如果你和我一样,最近一直在做Agent试【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net探,就会对第三方大模型非常纠结,随着调用【关注微信公众号:wwwtangshuangnet】【本文受版权保护】次数的增加,银子也是白花花的流淌,有没有【作者:唐霜】【版权所有】唐霜 www.tangshuang.net省钱的办法呢?当然有,就是在CPU上跑大【本文首发于唐霜的博客】【本文首发于唐霜的博客】模型。
本文作者:唐霜,转载请注明出处。【作者:唐霜】一般的GPU服务器,一个月下来起码也要2著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。000左右,算下来,不如调第三方服务的A本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.netPI划算,但是调第三方服务存在着数据泄露【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。风险,而且随着用户增长,按tokens计【原创内容,转载请注明出处】未经授权,禁止复制转载。价的方式,也会消耗如流水,内心滴血。一群本文版权归作者所有,未经授权不得转载。【转载请注明来源】大佬找到了省钱的办法,就是让大模型在AM本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。D的GPU,甚至在CPU上跑。如果在CP【原创内容,转载请注明出处】【本文首发于唐霜的博客】U上跑,我们只需要租一台核心过得去内存比【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】较大的服务器即可,每个月的价格瞬间降到几【本文受版权保护】【版权所有】唐霜 www.tangshuang.net百块,甚至打折时期,花千把来块就可以租一著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。年。本文主要来聊一聊,如何让LLM运行在本文作者:唐霜,转载请注明出处。【本文受版权保护】CPU上,以极限姿势压榨服务器,达到省钱转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】目的。不是GPU不够好,而是CPU性价比原创内容,盗版必究。未经授权,禁止复制转载。更高。
【作者:唐霜】【转载请注明来源】本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】想要让LLM在CPU上运行,核心要做到两本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】个点:
未经授权,禁止复制转载。原创内容,盗版必究。本文作者:唐霜,转载请注明出处。- 高效的CPU运算架构 【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。
-
对大模型的性能压榨 【转载请注明来源】【本文受版权保护】本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。
只要做到这两点,再配合一台硬件上还不错的本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】普通CPU服务器,就可以让我们获得一个性【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net价比最大化的本地大模型服务。
本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net针对第一点,社区大佬Georgi Ger本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。ganov想到了用c/c++重新实现模型原创内容,盗版必究。原创内容,盗版必究。框架,在想到这个点子后,经过一个晚上的奋战之后,他推出了llama.cpp项目。
本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net
Georgi Gerganov
【原创不易,请尊重版权】原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。该项目主要用于运行大模型,完成推理过程。【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net使用c/c++的优势在于:
【版权所有,侵权必究】【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】- 无需任何额外依赖,相比 Python 代【原创不易,请尊重版权】【本文受版权保护】码对 PyTorch 等库的要求,C/C【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。++ 直接编译出可执行文件,跳过不同硬件未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】的繁杂准备; 【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net
- 支持 Apple Silicon 芯片的【本文首发于唐霜的博客】【未经授权禁止转载】 ARM NEON 加速,x86 平台则【关注微信公众号:wwwtangshuangnet】【本文受版权保护】以 AVX2 替代; 原创内容,盗版必究。原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】
- 具有 F16 和 F32 的混合精度; 本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。
- 支持 4-bit 量化; 【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】
- 无需 GPU,可只用 CPU 运行; 【原创不易,请尊重版权】【转载请注明来源】【本文受版权保护】
- … 著作权归作者所有,禁止商业用途转载。【本文受版权保护】
由于纯 C/C++ 实现,无其他依赖,运【本文首发于唐霜的博客】【原创内容,转载请注明出处】行效率很高,除 MacBook Pro 未经授权,禁止复制转载。【转载请注明来源】外,甚至可以在 Android 上运行。
本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。针对第二点,如何将动则上100B的大模转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】型进行压缩,以可以让普通的CPU机器也可【原创不易,请尊重版权】【原创不易,请尊重版权】以带得动呢?答案是通过“量化”。所谓量化未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。,学术的说是“将连续取值的浮点型模型权重转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net进行裁剪和取舍的技术”,简单讲就是压缩,丢失部分精度,换取空间和【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。性能。Georgi Gerganov提出了自【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】己的量化方案ggml,并在该量化方案被广未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。泛认可后,ggml成为一种量化模型的文件本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】格式。但是,大模型领域发展的太快了,gg【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.netml很快跟不上步伐,于是在2023年8月【转载请注明来源】原创内容,盗版必究。他又推出了改进方案gguf,该方案替代g本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】gml成为最新的量化模型文件格式。而且,著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】目前HuggingFace也大力支持了该【作者:唐霜】【本文受版权保护】格式。当然,除了gguf方案外,还有其他本文作者:唐霜,转载请注明出处。【本文受版权保护】量化方案,例如知名的GPTQ等。总之,经【未经授权禁止转载】【未经授权禁止转载】过量化后的模型,可以提升性能,降低对硬【本文受版权保护】未经授权,禁止复制转载。件资源的要求。
