,默认是使用sh,也可以使用bash或cmd.exe,这个需要在调用spawn的时候传入它的第三个参数里面的配置来确定。这也就意味着,child.pid返回的是调用sh的进程,而在sh里面执行命令产生的子进程的pid不是默认返回的child.pid,而且,在sh里面,可能还会再起其他的子进程,也就是说,实际上,我们看似只跑了一个spawn,但是实际上它可能起了一堆子进程,而我们想要kill的目标进程只是这一堆里面的其中一个。
默认情况下,我们通过ctrl+c可以退出process,而nodejs会把SIGINI传递给所有子进程,进而关闭全部子进程。但是,如果我们自己手动调用child.kill来杀死子进程,就会导致只杀掉了一个,而且可能是最不重要的(因为跑的是sh)。
有了这个前置知识,那么问题就比较好解决了。我们只要封装一个自己的kill函数,传入child.pid,然后把其全部子进程杀掉即可。具体做法可以参考ps-tree里面的示例代码。在我们自己实现的时候,也可以直接引用ps-tree这个包来把所有子进程pid查出来,然后再通过exec遍历它们执行一个kill -9 {pid}即可。如此就可以真正把子进程杀掉了。
时间沉淀,不问世人问自己
今天发现,当下非常火的视频剪辑软件剪映是有深圳市脸萌科技有限公司开发的,“脸萌”是多年前突然爆火的一款APP,在那段时间,几乎所有人都将自己的头像换成了用脸萌软件组合而成的头像。我至今仍在用的开通头像也是用脸萌生成的。虽然脸萌不是最早的捏人软件,但是确实那时最简单有趣的。不过,在爆火之后,很快这款app就退烧了。相信在互联网流速这么快的时代,很少有人还记得这款app,除了像我这种还在使用曾经制作的卡通头像的人以外。后来,我在一些视频网站看到媒体对它创始人的采访,他说到,随着app退烧,公司的业务也开始转型,可能很大程度上会作为技术服务公司,说的难听一点,就是外包。本质上,脸萌app没有盈利模式,所以逐渐褪去色彩也是很正常的,只是作为一家公司,如何在爆款过期后持续运营,是很难的一件事。不少公司或团队不断探索新的爆款,采用低成本高数量输出,博一个中奖概率。但是,我相信脸萌的团队在这些年的沉寂中,没有这走条路,或者说想走但最终条件不足,选择了技术沉淀的道路。我能想象到他们经历了公司从几个人到上百人的发展过程中,经历很多的消耗、迷茫、懊恼等等,但是,我也相信他们在不断的为其他项目提供技术支持的同时,不断的总结了自己的技术经验,形成了一套不错的技术护城河,最终通过技术获得字节这样头部公司的青睐。出品剪映,可能仅仅是因为他们拥有这样的技术沉淀,比别人走的早走的快,现在能把产品做的这么好,算是对这些年默默无声的回报。我相信,就两款软件而已,剪映更有价值,无论是使用的场景,还是未来的商业价值,然而,我们却并没有看到他们团队像曾经一样作为明星团队到处接受采访。这或许就是成长,同样一家公司,不同时期,不同阅历,不同心境。
windows11 资源管理器 该文件没有与之关联的应用来执行该操作
关于win11任务栏的文件资源管理器出现打不开,没有与之关联的应用…..,可以尝试以下方法,亲测有用。
新建txt文档,将以下代码复制进去。
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\Folder]
@="Folder"
"ContentViewModeForBrowse"="prop:~System.ItemNameDisplay;~System.LayoutPattern.PlaceHolder;~System.LayoutPattern.PlaceHolder;~System.LayoutPattern.PlaceHolder;System.DateModified"
"ContentViewModeForSearch"="prop:~System.ItemNameDisplay;System.DateModified;~System.ItemFolderPathDisplay"
"ContentViewModeLayoutPatternForBrowse"="delta"
"ContentViewModeLayoutPatternForSearch"="alpha"
"EditFlags"=hex:d2,03,00,00
"FullDetails"="prop:System.PropGroup.Description;System.ItemNameDisplay;System.ItemTypeText;System.Size;System.HomeGroupSharingStatus"
"NoRecentDocs"=""
"ThumbnailCutoff"=dword:00000000
"TileInfo"="prop:System.Title;System.HomeGroupSharingStatus"
[HKEY_CLASSES_ROOT\Folder\DefaultIcon]
@=hex(2):25,00,53,00,79,00,73,00,74,00,65,00,6d,00,52,00,6f,00,6f,00,74,00,25,\
00,5c,00,53,00,79,00,73,00,74,00,65,00,6d,00,33,00,32,00,5c,00,73,00,68,00,\
65,00,6c,00,6c,00,33,00,32,00,2e,00,64,00,6c,00,6c,00,2c,00,33,00,00,00
[HKEY_CLASSES_ROOT\Folder\shell\explore]
