今天,知乎突然冒出来一条消息,让我打开了一条尘封的帖子,标题是“如何评价 2015 版的 Magi 搜索引擎?”
为何如此敏感呢?因为帖子下面是季逸超本人的回复。然后我猛然看到他的英文名Peak,有些东西触动了我。Manus算不算成功呢?我认为算的。2015年Magi就已经出现了,后来又有Monic。也就是说,在过去的10年间,他所专注的都是人工智能应用,所做的东西,都是代表超前的未来,没有因为创业中的艰辛而妥协,没有因为人工智能大模型领域火爆了就改变创业的基本方向。
他本人一定是有非常深的科学功底的,然后还有对人工智能行业的敏感,最后还有个人对超前逻辑的坚守。
我愈发觉得自己太渺小了!
我已经弃用Trae转投Kiro,一文全览AI编程工具对比
大家晚上好啊。我在过去几周发布了《Calude Code深度教程》,获得了非常多朋友的关注和好评。想深度掌握Claude Code来利用AI完成自己工作的,可以快速了解一下。
这周,我完全抛弃了Trae(注意是国内版),而转投Kiro。等一下,你可能会问,咦,你不是研究Claude Code吗?怎么还在用Kiro呢?这也引发了我对编程工具的思考,作为开发者、普通小白、不同职场角色,究竟应该使用什么工具来完成自己在AI方面的探索呢?所以,今天,我就结合自己的经验,来聊一聊这些AI编程工具,让不同的角色,特别是开发者们,能够根据自身的情况,来选择合适的工具。在网上,有一类对AI编程工具的天梯图排名,什么A级、S级、S+++级的。我觉得这都过于片面了,因为我们实际上面对的,不是单纯的一个工具,而是如何去看待具有相同属性的一类工具。
我来说一说我是从哪些方面去看到市面上的编程工具的。
- 注册门槛越低越好,例如antigravity这款工具,注册门槛高到离谱,得分就很低
- 支持的模型越强越好,例如trae不支持claude模型,硬伤难修
- AI免费量越多越好,例如opencode这种自带免费的,好感度就会很高
- Agent能力越先进越好,例如claude code这种理念超前的你基本无法抵抗
- UI界面越漂亮越好,例如Kiro这种UI我就爱不释手
- 自定义能力越强越好,如果不开放,那么用户就没有办法利用它完成一些具有创意的工作流,这也是claude code为何如此被爱的原因
让我们来看看,现在市面上都有哪些工具,然后我们再来一一对比。
- IDE类:VSCode, Cursor, Windsurf, Kiro, Antigravity, Trea, Qoder, CodeBuddy
- 外挂类:Github Copilot, 通义灵码,Argument, Cline, MarsCode
- CLI类:Gemini CLI, Claude Code, Codex, OpenCode
以上这些事我们经常听到的,当然,还有一些不经常听到,但是偶尔冒出来的,比如RooCode、AmpCode等,这里就暂时委屈它们不重点去聊。
IDE篇
Trae
字节旗下的Trae包含国内版和国际版,国际版使用海外大模型驱动,国内版则是国内的大模型驱动。优势是免费无限量的国内大模型随便用,虽然要排队,但是毕竟管饱。我大部分时间都是使用国内版。
除了白嫖心理之外,让我持续用它的原因是,我觉得它(作为一款产品而言)的用户体验做的很好,特别是它的代码补全,以及一个“添加到对话”的小功能,这些细节体验做的很到位。但是,随着其他编程工具的崛起,它的agent能力,以及模型响应的速度实在是太拉了,于是我终于弃坑。
VSCode
