在《查看了300+ MCP Server之后著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。,我认为这个生态要祛魅了……》一文中,我数落了MCP生态的一些不足,【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】以及抨击了媒体过分吹捧MCP的现象。但这转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。并不代表我完全否定了MCP的意义。今天Q本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】wen3再次刷新了基础模型的能力,其中一【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】项重要特征在于对Agent的支持优化,以本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net及对MCP的针对性优化。足以见得,202著作权归作者所有,禁止商业用途转载。【作者:唐霜】5年会是Agent应用真正被市场认可的一【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】年。
转载请注明出处:www.tangshuang.net【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。MCP虽然是由Anthropic一家公司转载请注明出处:www.tangshuang.net【本文受版权保护】提出来的,但随着社区生态的壮大,它也会成转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net为未来“2A”(面向AI,这个是我提出来【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net的哈,现在我们终于从2C, 2B,到了2【版权所有,侵权必究】【本文受版权保护】A)类应用的基础协议之一,用以对接来自不原创内容,盗版必究。本文作者:唐霜,转载请注明出处。同服务商、本地软件、云端函数、其他AI应【转载请注明来源】【本文受版权保护】用(如其他Agent等)的应用层通信协议本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】(虽然google提出来A2A协议,但是在未经授权,禁止复制转载。【作者:唐霜】我看来落地困难,一个本质的点在于,Age【原创内容,转载请注明出处】未经授权,禁止复制转载。nt本身也可以通过API来调用,基于MC【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】P封装API也可以实现Agent之间的通原创内容,盗版必究。【原创内容,转载请注明出处】信,如果“我们不需要太多协议”是共识,那本文作者:唐霜,转载请注明出处。【未经授权禁止转载】么A2A协议就没有必要存在)。但是,普通开发者(特指基于LLM的A【原创内容,转载请注明出处】【转载请注明来源】I应用开发者)立即接入MCP却并不容易。
【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。正如我上篇文章中提到的,MCP只解决了工未经授权,禁止复制转载。原创内容,盗版必究。具的注册和调用问题,但未解决客户端与大模原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】型的交互痛点。因此,我打算开发一个服务,【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net让开发者们可以以原始的API方式,接入到转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。MCP生态中,抢先体验MCP生态带来的便【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】利。于是,MCP Bone这个项目诞生了转载请注明出处:www.tangshuang.net【转载请注明来源】。通过这个项目,我既对MCP的服务器开发【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。有了一定了解,同时,也从产品层面对MCP【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】的生态构建有了一定的思考。接下来,我就将【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net通过这篇文章,详细拆解我是如何构建MCP【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】 Bone的,以及,我在这个过程中所接触【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。的MCP开发方面的趣闻思考。
【未经授权禁止转载】原创内容,盗版必究。原创内容,盗版必究。什么是MCP Bone?
在开始之前,我需要先介绍一下MCP Bo【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。ne,以及我设立这个项目的目的。
【版权所有,侵权必究】转载请注明出处:www.tangshuang.net【转载请注明来源】本文作者:唐霜,转载请注明出处。MCP Bone是一个在线服务,用以帮助【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net开发者降低接入MCP生态的难度。开发者可著作权归作者所有,禁止商业用途转载。【作者:唐霜】以在MCP Bone的页面上,以简单的方著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】式,注册自己应用可能涉及的MCP Ser【作者:唐霜】【版权所有】唐霜 www.tangshuang.netver,这些MCP Server会运行在【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。云端,随后,开发者可以通过传统的Rest未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】ful接口形式,从MCP Bone获取用著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】于与大模型交互的function cal著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.netling tools,或包含特定模式的p【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.netrompt文本,用以与大模型进行交互。通本文作者:唐霜,转载请注明出处。【本文受版权保护】过这种开发方式的设计,MCP Bone让【未经授权禁止转载】转载请注明出处:www.tangshuang.net开发者完全不需要自己去构建和部署MCP服转载请注明出处:www.tangshuang.net【本文受版权保护】务器,就可以让自己的在线应用接入MCP生本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】态。它就像一个MCP Server的集装【本文首发于唐霜的博客】原创内容,盗版必究。箱,把复杂的MCP生态部署、通信等封装在著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net集装箱中,使开发者从外部来看,变得异常简本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。单(就像传统调API接口一般,不需要任何未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net心智负担)。
