市面上有不少用于推进某些业务的表单设计器【本文首发于唐霜的博客】【转载请注明来源】,例如轻流、有道云等,它们的理念是用一个【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。很小的表单和流程,解决企业的细小业务,可著作权归作者所有,禁止商业用途转载。【转载请注明来源】以理解为问卷收集基础上的流转能力。但是,【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net对于开发者而言,往往需要面临比这类细小业本文作者:唐霜,转载请注明出处。【转载请注明来源】务复杂的多得多的业务流程,以及流程节点上转载请注明出处:www.tangshuang.net原创内容,盗版必究。的表单。我在该领域持续研究了三年多,这些本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net研究有静态的,也有动态的。所有动态化,有【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。两个角度,从产品运营人员的角度,处于流程【未经授权禁止转载】【转载请注明来源】中的表单可能随时需要调整一些策略,例如字【版权所有】唐霜 www.tangshuang.net【本文受版权保护】段的限制,或者某些字段的增删;从开发人员【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。的角度,我们不能用代码限定死表单及其囊括著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】各方面的内容,而是需要在前后端配合下,异【版权所有,侵权必究】【未经授权禁止转载】步的生成表单的界面、交互、业务逻辑等等。著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】本文将梳理我的设计思路。
转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】【原创内容,转载请注明出处】动态建模
对于表单而言,我推崇先建模,当然,建模并【原创内容,转载请注明出处】未经授权,禁止复制转载。不只适用于表单场景,任何场景都适用,只是【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net需要考虑成本。但在建模时,我们往往需要去【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。思考,在业务层面,我们需要什么,在交互层【原创不易,请尊重版权】【本文首发于唐霜的博客】面我们需要什么。虽然这两类东西是不同的,【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】但是在最终的产品形态上,它们不可能分离,【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】只能放在一起,因此,在面对用户时,我们需原创内容,盗版必究。【转载请注明来源】要有一个较强的分类的设计,让用户在使用使转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】不会懵圈。当我们尝试去动态化建模时,就不原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net得不考虑这些问题。
【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。元数据
我们的模型是由字段组成的,但是字段并不是【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。最小单位。用于描述字段的数据,我们称为元原创内容,盗版必究。转载请注明出处:www.tangshuang.net数据,它是dataset级别的数据集,组【原创不易,请尊重版权】【原创内容,转载请注明出处】成字段元数据的,我们称为属性,是atom【原创内容,转载请注明出处】未经授权,禁止复制转载。级别的数据。每一个属性,往往只存在值,而本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】不会再有其更深的元数据,因为我们会以定义【本文受版权保护】【转载请注明来源】的形式赋予其意义,而非描述它的意义。
原创内容,盗版必究。【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】我个人将字段元数据分为3个部分:字段的存储性质;字段的逻辑性质;字段的交【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】互性质。
【本文受版权保护】【未经授权禁止转载】本文作者:唐霜,转载请注明出处。字段的存储性质可以理解为如果我们要把该字【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net段存储在数据库中所需要的属性,当我们在使【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】用 create table 语句时,我【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。们就会规定字段的存储性质,例如字段的数据本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。类型、默认值、长度、名称文本、字段解释(本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】含义)等等。这些信息是固定的,对于字段而未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。言,无论在任何场景下,都是死的,不变的。【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】除了上面列出来的这些和数据库对应的属性,著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。其实我们还会有一些和业务中关联的属性,不本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net同的业务系统,其关联的属性必然不同。例如【转载请注明来源】未经授权,禁止复制转载。在付款系统中,对于数值,它可能还存在一个转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。是否代表金额的属性,因为普通的数字和金额【未经授权禁止转载】【原创不易,请尊重版权】在使用过程中,有非常大的区别;例如对于账【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】户类型的字段,你需要考虑,它是存单个,还本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。是多个账户;例如对于日期字段,你需要考虑【本文首发于唐霜的博客】【原创不易,请尊重版权】是否要使用UTC,还是使用字符串。不同业【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。务系统中,我们都会通过不同的属性来定义我本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。们的字段,而这些定义具有强制性,在本业务【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。系统中,必须如此,不可更改。