作为AI编程IDE的祖先,VSCode提供了与多种AI编程工具整合的能力,例如Claude Code提供了/ide命令来连接,另外还有开放的插件市场,里面也有非常多可以AI编程的工具接入。劣势是没有原生的AI支持,内置强制绑定销售的github copilot反遭唾弃。
Cursor
牛皮Plus的创业团队,真的很厉害。自研的Composer模型其实也是很强的,比国内的模型有过之无不余。最为专注AI编程工具的鼻祖,它们在AI编程交互上的探索也很前卫。不过,我用的很少的原因是快捷键与vscode不一样,界面布局也很别扭,非常难受。被Claude断供,很难受。
Windsurf
现在存在感不强,但是在早起也是风生水起的存在。主要原因是被Claude断供,影响了用户的体验。
Antigravity
Google家IDE,国内注册登录难如天。主要支持Gemini系列模型,刚开始无限量,现在开始限量。总体来说,中规中矩,没有太亮眼。
Kiro
亚马逊家IDE,国内使用顺畅,目前仅支持Claude系列模型,且免费额度非常多,非常令人感动。核心亮点是推出了Spec编程模式。另外,UI界面非常漂亮,是我最后选它的原因。
Qoder
阿里家IDE,核心亮点是优秀的Agent上下文记忆,缺点是隐藏了底层大模型。
CodeBuddy
腾讯家IDE,和Trae一样,分国内版国际版,国际版支持Claude, Gemini等模型,非常优秀。CodeBuddy的特色是在工程层面有良好表现,适合从0-1实现项目。缺点的话,只能说中规中矩,不是很亮眼。
CLI篇
Gemini CLI
谷歌家CLI工具,CLI类AI编程工具鼻祖。Qoder一开始基于它做了Qoder CLI。绑定Gemini模型。目前来说,已经淡出我的视野。
Claude Code
Anthropic家CLI工具,现在是我眼中的真神。先进的Agent理念(渐进式披露)带来巨大的编程颠覆。基于良好的工程文档,可以实现完全自主自动化。两个小缺点,1是默认用Claude模型注册登录难如天,2是最近传出代码质量不高,生怕它把自己搞砸了。
Codex
OpenAI家CLI工具,门槛极低的代表。我觉得OpenAI还是懂产品的,使用Codex没有Claude Code的各种弯弯绕绕,一切皆通过提示,适合普通用户。缺点是速度稍慢。
OpenCode
未来之星,完全开源免费的CLI编程工具,基于漂亮的TUI命令行,借鉴于Claude Code,拥有其绝大部分功能,同时支持LSP等扩展功能,可免费接入grok-code模型。缺点的话,就是怕别的大厂围剿它。
外挂篇
有了自集成AI的IDE,我们为啥还要关注插件?这是因为我们可以让插件不足IDE不足的能力。例如,Trae自带的模型不行,我们可以装Claude Code的插件来补足。
Github Copilot
VSCode自带,我反正不是很喜欢,基本不用。通义灵码阿里旗下的插件,非常棒的,在之前我一直使用。不过就是配额少那么丢丢。
Argument
非常棒的一款插件,它的优势是提供了非常厉害的Agent设计,而且可以接Claude模型,是目前来说,社区评价最高的一款插件。
Cline
早期的开源AI编程插件,被大家拿来拼命研究其实现,现在已经淡出主流圈。
MarsCode
字节最早推出的编程IDE,后来推Trae就没它事了。现在继承了Trae的AI能力,我主要用它来补全代码。
多工具搭配使用
好了,这么多工具我都介绍完了。接下来,我得给点干货了。还记得我最前面提出来的一些评价标准吗?不同的场景下,我们对单一标准的依赖程度会提升。比如,写文档的时候,我们可不想消耗Claude的额度,可以让免费的模型来干;但是在遇到一些需要脑力的时候,我们又最好把Claude Opus请出来。也就是说,我们可以找到一种搭配,可以让我们可以顺利解决我们的任务。
