将行内渲染到svg保存到本地
在一些情况下,我们想要将类似d3.js之类的框架渲染的svg保存到本地,这要怎么实现呢?其实非常简单。
首先,让我们创建一个用来下载的函数,这个函数不仅仅支持svg,甚至可以支持任意内容。
function download(href, name) {
var a = document.createElement('a');
a.download = name;
a.href = href;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
}
我们创建了一个通用的下载函数,但是这个href只支持url,所以,我们要创建一个函数来获得svg的url。
function createObjectUrl(content, type) {
return window.URL.createObjectURL(new Blob(content, { type: type }))
}
这个函数的content是可以支持多个类型的,因为它会被传入new Blob中,但是需要注意,如果传入字符串,要传入一个数组。
download(createObjectUrl(['<div></div>'], 'text/html'), 'index.html')
现在就好办了,我们只要把svg元素的outerHTML读出来,然后传给download函数就可以了。
download(createObjectUrl([document.querySelector('svg').outerHTML, 'image/svg'), 'some.svg')
对上面操作进行简单封装
function downloadSvg(svg, name) {
download(createObjectUrl([document.querySelector(svg).outerHTML, 'image/svg'), name)
}
如果要下载为其他类型的图片,那在download之前,要进行一个转码,我们用canvas作为中转,把svg放到一个canvas中之后在下载。
function downloadSvgAsPng(svg, name) {
const text = document.querySelector(svg).outerHTML
const { width, height } = svg // 或者通过其他方式也可以获得宽高
const image = new Image()
image.onload = () => {
const canvas = document.createElement('canvas')
canvas.width = width
cnavas.height = height
const context = canvas.getContext('2d')
context.fillStyle = context.createPattern(image, 'repeat')
context.fillRect(0, 0, width, height)
download(canvas.toDataURL('image/png'), name)
}
image.src = 'data:image/svg+xml;base64,' + btoa(text)
}
此处我们没有用到createObjectUrl,因为我们直接将svg转化为base64然后渲染到canvas里面,变成了位图。
最后,需要注意的是,使用这种方法,我们必须在svg内完全定义自身的样式,如果你是在svg之外定义了svg内部元素的样式,那么下载的svg就不包含这部分样式,那自然就会有样式问题。
ScopedQuery: 查询你需要的数据,剪裁无用字段
作为前端,你肯定经常有这样的烦恼:我明明只需要这几个字段,结果你全部给我返回了,何必呢?今天我发了一个包 scopedquery 以解决这个问题。这里 scoped 的意思是“限定的”,也就是你进行的查询是在限定的内容里面。它基于一个新的语言,样子大概如下:
query "https://xxx.com/api/articles/:id" -> {
article_title
create_time: date('YYYY-MM-DD')
article_content
view_count: number
comments: [
{
comment_author
comment_content
comment_time: data('YYYY-MM-DD')
}
]
}
上面这段代码所表达的意思是,往 “http….” 发送了一个请求,这个请求要求返回的结果的形状,以及节点上对节点值的格式,需要按照 -> 后面的内容进行返回。
它看上去和 graphql 有点像,但又很不同。它是一个描述性语言,类似 JSON,而非一个编程性语言,即 graphql。graphql 虽然很好,但是,它依赖底层的建设和比较难理解的语法组织。而 ScopedQuery 则纯粹是为了解决数据裁剪而生,不负责底层库的查询,因此,它更轻量,且开箱即用。
npm i scopedquery
安装好后,在业务代码中这样写作:
import { Query } from 'scopedquery'
const data = await Query.run(`
query "http..." -> {
// 支持注释
// 裁剪后的内容
}
`)
默认情况下,内部会使用全局的 fetch 进行 ajax 请求,但是你可以自己定义:
const query = new Query({
fetch(url, params) {
// ...
}
})
const data = await query.run(`...`)
在 node 端,可以使用 Query.parse 方法直接裁剪数据:
const data = Query.parse(dataFromBackend, `{
name: string
age: number
}`)
冒号后面的 string, number 看上去是类型,实际上是格式化工具,它们可以被自定义,让开发者自己觉得不同情况下怎么返回值。
基于 webpack 的能力,我们可以把这些 query 文本单独保存,这样我们可以极为清晰的了解每一个接口对于前端而言,需要的是哪些内容,且有值描述,对于前后端而言,都可以作为参考,辅助前后端在开发过程中进行沟通。
certbot依赖变动导致https失效
今天进博客发现https又失效了,内心个崩溃,莫非终有一天我还是会走上付费的道路吗?之前记录过一次由于certbot依赖版本低导致的无法自动更新证书,今天再次用那个方法,发现没有用。遇到的错误提示如下:
Attempting to renew cert from produced an unexpected error: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:645). Skipping.