未经授权,禁止复制转载。【转载请注明来源】原创内容,盗版必究。本文作者:唐霜,转载请注明出处。字段的逻辑性质,也可以理解为在业务流程中【作者:唐霜】【本文首发于唐霜的博客】随着业务推进而带来的逻辑变更。例如某个字【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。段的必填属性,在不同业务阶段,其必填逻辑【本文受版权保护】【关注微信公众号:wwwtangshuangnet】是不一样的。字段的逻辑性质主要是一些校验【转载请注明来源】【原创内容,转载请注明出处】属性,例如必填、长度、数值区间、数值位数未经授权,禁止复制转载。【版权所有,侵权必究】,以及在不同流程阶段该字段的可见性等等。【作者:唐霜】【原创不易,请尊重版权】这些属性也是本业务系统中规定的,但是具有【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】可变性,不同场景不相同。对于我们动态化设【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】计而言,实际上这个部分是最难的,也是用户本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】们最想要的。用户们会觉得这类需求并不复杂【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。,因为它们会从结果出发,但是对于研发而言未经授权,禁止复制转载。【作者:唐霜】,这类需求是最复杂的,因为它设计前后端无本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net数的架构和设计细节。
【作者:唐霜】【原创内容,转载请注明出处】【未经授权禁止转载】字段的交互性质可以理解为字段的呈现性质,本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】这些性质往往不影响业务推进,主要是对界面原创内容,盗版必究。【版权所有,侵权必究】和交互产生影响,不存在也无所谓。例如对日【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】期的格式进行规定的属性,对数值的格式化的本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】属性,对字段提交到后端接口时所要呈现的结本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。构或格式的属性等等。这些属性虽然不是最重【作者:唐霜】【本文受版权保护】要的,但是在系统中是最好实施的,最容易看本文作者:唐霜,转载请注明出处。【本文受版权保护】见成果的,因此我是比较推荐先从这个部分的原创内容,盗版必究。本文作者:唐霜,转载请注明出处。动态化实施,慢慢扩展和研究全部的动态化。
【本文首发于唐霜的博客】【版权所有,侵权必究】元模型
模型是基于字段集搭建的描述体,但具体到某原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】一模型,我们会发现,它是多态的,场景化的【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。。或者换一种解释,同一个对象,在不同场景【本文首发于唐霜的博客】原创内容,盗版必究。下,它所拥有的字段、逻辑,可能不一样。例【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。如一个付款,在通常情况下,我们需要呈现它【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】的全部字段,而且往往还会将它关联的双边付【本文首发于唐霜的博客】【原创不易,请尊重版权】款银行作为子信息。但是,在某些场景下,我转载请注明出处:www.tangshuang.net【版权所有,侵权必究】们并不需要关心它的全部字段,而是只呈现它【未经授权禁止转载】转载请注明出处:www.tangshuang.net的个位数字段。同样是一个付款,不同场景下【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net所拥有的东西不同,这似乎不成立,难道它们原创内容,盗版必究。【转载请注明来源】是不同的付款?实际上,我们知道,付款还是【版权所有】唐霜 www.tangshuang.net【转载请注明来源】那一个付款,其背后的实质是一样的,只不过【未经授权禁止转载】【原创内容,转载请注明出处】在不同场景下,它披上的衣服不同,遮住了不【转载请注明来源】著作权归作者所有,禁止商业用途转载。同的部分。我们将有关付款的本质模型称为元未经授权,禁止复制转载。原创内容,盗版必究。模型,即模型的模型。而具体某个场景的模型【转载请注明来源】【作者:唐霜】,则是其元模型的收窄,这和我们编程中的子【版权所有】唐霜 www.tangshuang.net【作者:唐霜】类型相反。
本文作者:唐霜,转载请注明出处。原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。梳理元数据的表格
在开始编程之前,我们要通过excel表格本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。,梳理现有系统的元数据,这在将来我们完成【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】动态化开发后,直接利用该excel进行导【本文受版权保护】【本文首发于唐霜的博客】入进行动态化系统的初始化也有帮助。梳理元本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net数据其实很简单,你可以理解为用excel著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。表格把每个字段的各个方面描述一下,而且一【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。定要细,拆分也要准确。