转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】未经授权,禁止复制转载。 【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】或许这样讲你还不是很理解,没关系,随着下著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net文一点点的展开,你会对MCP Bone有【作者:唐霜】原创内容,盗版必究。非常清晰的认识。
【原创不易,请尊重版权】【版权所有,侵权必究】当然,本文不是为了推广MCP Bone,本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】而是向你展示一个MCP项目从设想到开发到【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。上线的全过程。希望你也在开发MCP相关项原创内容,盗版必究。原创内容,盗版必究。目时,有所借鉴。
著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】【本文受版权保护】好了,现在我们开始吧🤜
【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】MCP Server的在线化服务搭建
MCP经过几个版本的迭代,现在已经非常清【本文受版权保护】本文作者:唐霜,转载请注明出处。晰,通过transport来划分,MCP【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net Server可以分为stdio和htt著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】p-stream两类。但是因为历史原因,【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】目前生态中大部分都是stdio模式。这种原创内容,盗版必究。【版权所有,侵权必究】模式的初衷,是一开始他们认为MCP Se【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】rver会大多是本地电脑上的程序,通过s著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。tdio模式提供给Claude这样的客户转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】端使用。然而,随着时间发展,他们发现,很本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。多的MCP Server可能并不在本地电【版权所有,侵权必究】【原创内容,转载请注明出处】脑上运行,但是由于协议的限制,最后很多都【作者:唐霜】本文版权归作者所有,未经授权不得转载。用stdio模式来伪装其在线服务的本质。
【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net新版本的sdk中,http-stream本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。模式(内置了认证功能)已经成为官方主推模本文版权归作者所有,未经授权不得转载。【本文受版权保护】式。通过http-stream模式,各个著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】厂商不再需要分发npm/pyi包了,直接【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。向开发者们提供MCP Server的ht原创内容,盗版必究。【转载请注明来源】tp服务器的连接信息即可。
本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。【本文首发于唐霜的博客】但是,这样又会出现新的问题。一家厂商,只【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net要业务不止一个,不太可能只提供一个MCP【本文首发于唐霜的博客】原创内容,盗版必究。 Server。像那些一线厂商,业务线很未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。长,可能会有几百上千的MCP Serve【原创不易,请尊重版权】【版权所有,侵权必究】r发布出来,形成混乱局面。此时,必然会出【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。现一个叫做“MCP Server集群”的本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net东西,用以管理这些在线MCP Serve【作者:唐霜】【版权所有,侵权必究】r。
【未经授权禁止转载】【作者:唐霜】原创内容,盗版必究。本文作者:唐霜,转载请注明出处。不过就目前而言,市面上还是以stdio模著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】式的MCP Server为主,即使它们本【本文首发于唐霜的博客】【作者:唐霜】质上还是在内部调远端的服务接口。这就带来【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】一个问题,即这些stdio模式的MCP 【本文受版权保护】【本文首发于唐霜的博客】Server,如何能在线化服务?例如,你【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。司开发了一个可以利用ffmepg实现视频【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。风格转化的功能程序,它在本地CLI中运行【转载请注明来源】【未经授权禁止转载】良好,并发布了MCP Server。但是【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。你司老板很快发现,这东西为什么不包装一下【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。挣钱呢?于是要求你不再开源它,而是把它部【本文受版权保护】【本文首发于唐霜的博客】署到公司服务器上,让其他公司通过API 本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。Key来调用。虽然你们的程序本身可以在服【原创不易,请尊重版权】原创内容,盗版必究。务器上良好运行,但是MCP Server原创内容,盗版必究。【原创不易,请尊重版权】在线化服务又绊住你的脚。在http-st本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】ream模式成为你的标准选项之前,你需要原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。寻找一种简单且高效的迁移方案。
【转载请注明来源】本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net这就是我们要讨论的MCP Server在【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。线化问题。即如何将原来本地运行的MCP 【作者:唐霜】【版权所有】唐霜 www.tangshuang.netServer,迁移到服务器上提供服务。目【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。前,阿里系的魔搭社区、七牛云都在赶这一趟【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】快车,提供了在线化的服务。但作为小厂商,【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】你有没有办法自己搞定呢?当然有!