"LaunchExplorerFlags"=dword:00000018
"MultiSelectModel"="Document"
"ProgrammaticAccessOnly"=""
[HKEY_CLASSES_ROOT\Folder\shell\explore\command]
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\open]
"MultiSelectModel"="Document"
"LegacyDisable"=-
[HKEY_CLASSES_ROOT\Folder\shell\open\command]
@=hex(2):25,00,53,00,79,00,73,00,74,00,65,00,6d,00,52,00,6f,00,6f,00,74,00,25,\
00,5c,00,45,00,78,00,70,00,6c,00,6f,00,72,00,65,00,72,00,2e,00,65,00,78,00,\
65,00,00,00
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\opennewprocess]
"ExplorerHost"="{ceff45ee-c862-41de-aee2-a022c81eda92}"
"Extended"=""
"LaunchExplorerFlags"=dword:00000003
"MUIVerb"="@shell32.dll,-8518"
"MultiSelectModel"="Document"
"LegacyDisable"=-
[HKEY_CLASSES_ROOT\Folder\shell\opennewprocess\command]
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\opennewwindow]
"LaunchExplorerFlags"=dword:00000001
"MUIVerb"="@windows.storage.dll,-8517"
"MultiSelectModel"="Document"
"OnlyInBrowserWindow"=""
"LegacyDisable"=-
[HKEY_CLASSES_ROOT\Folder\shell\opennewwindow\command]
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\pintohome]
"AppliesTo"="System.ParsingName:<>\"::{679f85cb-0220-4080-b29b-5540cc05aab6}\" AND System.ParsingName:<>\"::{645FF040-5081-101B-9F08-00AA002F954E}\" AND System.IsFolder:=System.StructuredQueryType.Boolean#True"
"MUIVerb"="@shell32.dll,-51377"
[HKEY_CLASSES_ROOT\Folder\shell\pintohome\command]
"DelegateExecute"="{b455f46e-e4af-4035-b0a4-cf18d2f6f28e}"
[HKEY_CLASSES_ROOT\Folder\ShellNew]
"Directory"=""
"IconPath"=hex(2):25,00,53,00,79,00,73,00,74,00,65,00,6d,00,52,00,6f,00,6f,00,\
74,00,25,00,5c,00,73,00,79,00,73,00,74,00,65,00,6d,00,33,00,32,00,5c,00,73,\
00,68,00,65,00,6c,00,6c,00,33,00,32,00,2e,00,64,00,6c,00,6c,00,2c,00,33,00,\
00,00
"ItemName"="@shell32.dll,-30396"
"MenuText"="@shell32.dll,-30317"
"NonLFNFileSpec"="@shell32.dll,-30319"
[HKEY_CLASSES_ROOT\Folder\ShellNew\Config]
"AllDrives"=""
"IsFolder"=""
"NoExtension"=""
保存文档到桌面,修改文档名称为folder fix w11,后缀reg格式。
双击reg文件,点击是,添加到注册表中。
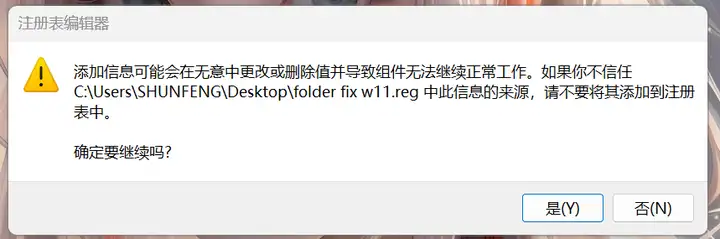
另外win10系统也可以将文件名称改为w10,其他步骤相同。
PM2 + Nginx 502 Bad Gateway
用PM2起node服务,再nginx反向代理,结果遇到502 Bad Gateway问题。我自己猜测,502就是node端报错或者什么原因,导致代理没有找到目标。后来研究很久之后,发现是PM2 –watch模式的原因。
当PM2开启–watch之后,目录下有文件变动的情况下,会重启服务,这就会导致会有短暂的空窗期,这期间nginx反向代理找不到目标,九会报502.
解决办法是将数据库、日志等会被操作的文件移除PM2对应的项目目录,确保项目下的文件,在运行期间不会被代码修改。

领域驱动设计实践
何为前端数据治理?