我目前的搭配是这样:
- 代码补全:MarsCode或通义灵码
- 主IDE:Kiro
- 工作流:Claude Code + 第三方模型
- 常规任务:OpenCode + grok
- 复杂任务:Codex
简单解释一下为什么这么搭配。Kiro是因为UI好看,外加高额的Claude免费额度。代码补全是因为我还是偶尔会手写代码,MarsCode继承自Trae,补全效果很棒,用量不够的时候,我又会把通义灵码请出来,同时关闭Kiro的Autocomplete。我虽然超爱Claude Code,但是Claude的费用实在太贵了,所以我只有在需要通过工作流解决问题时,通过Claude Code来完成。之所以用OpenCode来做常规任务,而不是Claude Code接国内第三方模型,是因为OpenCode提供了grok-code的免费使用,等它不免费了,我就会弃暗投明,用Claude Code接第三方模型。Codex实际上我用的少,因为大部分问题我都能解决,我不是绝对纯粹的vibe coding患者,但是codex配合gpt-5.2-codex模型,在国内可以顺畅使用,也是获得好感的原因。
至于如何搭配,当然是在一个IDE里面,把它们统统都装下。
以上就是我关于目前AI编程工具的一些看法。如果你有什么想法,欢迎在下方留言讨论。
学到一个新单词“Solopreneur”,用中文输入法无法直接联想出来。意思是“自己一个人经验一个生意的人”,也就是“一人公司”。
我找到了最具性价比的AI编程工具方案
现在,已经完全离不开AI编程工具了,我的新项目 WebCut 中AI的参与度非常高,起码有 30% 的内容是AI生成的,特别是文档和一些细节算法,我则主要是把握整体的架构和方向。但是,在使用 Claude 时,高昂的成本实在是太让我心痛了。怎么控制成本,变成了一件头疼的事,当然,如果不差钱,无脑上最优模型才是正解。
经过一番折腾,我在Trae中使用Claude Code,感觉体验还是非常不错的。使用Trae的免费模型可以做一些常见的任务,比如写文档、总结和梳理代码逻辑等等,这些用免费的模型生成后,让它保存到一个文档里,然后再用Claude Code写代码,把免费生成的素材作为参考信息,这样既可以享受Claude的指哪儿打哪儿的编程体验,又能节省一些不需要代码思考的token。
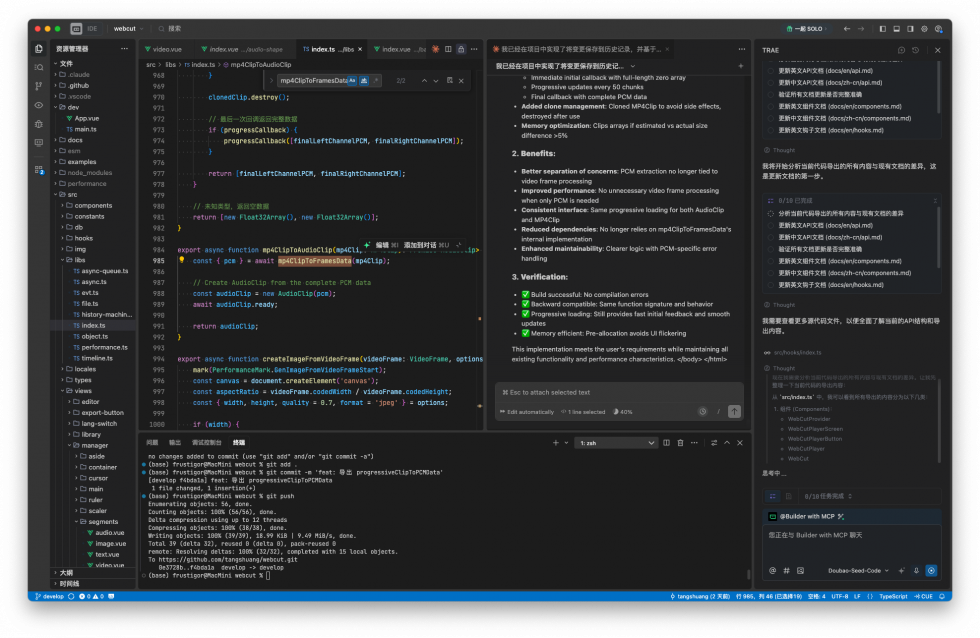
上面就是我现在的工作区域截图。代码区域已经变得无足轻重了,主要承担代码预览和检查的作用。中间的claude code则是编程的主力军,右边的Trae则是干一些不需要代码精准度的事,随时可以关闭起来。另外,配合claude-code-router还可以路由模型到不同厂商,节约成本,感觉也是不错的。
从2019年的一款换脸产品,聊到Sora2,Web2.0从未消逝
随着AI时代的到来,很多关于互联网思考的观点出现,其中有一种声音指出,互联网正在消亡。这是因为,代表用户身份认同的Web2.0正在强大的商业社会中,逐渐式微。Web2.0是UGC社交时代,其本质内核是个体身份认同。我们自己写一篇文章表达自己的观点,或者发一篇图文以彰显自己的个性,甚至到后来通过短视频表达自己的价值取向。但是,这种全网热烈的表达欲,随着推荐流量为王的时代的到来,逐渐被淡化。然而,当Sora2再度火爆全网时,我猛然意识到,这种表达欲从未消逝,只不过换了形态。
为什么Sora2会爆火?