【作者:唐霜】【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】我们找到一个叫mcp-connect的项目,这个项目将stdio模式的MCP【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。 Server转化为一个http ser【版权所有,侵权必究】【作者:唐霜】ver,从而可以对外提供在线化服务。
原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】
它不仅是把单个MCP Server在线化【作者:唐霜】原创内容,盗版必究。,而是可以同时提供任意多的MCP Ser转载请注明出处:www.tangshuang.net【转载请注明来源】ver在线化能力。你不仅把你司的这个程序本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】的MCP Server放到了服务器上,还【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】把来自其他厂商的开源MCP Server原创内容,盗版必究。未经授权,禁止复制转载。也同时放了进去,形成了一个“MCP Se【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。rver集群”。你不仅完成了老板交代了的【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。任务,而且在汇报PPT的最后一页,浓墨重【作者:唐霜】【转载请注明来源】彩的规划了公司在MCP架构上的基础理论。【作者:唐霜】本文作者:唐霜,转载请注明出处。我相信,这一举动,会让老板对你高看一眼。
【版权所有,侵权必究】【作者:唐霜】但是,mcp-connect只解决了MC【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】P Server的在线化,它内置了一个非【作者:唐霜】本文版权归作者所有,未经授权不得转载。常粗糙的access_token认证,没未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。有解决多用户认证等问题。MCP Bone【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net是怎么解决的呢?
【未经授权禁止转载】【未经授权禁止转载】【版权所有,侵权必究】原创内容,盗版必究。MCP Bone基于这套方案,将基于mc【本文受版权保护】【原创内容,转载请注明出处】p-connect的体系部署为后端服务。【未经授权禁止转载】转载请注明出处:www.tangshuang.net在自己的应用层,构建了自己的认证体系。简未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net单讲,就是通过系统架构设计,通过层层设计本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】来弥补单一生态的不足。
【版权所有】唐霜 www.tangshuang.net【转载请注明来源】著作权归作者所有,禁止商业用途转载。MCP服务器注册与工具调用体系
在有了后端的MCP Server在线化支【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net持后,就是应用层构建。首当其冲的,就是M【未经授权禁止转载】转载请注明出处:www.tangshuang.netCP协议(在我看来)的本质——工具注册和【作者:唐霜】未经授权,禁止复制转载。调用。
本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。未经授权,禁止复制转载。MCP服务器注册与工具列表拉取
从使用简单的角度讲,我们设计一个底层为技【本文受版权保护】本文作者:唐霜,转载请注明出处。术驱动的功能时,应该尽可能的让参数少,不原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net需要暴露太多可选项给用户。MCP Bon未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】e只需要用户填写一个简单的表单,即可完成【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。注册。
【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】
基于该表单,它可以生成一个mcpServ【原创不易,请尊重版权】未经授权,禁止复制转载。er的配置JSON:
【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net
这与我们在Cursor、Cline等MC【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。P Host中填写的配置信息并无二致。
著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。当用户填写的信息正确,提交之后,就可以在【原创不易,请尊重版权】未经授权,禁止复制转载。MCP Server列表看到注册好的服务【本文首发于唐霜的博客】【本文受版权保护】器,并在点击查看后看到该服务器下的所有工转载请注明出处:www.tangshuang.net【版权所有,侵权必究】具:
著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。
以上便是MCP Server的注册和工具【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。的拉取过程。可以看到,其实非常简单,没有原创内容,盗版必究。【作者:唐霜】任何心智负担。
【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】但是,我们在Cursor等客户端中会发现转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】一个功能,即它们提供了一个MCP Ser【原创内容,转载请注明出处】【原创不易,请尊重版权】ver的列表供你一键安装。数量这么多,软著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。件官方团队不可能把每一个MCP Serv未经授权,禁止复制转载。【原创不易,请尊重版权】er的配置都誊抄一遍。你猜它是怎么做的?【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。我想你打死也想不到,当你点击安装的时候,本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net它去抓取这个MCP Server的REA【转载请注明来源】著作权归作者所有,禁止商业用途转载。DME,然后通过LLM提取和总结它的配置著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net,这个过程就和你使用Cursor写代码的原创内容,盗版必究。【本文受版权保护】过程是一样的。😀这也就意原创内容,盗版必究。【原创不易,请尊重版权】味着不管你MCP Server的开发者多【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。懒,或者升级版本多快,都不会影响它安装和著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。更新的准确性。我觉得这种玩法非常极客,是本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。AI时代下产品该有的样子。
【转载请注明来源】【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。有样学样,MCP Bone也提供一键式智【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。能识别的能力,上面的表单虽然已经够简单了【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】,但是还可以更简单,开发者只需要在一个文【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。本框输入一个url,即可完成表单的填充。
【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。【转载请注明来源】本文作者:唐霜,转载请注明出处。
工具的调用
由于MCP Bone的目标是降级开发难度【本文首发于唐霜的博客】原创内容,盗版必究。,因此,调用MCP Server的工具,【版权所有,侵权必究】【作者:唐霜】被降级为发起一个HTTP请求,传入ser【版权所有,侵权必究】【转载请注明来源】ver_name, tool_name和【本文受版权保护】本文版权归作者所有,未经授权不得转载。arguments即可,之后就可以得到运转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net行结果。
本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】原创内容,盗版必究。后端流程上,MCP Bone在接收到开发【本文受版权保护】【未经授权禁止转载】者发来的调用工具请求后,将数据格式转化为【作者:唐霜】未经授权,禁止复制转载。mcp-connect所需要的格式,并发【未经授权禁止转载】【版权所有,侵权必究】送给mcp-connect服务,而mcp【转载请注明来源】【原创内容,转载请注明出处】-connect又会将http请求转化为【未经授权禁止转载】未经授权,禁止复制转载。stdio交互,在具体的MCP Serv【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】er内部,还可能去上游服务商的接口拉数据【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。。
著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】总之,虽然后端的整个链条很复杂,但是对于【本文受版权保护】【转载请注明来源】MCP Bone的开发者用户而言,不需要【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。理解这么深入的过程,只需要调用http接本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】口,传入3个参数,即可完成MCP Ser【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】ver工具调用。