然后去外网搜索,找到一个线索,是由于依赖的DST_Root_CA_X3.crt过期了,这个DST_Root_CA_X3.crt应该是大部分服务器都一样,所以可以通过以下的方法解决:
sudo apt-get update
sudo apt-get upgrade
sudo sed -i 's/\(.*DST_Root_CA_X3.crt\)/!\1/' /etc/ca-certificates.conf sudo update-ca-certificates sudo certbot renew
通过这个方法,就可以更新证书了。
前端如何优雅建模?
这篇文章放在“杂”栏目下面,说明会是一篇不成体系的文章。我想谈一下如何在前端优雅的建模。直入正题!
前端建模包括两个层面的建模:业务领域建模和交互领域建模。这两者基本上没有本质联系,但是在前端这个场景下,有的时候又有一些特殊的情况。我们来看看如何在这两个层面建模。
业务领域建模
简单讲,业务领域建模,就是把业务实体与其逻辑进行建模。在知乎有小伙伴留言说,前端不怎么适合DDD,因为前端是贫血模型。但在我实际实践中,我更多是充血模型。业务模型需要包含字段本身,以及复杂的业务逻辑。你可能会讲,业务逻辑会被放在后端,但是实际上前端也要这个业务逻辑,比如当一个订单的负责人是组织中的某个职位的角色时,需要在订单推进过程中填写审核时间这个信息。那么,在前端,必须去判断当前用户是否是该角色,或者获得当前用户的某个权限。这个逻辑是跑不掉的。
最近,我升级了tyshemo,支持了装饰器的方式进行meta的定义。现在,你可以这样定义自己的模型:
import { Model, meta, state } from 'tyshemo'
class OrderModel extends Model {
@meta({
type: {
user_id: String,
},
})
master = null
@meta({
type: Number,
})
total_price = 0
@state()
role = 'member'
canFillDate() {
return this.role === 'admin'
}
}
通过@meta来装饰字段,通过@state来装饰状态属性。这样撰写模型,会有更舒服的感觉,而且可以更好的兼容typescript,避免以前使用static属性定义时,无法与typescript很好结合的问题。
简单讲,通过业务建模,我们得到了一些模型,这些模型是独立的,自治的,在不被使用的时候,它独立描述了该业务对象的各种字段及其逻辑,但由于不在具体的业务场景中被使用,因此也只能表现有限的业务信息,它只能告诉读代码的人“我有什么,能做什么”,而不能告诉“我做了什么”。只有使用这些模型的实例,放到具体的业务模块中,才能完成真正的模块编程。所以,单纯讲,业务建模虽然重要且有用,但是如果不被适当的人使用,就会非常混乱,毫无头绪。
建立业务模型,可以把有关需求文档中,有关核心业务的东西分出一层。
交互领域建模
这是后端没有的东西。直白讲,交互领域建模就是写类似Vue一样的View Model,但是没有template那块。简单说,就是建立一个模型,考虑到将来在view层使用它,所以该模型的所有api,都是为view设计的,主要目标,是和需求文档中有关交互相关的描述一一对应。在交互模型中,实例化业务模型,把业务模型变成交互模型内部的状态。当在view中实例化交互模型,就看不到业务模型了,view拿着交互模型的接口进行渲染和事件回调。
我在nautil中提供了可用于建立交互模型的一个体系。举个例子:
import { Component } from 'nautil'
import { SomeController } from './some.controller' // 写好的交互模型
class MyPage extends Component {
controller = new SomeController() // 实例化交互模型
SubmitButton = this.controller.turn((props) => {
const { someModel } = this.controller // 读取交互模型内的某个业务模型
const { total_price } = someModel // 读取业务字段值
return (
<button className={total_price > 100 ? 'sale-count' : undefined}>Submit</button>