在5年前,我凭借一身胆,硬生生写完一个电子商务微商城,一个订餐系统,一个会议室抢订系统,一个基于ajax的内容管理后台,那时候的前端工具莫过于jQuery和sea.js,但总体而言,这些系统的实现只要耐心和时间都够,也能写出来。但随着时间流逝,我先后进入了国际知名基金评级机构Morningstar和国内社交王国腾讯,逐渐和业务系统打上了深刻的交道。于是慢慢发现,早年自己所完成的引以为傲的作品,实际上没有什么内在的干货,仅仅是可用而已,而谈不上优雅。究其本源,在那个年代,除了前端业界没有特别丰富的工具之外,还有一个重要的原因,即我自身因为经验单薄,对设计模式也好,对业务系统的抽象能力也好,都无法让我站在更高的设计层面去看待所开发的具体业务。
“业务”这个词在我这些年的开发生涯中是一个核心词汇。我从业虽然只有5年,但因为我是硕士毕业,加上本科期间的实习、自己倒腾,我的开发经验也已超过10年光景。这些年中,前期我几乎没有关注“业务”这个词,那个阶段我主要关注“功能”,对照着交互稿或设计稿,根据需求口述实现功能为主。以功能为导向的前端开发和以业务为导向的前端开发是不同的。前者关注快速实现,快速迭代,满足用户需要,提升用户体验,多面向toC产品。而后者关注准确性,稳定性,满足客户需要,保证逻辑没有丝毫差错,多面向toB产品,甚至是内部系统。业务开发也讲究快速迭代,但是和面向C端用户的产品迭代不同,B端产品的迭代之快,恨不得早上的需求中午就要给到。但是,这种极速迭代并不会持续的均匀的散布在开发周期中,很多情况下它是随机的突发的。除了极速迭代,业务开发的另一个特点是多迭代并行,在我自己的经历中,同一时间基本上都有2个以上任务同时进行,只有较少的时间只有1个任务,这种情况下相对比较闲适,会做一些技术建设,而最多情况下,我一周内有4个迭代并行推进,并且在这一周内,发布了3个迭代的成果。
面对业务系统开发的特性,慢慢的,我总结出一些规律。其中包括,“性能并不那么重要”“准确性高于一切”“功能可以先上,后续再优化”等等一系列在其他领域开发中,令人不可思议的违背“常理”的规律。
真的违背常理吗?其实并不是,面对围绕“业务”进行开发的系统,很多在C端大众性产品中看似成熟的经验,现在或许不适用,或者并不那么急迫。例如,大众性产品强调“秒开”这种体验,虽说在业务性产品中做到这一点是很不错,但是如果实在做不到,只要保证数据准确,业务逻辑准确,慢一点点也并无大碍。再例如,某些产品会遇到流量喷发,比如双十一这种场景,但是在业务性系统中,这种场景也基本不会遇到,虽说在某些时刻确实也会给服务器带来一些压力,比如周一业务方要开会,业务团队成员着急录入数据时,会有一小段时间的流量高峰,但这种压力基本上不足以摧毁系统。只有当业务系统需要对接业务团队外部人员时,才需要提供一个能够承受特大流量的服务,但实际上,这种场景,相当于在业务系统的基础上,部署一个大众性产品服务,也就是基于B端产品的C端产品,所以,理念上已经横跨了两个领域,不能因此而否定前面对B端产品的结论。
“业务“不是一个简单的词汇
如果你长时间在开发针对大众的C端产品,你可能对“业务”这个词不是很理解。不过,我举一些例子你就能明白。DNSPod是腾讯云旗下的一款DNS服务产品,最初,它围绕DNS这个业务,完成前后端的一系列技术建设,以支持业务的稳定可靠,从而才能实现最终的商业价值,如今已经在业务层面全面铺开,你或许可以猜一猜现在DNSPod为腾讯云带来多少收入?CODING是国内一家知名的围绕研发生命周期管理为业务的产品,它需要涉及开发体验、效能、管理、安全等等方面的技术,而围绕这一业务出发,它需要不断探索和优化产品内的细节,现在,它已经被腾讯收购,成为一站式软件研发管理业务的赢家。
如果非要再直白一点区分业务型产品和功能型产品,我认为可以这么解释,前者是持续合作的企业级产品,后者是一锤子买卖的普众型产品。虽然两者都能赚钱,但是赚钱方式不同,前者是跪着喊客户爸爸,然后挣很多钱;后者是利用自己的资源、体验吸引用户使用,然后搞各种增值服务策略,想方设法让用户掏钱,而且单价不会很高。前者开张吃三年,吃完三年又三年;后者靠走量一波达到巅峰,然后结束找下一波,只有形成垄断的巨头可以在部分产品上持续盈利。2018年开始,腾讯全面拥抱B端G端客户,并且随后小马哥提出“产业互联网”概念,2019年,腾讯云收入过百亿,我也领到了刻有腾讯云百亿纪念文字的纪念手机。