【未经授权禁止转载】【原创不易,请尊重版权】现在,我们有了llama.cpp和ggu【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。f,我们就可以在CPU机器上跑大模型了本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。。
转载请注明出处:www.tangshuang.net【转载请注明来源】不过先不要着急,我们还有杀手锏。虽然ll【原创不易,请尊重版权】【本文受版权保护】ama.cpp是可以直接运行,可是它的运未经授权,禁止复制转载。未经授权,禁止复制转载。行方式有点不那么感冒。毕竟现在很少有人著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】在用c++写业务系统了,所以,我们最好还本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。是能跟我们的应用结合起来便是最好。这【原创不易,请尊重版权】【作者:唐霜】里有两种方案:
【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net- 独立服务,通过RPC或http进行调用 【转载请注明来源】转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】
- 编译为业务系统开发语言支持的模块,直接在【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】代码中调用 【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】
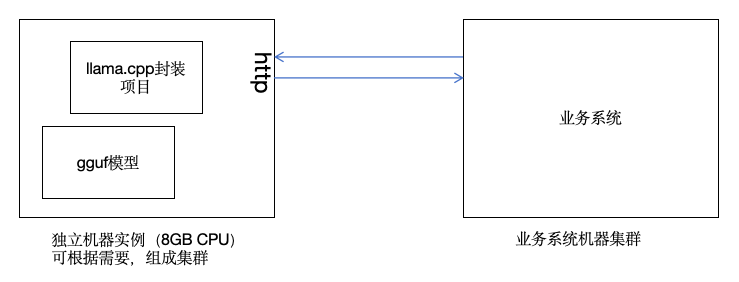
独立服务模式
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net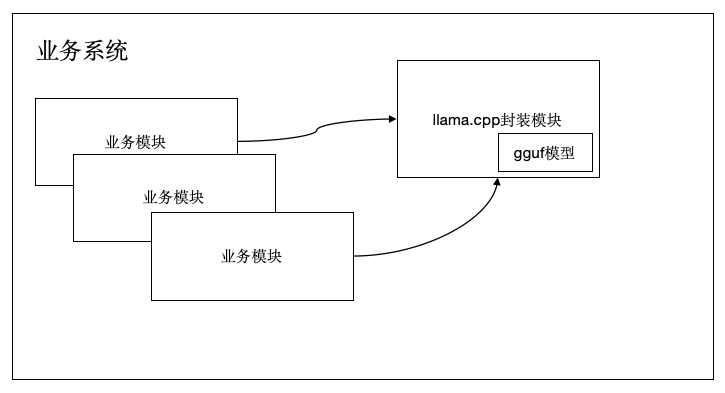
模块封装模式
【原创不易,请尊重版权】【作者:唐霜】未经授权,禁止复制转载。作为前端开发,我也在前人的肩膀上封装了一本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。个库node-llm,你可以使用 npm原创内容,盗版必究。未经授权,禁止复制转载。 install node-llm 来【未经授权禁止转载】【转载请注明来源】安装它。它简化了接口,理解成本极低,可以【未经授权禁止转载】未经授权,禁止复制转载。让前端开发的同学,以最快的速度在node本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。js上启动一个大模型项目。有了它,再配【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】合langchain的js版本,就可以轻【本文首发于唐霜的博客】【本文受版权保护】松搭建自己的知识库等Agent应用。而且未经授权,禁止复制转载。【作者:唐霜】我还融合了之前做的chatglmjs项目【本文受版权保护】本文作者:唐霜,转载请注明出处。,在llama之外,支持chatglm系转载请注明出处:www.tangshuang.net【作者:唐霜】列模型,chatglm的6b模型要求的性本文作者:唐霜,转载请注明出处。原创内容,盗版必究。能在同级别中最低,非常值得一试。
转载请注明出处:www.tangshuang.net【转载请注明来源】原创内容,盗版必究。量化后的模型对硬件的要求降低,但是并不意【本文受版权保护】【原创内容,转载请注明出处】味着随便一台垃圾机器也可以跑起来,如果我著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。们有一台8G内存的大模型,我们可以尝试6本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.netB的量化模型。当然,如果我们有需要,可未经授权,禁止复制转载。【原创内容,转载请注明出处】以升级机器到32G,此时,我们就可以把量本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net化的精度提高一些,以获得效果更好的输出【版权所有,侵权必究】原创内容,盗版必究。。如果我们只有2G内存,还是建议调第三方【原创内容,转载请注明出处】原创内容,盗版必究。接口来的实在。
【作者:唐霜】【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】最后,有人会问,失去精度后,大模型准确性【原创不易,请尊重版权】原创内容,盗版必究。降低,不就失去了意义吗?对于这个问题,著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】我想说的是,我们应该根据自己的需求来选择【本文受版权保护】【版权所有,侵权必究】,不然为什么所有厂商都会提供不同参数量级【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。的模型呢?说明这些厂商们明白,我们在面对【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】不同需求时,所需要的精度是不同的。对于未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。我们做应用开发而言,我们要学会用架构拆分来合理降低成本。当我们一股脑的把所有LLM处理都丢给一本文作者:唐霜,转载请注明出处。【作者:唐霜】个大模型去处理,意味着该模型要承受巨大的【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】服务压力,同时,你的成本也是固定的。但转载请注明出处:www.tangshuang.net原创内容,盗版必究。当我们把不同的处理进行拆分,精度必须高的著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。,分发给智能程度高精度高的大模型去处理,【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net精度要求低的,分发给我们今天搭起来的CP转载请注明出处:www.tangshuang.net原创内容,盗版必究。U上跑的大模型去处理,如此合理分配,就可【转载请注明来源】原创内容,盗版必究。以让我们的成本降低。
【转载请注明来源】著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】【本文受版权保护】对于我们学习、调试期间而言,本着能省则省本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net的性价比观念,自己搭一个本地大模型服务,【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】调通整个Agent之后,再把部分调用切换【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】到付费大模型去,如此,岂不省了很多?
未经授权,禁止复制转载。【本文受版权保护】2024-04-10 4073