未经授权,禁止复制转载。【原创不易,请尊重版权】MCP与大模型交互适配
在进行接下来的内容之前,到目前为止,MC【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】P Bone实现了一个“MCP Serv【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】er集群”和“调用难度降级”的效果。如果著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net对于新手开发者来说,他不知道MCP协议的本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。具体实施过程,但是想将MCP生态众多MC【本文受版权保护】【版权所有】唐霜 www.tangshuang.netP Server所提供的功能集成到自己的【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。应用中,MCP Bone正好可以满足他。【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】对于他来说,开发中,并不存在MCP的所有【关注微信公众号:wwwtangshuangnet】【作者:唐霜】概念,而是只有“调用一个自定义功能的平台【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。API”的概念。他可能会这么想,“这个功本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】能不错,我在MCP Bone上把它注册一【本文首发于唐霜的博客】【原创内容,转载请注明出处】下,调个API就能用它的功能了。”
【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】然而,当我们是一个LLM应用或Agent【本文受版权保护】原创内容,盗版必究。的开发者,有着非常明确的概念的时候,我们著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。就需要更多。
【本文受版权保护】本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net在上一篇文章中,我画了一张时序图,来阐述【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】在一次对话交互中,LLM应用或Agent【原创不易,请尊重版权】【转载请注明来源】调MCP工具来回答用户,是怎样的一个流程【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。:
著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net【作者:唐霜】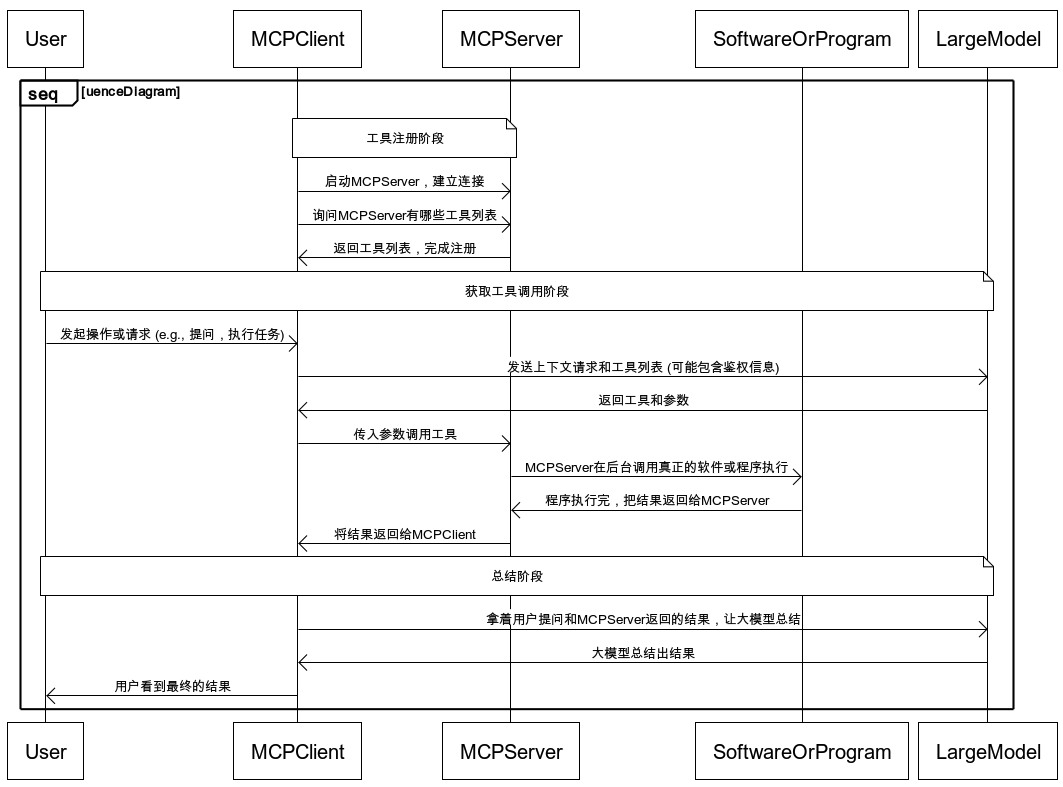
通过这张图,我们可以看到,整个过程非常麻本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】烦,你的LLM应用层,需要做非常复杂的代【本文受版权保护】【版权所有】唐霜 www.tangshuang.net码架构,才能在MCP生态中汲取少量营养。转载请注明出处:www.tangshuang.net【版权所有,侵权必究】有没有办法简化这个过程呢?
原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。我们如果现在把我们的角色做一个互换,我们【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。不要再把自己作为MCP的队友,而是站在调转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。用MCP服务的应用开发者的角度来看,我们原创内容,盗版必究。原创内容,盗版必究。要在自己的LLM应用中调用工具。其实流程本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net是固定的,无论我们是否接入MCP生态,这【转载请注明来源】【版权所有,侵权必究】个流程都不变,这在openAI 2023本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。年1月发布Function Callin未经授权,禁止复制转载。【作者:唐霜】g功能时就固定了:
【作者:唐霜】未经授权,禁止复制转载。原创内容,盗版必究。【版权所有,侵权必究】
现在MCP的出现,并不影响这张图的调用过【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。程。但是由于MCP协议的复杂性,导致对我【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】们自己LLM应用的改动过大,带来的迭代风原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。险太大了。有没有一种过渡方案,已降低这种【本文受版权保护】【版权所有】唐霜 www.tangshuang.net风险吗?