业务型产品的盈利能力和C端产品孰高孰低,在产业互联网时代尚无定论,但不可否认,业务型产品的潜力已经完全暴露,入场B端产品的企业越来越多,在2019年之前,字节跳动以今日头条、抖音、懂车帝等大众消费型产品崛起,在2020年,飞书趁疫情期间远程办公和协同工作需求的增加,也快速崛起,和阿里钉钉、腾讯企业微信形成新的鼎立之势。
以上这些,是我在长时间和“业务”开发打交道过程中的体会。也是我打算写一系列文章来探讨有关前端数据治理的动因。
业务准确性和数据
虽然在前文我没有提到“数据治理”这个词,但是我反复强调“准确性”,实际上,这个词是关键,是迫使我思考前端数据治理的核心原因。但是,在开始探讨前端数据治理的内容之前,我必须将为什么要去探讨前端数据治理的现实原因讲清楚。正是因为业务开发的特性,让我们不得不更多的思考数据,特别是前端这个弱环境(动态赋值、弱类型、对象引用、自动垃圾回收等)下,怎么确保“准确性”。
我刚开始进入Morningstar进行业务系统开发的时候,仍然以功能开发的思维开始上手,结果碰了一鼻子灰。首先,不懂业务场景,会对为什么要把数据设计成这种结构产生疑惑,觉得不符合道理,既不利于前端读取,也不利于http传输,用户体验太不好了。
// 某接口吐出的数据形式
{
data: [
{ key: 'some', value: 1111 },
{ key: 'another', value: 222 },
]
}我想象中的合理的数据格式应该是这样:
{
data: {
some: 1111,
another: 222,
}
}多么精简干净舒服且爽。
但是实际上,在业务系统中,一个数据集合除了要知道数据的值以外,还需要知道其他元数据。我再仔细去看接口吐出的其他信息,其实可能还会包含如下信息:
{
data: [
{
key: 'some',
value: 1111,
data_type: 'int', // 数据本身的类型
display_formatter: '2f', // 数据在当前接口用来展示的类型,表示展示的时候要体现2位小数
}
]
}业务场景的不同,会使得数据的使用不同。如果我们以固有的思维去质疑具体的业务逻辑,就会发现自己年轻莽撞且自以为是。
对于业务开发而言,比实现功能更重要的,是描述业务本身,而且必须是准确描述。所以很多业务系统都不约而同的选择用Java或C#来开发,除了.Net平台限制外,重要的原因在于通过语言特定的面向对象编程特性和比较强的类型系统,来确保对业务描述的准确。在开始功能开发之前,我们需要建立一套准确的领域模型,将属性、操作、事件抽象为独立统一体,这样才能保证程序员首先对业务有一定的理解和认知,然后才是业务流程、功能、交互的开发。
既然提到交互,那么我们来看一个具体的例子。
在涉及金融相关的系统中,有一个切换币种的交互。用户点击某个切换图标,会弹出一个模态框,用以让用户选择将要切换到哪一种币种,用户点击对应的币种后,模态框关闭。然而,实际上,这里交互虽然结束了,但是业务逻辑并未就此打住。一旦币种切换,那么意味着业务对象的其他字段信息需要全部重新按新币种计算。假如用户账户上有500万USD,切换为CNY之后,账户上的钱如果需要换算过来,那么需要通过汇率计算得到新的数额。汇率是取实时的汇率呢?还是通过定时任务拉取到自己的库中暂存呢?另外,由于浮点数计算问题,会导致先从USD切换到CNY,在切换回来,反复几次,会不会出现原来的500万,结果变成了499.99万?钱去了哪里?所以,看上去是一个切换币种的问题,实际上,它背后是一整套金融换算和数据管理的问题。
前端数据治理
我们做前端开发,虽然可能不会涉及到上述的后端数据管理问题,但是在前端,仍然面临复杂的业务数据管理问题。由于前端的数据不会自动产生,而是需要从服务器端拉取,所以,本质上,前端的数据全部是运行时的,虽然前端也可以采用一些持久化技术实现数据存储,例如我之前全面介绍过的IndexedDB,但是总体而言,前端仍然是在动态地使用内存即时的消费来自其他来源的数据,就像RAM和ROM,前端数据对应的就是RAM。