)
})
render() {
const { SubmitButton } = this // 读取定义好的组件
}
}
上面这段代码中,SomeController是一个交互模型,里面使用了另外一个SomeModel业务模型。但是,对于view层而言,你不需要知道它是一个业务模型,你只需要调用它即可。
Nautil在controller中提供了turn方法,用于把一个用到controller的普通的组件转化为一个被controller控制的组件,当controller中某些特定信息发生变化时,这些组件就会自动更新。
分层
前端代码分层管理,从代码量上,并不比铁板一块的管理多多少,毕竟所有的代码,都来自产品的需求描述。但是,分层管理所带来的灵活性、可维护性是不可估量的。
如果你写一个有很多块的页面的vue组件,你就会发现,你的这个组件会越来越多交织在一起的代码,从一开始很容易理解,这几个状态和这几个方法是关于最顶上这一块的,但是,随着页面其他块的交互代码的增多,你就会发现,这个状态会在哪块用?这个方法会在什么情况下调?能不能删?可不可以改?都需要上下反复读代码来确认。
而如果你采取代码分层,你会先针对业务本身的实体进行建模,然后对业务中的交互进行建模,最后才是view层的编写。此时,view层的代码会清晰很多,因为它不再去管理属于业务的逻辑,而更多的是用和回调。
依赖
在view层,我们用vue或react来写,我更多使用react,因为react没有使用Proxy或defineProperty,可以使得我们建模时,使用更多魔法。但是,有些时候,由于view层的特殊机制,导致我们如果完全脱离框架进行建模时,不得不提供一些多余的接口,来帮助和view进行依赖绑定。
以我工作的项目为例,我们使用angularjs作为主体框架,如果我单纯使用ESModule的模块,就没有办法直接使用$rootScope等这种angularjs内置的服务,但是如果我提供一个angular factory,就会牺牲模型的可移植性,为之后跨平台复用带来问题。所以,nautil中提供了controller.turn这个方法来实现模型层和视图层的连接,简单说就是在框架层面调用forceUpdate来实现重新渲染。
Typescript中如何表达一个类是继承至某个类的?
在平时写代码时,我们常常会有这样的写法:
class BaseClass {}
function init(SomeClass) {
if (isInherited(SomeClass, BaseClass)) {
...
}
}
上面代码中,表示的是,init这个函数的参数,只接收继承自BaseClass的类,那么这种表达,在typescript中如何表示呢?
function init(SomeClass: ???) {
...
}
你看,这比较麻烦吧。你可能会想到:
function init(SomeClass: BaseClass): void
但这显然是不对的,这样表达的意思是SomeClass是BaseClass的实例,而不是类。
正确的表达是如下:
function init(SomeClass: new () => BaseClass): void
其中 new() 是 typescript 中的特殊表达形式,表示以该类型作为具体类进行实例化(需要注意,在typescript中,某个class既是类型,也是值)。而 new () => BaseClass 这句话的意思就是实例化之后得到的实例的类型是BaseClass,或者说,实例化之后是BaseClass的实例(由于在typescript中,某个class既是类型,也是值,因此,比较难用纯粹类型语言进行表达)。这样一来,我们就可以表达出“SomeClass是继承至BaseClass”这一要求。
Web性能指标
https://bitsofco.de/web-performance-metrics-cheatsheet/
SFCJS的实现思路
单文件组件(SFC)及语法
Vue 和 svelte 都具有自己的文件格式,在 .vue 或 .svelte 文件中,我们描述了一个组件的完整上下文。单文件组件这种组织方式特别适合单一功能的组件发布,你可以通过比较少的代码量,表达一个 UI 交互要做什么事情。
因此,我在写 sfcjs 时借鉴 svelte 的语法设计,在不改变原始 html, js 和 css 语法的基础上,增加了一些特定的形式。一个 sfc 包含三个部分 script, style, html,具体如下:
<script> let a =10;functionincrease() { a ++; } </script> <style> .foo { font-size: [[a]]px; } </style> <div> <span class="foo">{{a}}</span> <button @click="increase()">inc</button> </div>
这份示例代码中包含了组件内变量的声明和使用、动态 css 语法、动态 html 语法。由于 sfcjs 只是一个 POC,很多细节没有深入,所以只能展示一些比较粗浅的例子。
我们将上面这段代码放在一个 .htm 文件中,这样编辑器可以帮助我们为代码高亮。这个 .htm 文件即我们的一个组件文件。
基于AMD加载组件
我一开始想直接用 seajs 做加载引擎,但后来觉得没必要,因为我不需要严格的遵循 AMD 规范。但基于其实现原理,我们可以在需要的时候加载 sfc,实现文件异步加载和组件异步实例化。
在一个组件中引用另外一个组件,需要特殊的引用协议。
<script>
import SomeComponent from 'sfc:../components/some-component.htm'
const title = 'xxx'
</script>
<div>
<some-component :title="title"></some-component>
</div>在 import from 时,使用 sfc: 作为协议前缀,遇到一个路径时就认为是一个组件,然后在 html 模板中使用这个组件。SomeComponent 如果依赖了其他组件,它不会立即去请求这些组件的 sfc,而是会等到 SomeComponent 实例化的时候,再去请求。
运行时编译
组件 sfc 的语法显然是无法在浏览器直接运行的,我们需要做一个编译,而这个编译,我们直接在前端做。我们利用 webworker 或 webassembly 等技术,不占用 js 运行时线程,编译完之后,输出编译好的 js 脚本。输出的脚本以 blob 的形式,作为 script 进行载入,此时,利用 AMD 的 define,就可以让这个组件加入到我们的备选组件中。
整个加载编译过程如下:
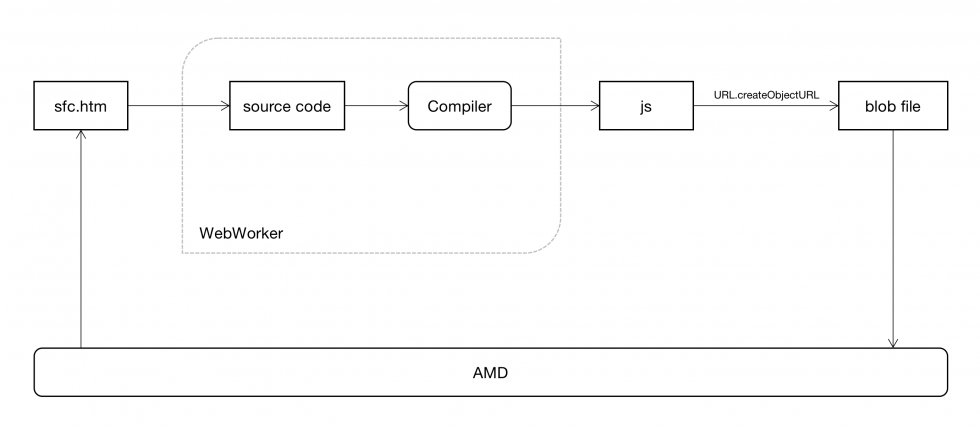
这里的问题在于:1. 运行时编译,会不会性能不好?2. 安全性?
我相信你了解过 vite,简单说,vite 将 bundle 转化为单一文件网络,对每个文件进行编译,当该模块被使用时,发出 http 请求该文件,http 到达服务器时,对该文件进行编译后返回编译后的代码。从这个点上讲,运行时编译用的是客户端的资源,可能比 vite 还快。相反,前端的性能瓶颈,可能在加载巨大的 bundle 的时候更明显。至于安全性,在 compile 之前做一次 check 也是应该的,这看具体场景,因为 sfc.htm 的内容不是直接运行的脚本,只有它被编译为 js 之后,才会真正运行。
利用 web components 的设计
和 react 要用 render 函数来启动应用不同,sfcjs 如下启动一个组件:
<sfc-view src="./app.htm"></sfc-view>理论上,你可以在任意 web 应用中使用这个句式来渲染一个 sfcjs 的组件,包括但不限于在 react 或 vue 中。组件的渲染结果,将被放在该元素的 shadowRoot 中,包含样式。
样式隔离
腾讯前端框架 Omi 是基于 web components 的,可以比较好的隔离样式,你可以借助它开发自己的 custom element 来实现自己的 UI 组件。但是,这里有一个问题在于,如果一个组件依赖于另一个组件,那么必须把这两个组件打包在一起,甚至,被依赖的组件在特定条件下并不会被用到。几乎大部分框架和 omi 一样,都不是开箱即用的(除了 jquery 或 alpine.js),我们没法马上体验它的开发效果,而且,更要命的是,部分框架具有传染性,某些情况下,你只需要其中的某一个功能或组件,但是,你不得不在外面给它一个很大的运行时(例如 react-dom),并且它不兼容(或很难)其他的技术栈。而基于 web components 则可以比较好的实现外围运行时无关,无论你在 react 中,还是 angular 中,都可以使用基于 web components 写的组件。