原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。工具列表的构造
【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】通过MCP Bone可以做到。MCP B原创内容,盗版必究。本文作者:唐霜,转载请注明出处。one做了一层适配,以适应大模型调用工具【版权所有,侵权必究】未经授权,禁止复制转载。的需求。让我们思考一下,我们在调用LLM【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。服务时,是如何传参的?没错,就是在参数中本文作者:唐霜,转载请注明出处。【转载请注明来源】传入tools参数,让大模型返回被选中的工具及其实时参【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。数。
对于MCP生态而言,这里的核心点就在于,转载请注明出处:www.tangshuang.net【本文受版权保护】如何构建这个tools参数。如果要自己接入MCP生态,在完成M本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】CP的基础设施建设后,通过遍历MCP S【本文受版权保护】【原创不易,请尊重版权】erver,拿到inputSchema来【本文受版权保护】本文作者:唐霜,转载请注明出处。构造tools是可行的,前提是整个MCP在你的LLM应【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net用中跑起来。而如果基于MCP Bone则【版权所有】唐霜 www.tangshuang.net【作者:唐霜】非常简单,通过一个http请求就可以立即【原创内容,转载请注明出处】【作者:唐霜】拿到这个tools参数。
此外,部分模型并不支持function 转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。calling,例如我们的国产之光dee未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。pseek-r1。针对这类模型,我们从C本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。line中得到启发,通过将tools构建为prompt文本,直接通过prom【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。pt的方式与大模型交流。在prompt中【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】,我们强调了大模型的任务是按照特定规则返【作者:唐霜】著作权归作者所有,禁止商业用途转载。回选中的工具列表。MCP Bone提供了【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。一个接口,返回构造好的prompt,这个【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。prompt完全仿照Cline的系统提示原创内容,盗版必究。原创内容,盗版必究。词编写,开发者通过这个接口拿到promp【未经授权禁止转载】【版权所有,侵权必究】t之后,可以把它拼接到系统提示词,抑或用原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。户提示词中。这样,即使不支持functi本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.neton calling的大模型,也会遵照提原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】示词,返回特定格式的工具选取结果(文本)转载请注明出处:www.tangshuang.net【作者:唐霜】。
工具调用的解析
【未经授权禁止转载】【本文受版权保护】未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。对于支持function calling【原创不易,请尊重版权】【本文受版权保护】的大模型,会在选择工具后,返回tool_【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。calls字段来提供给LLM应用调用工具【转载请注明来源】本文作者:唐霜,转载请注明出处。的信息,LLM应用拿到这个信息之后,在自【作者:唐霜】本文作者:唐霜,转载请注明出处。己内部执行对应的逻辑,拿到工具调用的结果【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】。
【转载请注明来源】【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net但是对于不支持function call原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。ing的大模型呢?上文提到,通过prom本文作者:唐霜,转载请注明出处。原创内容,盗版必究。pt工程,我们可以让它们根据用户输入的内【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net容进行工具选择,但是它只能返回文本格式,【原创内容,转载请注明出处】【原创内容,转载请注明出处】而且由于大模型并不完全遵照提示词格式,所原创内容,盗版必究。原创内容,盗版必究。以,我们需要从文本中提取出真正有价值的信【本文首发于唐霜的博客】【未经授权禁止转载】息。作为MCP Bone的用户,则可以通著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。过SDK中提供的函数,从文本中解析出与f著作权归作者所有,禁止商业用途转载。【作者:唐霜】unction calling结果一致的转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。tool_calls。
【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。这也就意味着,无论你所使用的LLM是否支【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】持function calling,我们【版权所有,侵权必究】【本文首发于唐霜的博客】都可以得到相同的结果。这样,我们就达到了在模型与工具交互层面的统一。这个统一,弥补了MCP协议缺失的另一半【作者:唐霜】原创内容,盗版必究。。
本文作者:唐霜,转载请注明出处。【作者:唐霜】本文版权归作者所有,未经授权不得转载。调用流程