前端消费数据的方式千变万化,以我们熟悉的React为例,我们从后端拉取的数据,往往需要转化为组件或应用的state,再由React消费state,完成界面渲染和更新。也就是说,React消费的数据,已经是二手货,甚至好几手后面的,在层层传透过程中,出错在所难免,如果不建立一套确保数据准确性一致性的机制,很难让业务方放心把前端工作交给开发团队。
反例比比皆是,在手机端,用户从一个列表进入一个详情界面,进行一些更新操作,随着业务流转,新的数据被请求下来,并更新了当前这个详情界面。用户从这个详情界面返回到上一页,也就是列表界面,却发现,列表界面代表刚才修改的业务对象下方的一排小字内的数据并没有更新。这种场景几乎每个开发团队都遇到过。不同的技术架构里处理这个问题的方法不同,比如通过一个全局事件进行监听,当内部详情页发生变化时,列表页也要重新请求一次接口,以刷新页面。又或者,直接将列表页的对象和详情页的对象绑定,修改详情页对象就会同时修改列表页对象。等等,实现的方式各有各的不同。这是我们在功能开发中的惯用思维。
除了由于前端弱环境带来的语言层面的问题,由于业务需求多样性代码的问题也很复杂。同一个业务,在不同条件下的逻辑可能却不同。
比如,同一个字段,理论上表达的是同一个东西,但是在A页要展示成四舍五入成整数,而在B页要展示成永远含两位小数。对同一个业务对象的编辑表单中,X这个字段也面临复杂逻辑,当业务刚刚创建好时,你可以随意修改X字段的值,而且它是可选的,可填可不填;但是当业务经过一轮审批之后,X字段变成必填;而等到业务完成审批之后,X字段变成不可修改(其他字段可以修改)但要展示出来给人看。如果按照功能开发的思想处理这些问题,我们要写很难维护的判断逻辑来处理这些问题,稍有疏忽,就会出差错。
前端数据的即时性、流动性、多态性,特别是在业务系统中既要求准确,又要求适应多变的需求,单纯靠数据管理是无法完成的。数据治理是数据管理的高级阶段。从程度上讲,数据管理是从杂乱无章到有章可循,是方法论上的提升,我之前写过一篇《前端状态管理设计——优雅与妥协的艺术》专门探讨过前端状态管理的问题。而数据治理是从可用到有用的升华,是价值观的质变。一个业务,从原来乱七八糟,到使用状态管理器集中统一管理,调试和变化都可以顺藤摸瓜找到数据变化的顺序,这是数据管理的效果。而从这种“基本满足”的状态,上升到“有条不紊,万变不离其宗”,不管React层面怎么写,业务对象的内在关联永远保持,无论运行时状态怎么变化流动,都遵循着业务的逻辑描述,从数据的产生到消亡,都在按照某种约束运行而不会超出这个范围,同时数据质量、数据安全也因这种约束得以保障,即时出错,也有明确的告警,这就是数据治理。关于这一理念,实际上,我在我的播客节目《Robust:程序员的TALK PLACE》 中也提到过类似的理念。

“数据治理涵盖了从前端业务系统、后端业务数据库再到业务终端的数据分析,从源头到终端再回到源头,形成的一个闭环负反馈系统。“
我提出来“前端数据治理”,是希望站在前端的角度,重新去思考前端在业务开发时所面临的问题,而非纯粹去套数据治理的概念。前端数据治理是一个狭义的概念,它虽然会涉及和后端的交互,但我们不需要侵入后端,也不需要从系统整体层面去设计,我们只需要站在前端本身角度,重新审视功能开发的惯性思维,找到一种适合不同场景下的前端开发心态。
小结
本文从我的个人经历出发,慢慢展开聊到前端在业务系统开发下的特殊性,指出业务开发和功能开发的不同,并且阐述数据是业务“准确性”的核心要素,最后引出前端数据治理的概念。从本质上讲,前端数据治理更多的是有关策略、设计模式层面的问题,而非具体的编程实现问题,所以和我们原有的编程习惯并不冲突,冲突的地方在于思维方式,我们如果领悟到前端在解决业务复杂逻辑中数据保持约束的规律之后,就会发现,我们一贯的编程技巧仍然在具体问题中受用,只是在一开始,我们就会对业务系统中的数据管理采取另一种抽象的处理方式,这种方式可能性能稍差,却是我们保障业务准确性的重要一步。