我在写 sfcjs 时,想到这一点,组件应该是自治的,开发者不应该去思考,当前这个组件是否会(在样式上)影响其他组件的运行。你可以看下基于 sfcjs 写的两个组件:
<style>
.bar {
color: #ccc;
}
</style>
<button class="bar">ok</button><style>
.bar {
color: #999;
}
</style>
<button class="bar">yes</button>上面这两个组件都定义了 .bar 这个类,但是它们在同一个页面中使用时,不会相互污染。
它的原理是,基于 shadowDOM 完成渲染,因此,样式不会对其他元素产生影响。
响应式动态样式
通过修改变量可以让布局的部分变更,那样式呢?在 vue 的一个提案中,提出可以通过某种方式实现样式的响应式编程,具体如下:
<template>
<div class="text">hello</div>
</template>
<script>
export default {
data() {
return {
color: 'red'
}
}
}
</script>
<style vars="{ color }">
.text {
color: var(--color);
}
</style>也就是通过在 css 中使用 var 来标记变量。它基于css 变量这个被广泛支持和接受的技术,但 vue 的提案我觉得仍然暴露太多实现细节,在 sfcjs 中,结合语法,其响应式写法如下:
<script>
let age = 10;
function grow(e) {
// change variables may cause rerender
age ++;
}
</script>
<style>
.name {
color: #ffe;
}
.age {
color: rgb(
/* use js expression with `var('{{ ... }}')` */
var('{{ age * 5 > 255 ? 255 : age * 5 }}'),
var('{{ age * 10 > 255 ? 255 : age * 10 }}'),
var('{{ age * 3 > 255 ? 255 : age * 3 }}')
);
/* use variables with [[]] */
font-size: [[age]]px;
}
</style>在 sfc 文件中,上下文是流畅的一体,在 <script> 中定义的变量,在 style 和 html 中直接使用。当变量变化时,对应的样式值也发生变化。
其具体原理是,我在 shadowRoot 中建立了两块 <style> 一块用于提供变量(会被动态更新内部文本),另一块使用这些变量(永远不变)。
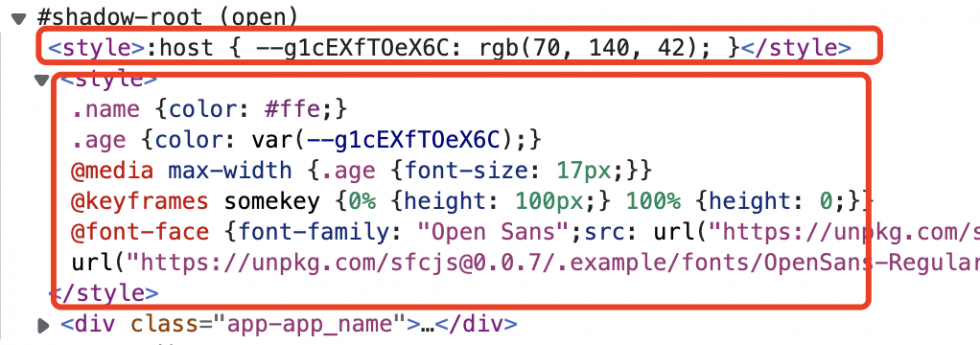
在对应的变量发生变化的时候,第一块整个内容都会被重建,而第二块内容中会使用重建后的样式重新渲染,从而达到动态更新样式的效果。
无 virtual dom 的响应式
进入 2021 年,新出现的几个热门框架都不在基于 virtual dom 实现响应式,一个重要的原因在于 virtual dom 的成本巨大,且性能上并不占优。
和 solidjs 一样,sfcjs 在编译时收集每一个 DOM 节点所依赖的变量,当对应的变量发生变化的时候,去重新计算对应的值,并与当前状态进行比较,最后更新 DOM 节点。这里的不同在于两点:1. 发生变化的变量对应的 DOM 节点才会去计算,其他 DOM 节点即使依赖变量,但没有变化,不用计算。2. 直接对单个 DOM 节点进行是否需要更新的计算,而不再拿整个组件的节点树来进行 diff。
这个实现不算创新,甚至在早几年的时候就有人这么做过。
对于 sfcjs 来说,魔法在于,基于原始语法不需要做过多的编译,和 svelte 不提供(或几乎没有)运行时不同,sfcjs 在运行时前置了一个很小的响应式内核框架,所有组件的编译结果代码实质上是依赖于这个内核框架的。而这个内核框架在设计 API 的时候,完全是为了搭配编译过程设计,所以,编译过程,就是把源代码通过匹配、token 化等处理,做了代码转化,甚至都没有用到 AST 那一套。
当然,这样做,并不是为了性能,完全是为了尝试一条无 virtual dom 的道路,为了乐趣。