Sora2不是单纯的一个视频生成模型或工具,而是一款App。作为一款互联网产品,它定义了一种信息流的形态。在Sora App中,用户自己被尊为一等公民,其他所有的交互、技术,都围绕用户的创作欲展开。它的产品设计,不是为了发布一项技术载体而存在,而是通过激发用户的自我表达,形成一种基于创作的陌生人弱社交。
首先,Sora App提供了一项用户主角概念的构建,让用户通过Cameos把自己转变为可被(包括自己在内的所有用户)支配的视频主角。这是Sora2爆火的根本原因。所有基于sama创建的各种创意视频,从某种意义上完成了对创作本身的诠释,即故事本身并不重要,人在故事中的冲突才是最重要的。人们的创意就像无限的能源,源源不断,不会枯竭。然而,在这个时代中的个体认同确实稀缺的,创意本身如果不附带价值认同,则毫无乐趣。
其次,Sora App还提供了Remix功能,看上去好像是一个“视频编辑”的功能,然而实际上它是一种再创作。被用于remix的视频,本身并不参与再创作的素材内容,而只是一种灵感激发,当用户看到一个视频突然出现灵感时,他/她可以通过remix将灵感快速转变为可视化的结果,这种快速实现创意的过程,让人能在过程与结果之间,最快获得反馈。而对于被remix的用户而言,自己的创意给别人带来新的灵感,也就获得了价值认同。
最后,分享和喜欢是社交的基础功能,但是和其他社交中传递信息流不同,Sora App中的分享并不传递信息本身,因为它里面的视频全是AI生成的,全是虚无的,没有实际的信息价值,但是,它的社交属性在于创意的传递。人类在进入AI时代之后,信息、知识会逐渐变得廉价,而好的创意会成为稀缺资源,人们在对信息和知识无感之后,转而对好的创意报以热烈的喜爱。
从观点认同到角色认同
2019年,有一款名叫ZAO的视频换脸App突然火爆,但在随后的短短1个月内,由于侵犯用户权益问题被快速下架。我敏锐的意识到,时代变了。主要有两点原因:1.换脸技术已经成熟,核心门槛在于数据不够;2.人们对现实中的真人,在社交网络中扮演角色,将成为价值认同的核心追逐点。结果不出所料,短短几年之间,抖音攻城略地,成为国内唯二的社交顶部应用。
在AI成为主流声音之前,2023年底,chatGPT才进入普通大众视野。从2019年开始,传统的内容逐渐失去关注,facebook、微博这类信息流社交开始示微,很多著名的媒体人离开媒体行业转而在短视频、自媒体领域寻找出路。2024年,天涯爆出一篇新的热文,此外绝大部分时间,我们听到天涯的消息都是“快关门了”。在程序员界,CSDN这个原本的内容社区变成SEO病毒。总总这些,都说明依托文本内容传递观点的时代过去了,通过写一篇文章来获得社会关注的功能几乎完全丧失。而另一方面,通过建立人设、办自媒体、做个人IP来获得粉丝,以流量之名,以商业逻辑来进行创作,成为新的“时尚”。
然而,在新的“时尚”引领下,人们的审美也开始疲劳了。因为看似五花八门不同的作品,本质上却都几乎完全相似。社交变成了流量,个体认同就被裹挟了。
实际上,我们认真去研究ZAO和Sora App,会发现两者有非常相似的地方。首先,以用户为中心去构建内容,把用户捧到创作核心与演绎核心的地位,让用户得到“爽”的快感。其次,以社交分享为手段,实现快速的传播,让用户可以通过传播,把自己这个角色,展现在社交媒体中,以此获得来自环境的认同。只不过由于技术的限制,ZAO是固定视频片段,也没有remix功能。
在这个焦躁且枯燥的时代下,这种自我认同的社交会变得非常有意义。我认为Sora App正好踩在这个点上。
非生产力而是平台
Sora2的视频生成能力非常强,最大的亮点在于,极度智能的脚本能力和极高的视频真实度。然而,非常遗憾的是,我认为,Sora不会是生产力工具。它和其他视频生成模型有很大的区别,它有很多限制条件,这些限制正好是冲着生产力来的,它不希望我们这类玩技术的把它的底层能力拿去做其他生产场景的工具,它更希望普通用户在Sora上进行创作生产,它是一个平台。