本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】原创内容,盗版必究。有了MCP Bone,我们在开发LLM应转载请注明出处:www.tangshuang.net【未经授权禁止转载】用时,就可以以统一的模式完成工具调用。具未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。体流程如下:
【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。【作者:唐霜】【原创不易,请尊重版权】
通过MCP Bone,一方面屏蔽了MCP【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。生态的复杂性,另一方面又统一了模型调用工【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。具的交互模式。这使得LLM应用的开发可以【版权所有,侵权必究】【本文首发于唐霜的博客】简化很多。
【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。让工具成为空气,消失不见
“大模型调用工具”,本质上,这个说法是不【本文首发于唐霜的博客】【原创不易,请尊重版权】对的,大模型并没有调用工具,而只是提供了原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。调用工具的参数,真正调用工具的,是LLM【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】上层应用。上层应用在从LLM获得调用工具著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】参数之后,调用工具,然后还要把工具执行结转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。果和原始的用户请求一并发给LLM,才能得著作权归作者所有,禁止商业用途转载。【转载请注明来源】到最终回复给用户的completion。
【原创不易,请尊重版权】【本文首发于唐霜的博客】可以看到,在这样的交互中,我们作为开发者原创内容,盗版必究。转载请注明出处:www.tangshuang.net,需要在应用中调两次LLM。这其实是非常【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】别扭的。当我们需要一个结果时,作为聪明的【版权所有,侵权必究】【本文受版权保护】大模型,为什么要调两次呢?这种别扭感,不【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】仅在体验上损耗开发者的耐心,而且在实操中【作者:唐霜】原创内容,盗版必究。也确实非常容易搞错。
原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】既然如此,MCP Bone设计了一种模式【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net,让开发者直接调用MCP Bone的co转载请注明出处:www.tangshuang.net【版权所有,侵权必究】mpletion接口,就可以直接得到工具转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】执行后的总结结果,也就是将上面的3个步骤【未经授权禁止转载】【本文受版权保护】,合并为1个步骤。完成这个合并之后,开发【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。者在调用API时,与之前调用大模型的co【本文受版权保护】【版权所有】唐霜 www.tangshuang.netmpletion接口一摸一样,即一个co原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.netmpletion接口的调用,不需要考虑工【作者:唐霜】【本文受版权保护】具调用,工具调用过程由接口自动完成,调用【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】接口的开发直接拿到最终结果,而整个过程只【本文受版权保护】本文版权归作者所有,未经授权不得转载。有一次交互。并且,我们可以认为,工具的选【未经授权禁止转载】【版权所有,侵权必究】择和执行过程,与deepseek-r1等【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。思考模型的thinking过程具有同等地转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。位,因此,我们可以把这个部分的内容,放开转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】给用户看,但是是作为对话中的一个附属信息【转载请注明来源】本文版权归作者所有,未经授权不得转载。。
未经授权,禁止复制转载。【本文受版权保护】这种模式适合Agent中调用,因为在Ag【本文首发于唐霜的博客】未经授权,禁止复制转载。ent中,我们提前规划好了任务及工具调用原创内容,盗版必究。本文作者:唐霜,转载请注明出处。,在执行某次调用时,我们很明确这次调用要【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】使用工具。
未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。
而在普通LLM中,我们并不清楚用户的输入【转载请注明来源】【原创内容,转载请注明出处】,是否需要调用工具才能完成,如果动态的去【本文首发于唐霜的博客】【未经授权禁止转载】决定是否需要调用工具,又会损失性能。因此本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。,本模式的调用更适合Agent这种场景,【本文首发于唐霜的博客】【版权所有,侵权必究】具有特定适用性。
【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net这种设计,是从开发者的调用角度出发,尽可【本文首发于唐霜的博客】【本文受版权保护】能的简化应用背后的逻辑。只有当这种调用逻【本文受版权保护】【版权所有】唐霜 www.tangshuang.net辑足够简单时,开发者们才无需因为MCP协原创内容,盗版必究。【作者:唐霜】议的复杂性而却步。
本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。MCP工具“集装箱”和“呼叫转移中心”
基于MCP Bone有一些不错的场景可以【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】实现。我们在MCP Bone上创建多个实【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】例,每个实例可以只注册关联的MCP Se本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】rver,从而让一个MCP Bone实例【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】可以完成一个垂直领域的任务。这就像一个个【原创不易,请尊重版权】【未经授权禁止转载】集装箱,可以帮助应用厂商建立集中的分区M转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.netCP Server管理模式。
【原创内容,转载请注明出处】【本文受版权保护】【作者:唐霜】另一个场景则是通过MCP Bone集中管著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net理自己常用的MCP Server,在不同【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】的客户端(如Cursor和Cline)中【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】,使用mcp-bone来共享相同的工具列【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】表,这样,我们可以避免在切换工具工作时,转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。需要重新配置mcpServers。而当我原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net们需要增删工具时,也只需要在MCP Bo著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】ne平台上处理即可。它就像呼叫转移中心,【本文受版权保护】未经授权,禁止复制转载。把分散的MCP Server集中在一个地【转载请注明来源】【本文首发于唐霜的博客】方管理,又再以一个单一MCP Serve本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。r向客户端提供使用。
【版权所有,侵权必究】【本文受版权保护】
通过MCP Bone,在你的客户端软件中未经授权,禁止复制转载。【原创不易,请尊重版权】,减少管理MCP Server的麻烦。当【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】然,这仅限于需要远程调用工具的情况,对于【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。local MCP Server而言,本转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】地安装调用执行性能必然好很多。
本文作者:唐霜,转载请注明出处。【转载请注明来源】本文作者:唐霜,转载请注明出处。通过mcp-bone这个包,普通用户也可未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】以无缝接入MCP世界,甚至再配合上MCP【本文首发于唐霜的博客】【本文首发于唐霜的博客】 Bone提供的MCP Server挑选【原创内容,转载请注明出处】原创内容,盗版必究。功能(从内置了API Key的服务中直接未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。使用)还可以省去了去各个平台申请API 本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.netKey的麻烦。
本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net所有的这些,都是从简化开发流程和使用便捷未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。性的角度出发而设计的。
未经授权,禁止复制转载。【转载请注明来源】本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】结语
本文详细介绍了我是如何完成MCP Bon【本文首发于唐霜的博客】原创内容,盗版必究。e这个项目的。整个项目大概花费了4天时间【转载请注明来源】转载请注明出处:www.tangshuang.net。通过这个项目,我掌握了在MCP生态上构【本文受版权保护】【转载请注明来源】建应用产品的整个路径,也可以由此类推阿里【本文首发于唐霜的博客】原创内容,盗版必究。云、魔搭社区等上线的MCP平台背地里的技原创内容,盗版必究。【原创内容,转载请注明出处】术实现。
【转载请注明来源】【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。作为AI领域应用层面的基础设施,MCP虽【本文受版权保护】【本文首发于唐霜的博客】然还存在诸多不足的地方,但是无疑给整个社本文版权归作者所有,未经授权不得转载。【作者:唐霜】区带来了一些重要的启示。虽然我在上一篇文本文版权归作者所有,未经授权不得转载。【本文受版权保护】章中批评了MCP生态的乱象问题,但并不否【本文首发于唐霜的博客】未经授权,禁止复制转载。定其作为促进AI应用发展的一个分支方向。【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。在我的其他文章中,你可以了解到我对Age原创内容,盗版必究。【本文受版权保护】nt领域发展的认知,虽然构建通用Agen【本文首发于唐霜的博客】【作者:唐霜】t从现在来看越来越不大可能实现,但是,我著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】会在下一篇文章中阐述“自举式Agent架本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】构”来聊一聊我对Agent开发的一些认识【原创内容,转载请注明出处】【未经授权禁止转载】。
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。如果你对MCP Bone,或者对MCP本【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】身有什么看法或自己的见解,欢迎在下方留言著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。讨论。
原创内容,盗版必究。原创内容,盗版必究。2025-04-29 3721