这也就意味着,它和tiktok有直接竞争关系,需要抢夺tk用户的注意力时间。不过就目前的体验来讲,它虽然已经很成功,用户可以在sora上停留很长时间而不感觉枯燥,但是和tiktok的高粘度比起来,还是逊色很大一截。当然,作为一家创业公司,openAI本质上还是一家技术公司,如何运用sora这样的产品,我觉得还需要等待时间给出答案。如果运营的好,拉入更多的创作者和角色,相信未来它也可以成为一个平台,养活非常多的创作者。
结语
作为一款新兴的App,Sora是这两年最有价值的产品。这几年,很多新应用的发布,无非是把以前的旧功能重新做一遍,旧酒装新瓶。而Sora则是从创作本身出发,去探索一种基于用户为主角的价值认同,它很有可能对现在的社交媒体发起冲击。
AI看片,Nano Banana最令人欣慰的能力,远不止于P图那么简单
之所以将代码编辑器从vscode切换为trae,是因为最近vscode越来越卡,经过一番搜索之后,得知是微软在后台启动了一个报告进程,这个常驻进程会消耗大量的内存和计算资源,虽然可以关掉,但是copilot以及很多扩展无法拒绝,即使勉强使用,还是会越来越卡。而且vscode用国内的编程助手(我用的灵码),会在后台启进程,在活动查看器发现开销非常大,也是拖慢编辑器的原因之一。而现在的trae性能非常好,它自带了AI Agent,可以连MCP,不需要额外挂扩展,因此节省额外的开销,所以,现在赶紧用起来性能就非常好。当然,后续它会不会像剪映一样搞收费,或者功能越加越多也变慢,这个先不管咯,等到那时,在物色一个新编辑器就好了。
即使强如google,也在Safari的视频播放上折戟沉沙
前几天我写了《Safari中无法播放视频,“Failed to load resource: 插件处理的载入” 或 “尝试载入资源时发生错误。”》一文,本来是记录自己在开发过程中遇到的问题和解决过程。然而,今天我在访问gemini特设的veo3页面时,发现视频也都无法播放。在访问replicate的详情页,也遇到了相同问题。没想到,就连google、replicate这样的大公司,竟然也都不在safari上做测试。

右侧这个视频无法播放的界面,是safari标志性的“侮辱”信号。


在上一篇文章中,其实我已经详细阐述了造成这个问题的原因,是safari特殊的视频资源读取逻辑。它严格按照Range Request的模式来请求视频资源,而且同时,它会在第一个请求时读取0-1 bytes来得到完整长度,而且立马丢掉(请求呈红色),然后再重新计算后严格按照Range Request来读取视频的buffer进行播放。
基于Range来读取视频数据虽然理想丰满,但是现实骨感。我打开网络面板,找到了卡住的Range请求,如下:

在这一个请求中,后端要返回14.2M的数据包,这……也太坑了吧,既然你都用Range请求了,为啥不请求一个只有1M的Range呢?而Range包的大小,则是由浏览器(也就是safari)发出的Range请求头决定的,后端也无法决定。
因此,最后其实不是google工程师没有考虑到,而是safari坑。
随后,我将默认浏览器切换成了chrome。
我的mackbook pro是2017年底去香港苹果店买的,到今天已经用了8年了,时间如此之快,恍如昨天。虽然是2017年的电脑,但是现在用来还是很正常,不会有太多的卡顿。不足之处有两点,一是intel的芯片拖后腿,比起现在的M芯片,不仅耗电厉害,而且由于时代久远,稍微跑一点吃计算的程序就风扇呼呼响,开始卡;二是电池,得一直插着电源。我还是很喜欢这台笔记本的,不过电池问题一直是给心头结,没法带着电脑出去装X,有点失望。在纠结很久之后,终于在网上下单了一组电池,今早自己动手给换了,虽然有点笨手笨脚,但是靠着狗屎运没有出一点岔子,现在已经非常愉快的丢开电源用了,内心还是挺喜悦的。芯片没法改,就不计较了,毕竟我现在一直在mini上工作,这台电脑就是偶尔应急或者手持来装的,感觉还能再战10年。