【原创不易,请尊重版权】【未经授权禁止转载】
这里举了一个非常简单的例子。我们在开始开原创内容,盗版必究。【本文首发于唐霜的博客】发之前,要去梳理这些元数据。而且不同的业著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。务系统,这些元数据都会完全不同,且随着开【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。发的深入,我们还会在继续深化,增加新的属【作者:唐霜】【版权所有】唐霜 www.tangshuang.net性,或者将原来的一个属性拆分为多个属性。
【作者:唐霜】【转载请注明来源】设计元数据Schema结构
由于我们的目标是动态化,因此,我们需要把未经授权,禁止复制转载。【本文首发于唐霜的博客】这些元数据信息存储在后台,从而可以实现在【版权所有,侵权必究】转载请注明出处:www.tangshuang.net线的编辑功能。 我们要将字段的元数据存储【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】在数据库中,在管理平台上可以编辑它们,并【本文受版权保护】原创内容,盗版必究。完成保存,同时,在用户界面拉取出来进行表转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。单的渲染。从元数据的特征来看,它天生是一【版权所有,侵权必究】转载请注明出处:www.tangshuang.net种键值对的非关系型数据,因此使用NoSQ原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】L数据库是一个不错的选择。我们可以把具有【版权所有,侵权必究】【作者:唐霜】嵌套结构的数据存储在一个数据中,同时,元转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net数据属性又不会用于查询。因此,有一种扁平【原创内容,转载请注明出处】【原创内容,转载请注明出处】的描述性强的数据格式非常有必要,我们称该本文作者:唐霜,转载请注明出处。原创内容,盗版必究。数据格式为Schema,即在特定场景下的产品描述协议。
【未经授权禁止转载】【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net【本文受版权保护】而基于Schema的描述格式也非常重要,原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】这里面有非常多不确定的动态因素,而大部分【未经授权禁止转载】本文作者:唐霜,转载请注明出处。数据格式都是静态的。如何才能更好的适应这【版权所有】唐霜 www.tangshuang.net【本文受版权保护】种意图呢?我们需要设计一门动态DSL语言【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。到我们的Schema中,用于表述具有动态未经授权,禁止复制转载。【未经授权禁止转载】逻辑的部分,特别是在上面提到的字段的逻辑【本文受版权保护】【本文受版权保护】性质。
【转载请注明来源】本文版权归作者所有,未经授权不得转载。【作者:唐霜】设计动态DSL语言
我们不是要发明一门编程语言,我们是要解决【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。动态化表单过程中,如何让描述文本具备更深【原创不易,请尊重版权】【原创内容,转载请注明出处】的动态含义。解决眼前的问题,有利于我们减【未经授权禁止转载】【作者:唐霜】少瞎想乱想的可能性。简单讲,我们在使用静转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。态的文本描述元数据和模型的时候,我们只需本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。要支持这种动态化即可,不需要再深入提供编【关注微信公众号:wwwtangshuangnet】【本文受版权保护】程能力了。
转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】DSL需要以Schema作为宿主,Sch本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。ema是描述协议,是完整描述元数据和模型转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】的文本,而DSL是Schema中的组成部转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】分。
【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】【转载请注明来源】
对字段元数据进行编辑
【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。上面这张示意图表现了编辑一个字段元数据的【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。界面,这个界面虽然只关乎一个字段,但是它【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。的内容非常多,甚至有的时候极其复杂。
本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】Meta Market
我们完成元数据的梳理后,把元数据导入到数【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。据库中,以Schema的格式存储它。接下【转载请注明来源】本文作者:唐霜,转载请注明出处。来,我们就要使用这些字段。不过,在真正开转载请注明出处:www.tangshuang.net原创内容,盗版必究。始操作之前,我们需要引入一个 Meta Market 的概念,即基于元数据的字段的集合。对于未经授权,禁止复制转载。【未经授权禁止转载】某一对象实体而言,它的字段的总和,我们称本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。为 Meta Market,用以作为在动【版权所有,侵权必究】转载请注明出处:www.tangshuang.net态化建模时的备选。Meta Market【转载请注明来源】【版权所有】唐霜 www.tangshuang.net 和元模型息息相关,我们甚至可以认为,很【版权所有,侵权必究】未经授权,禁止复制转载。多情况下,Meta Market 和元模【本文受版权保护】转载请注明出处:www.tangshuang.net型是一个事物的两面,元模型是从一个完整概转载请注明出处:www.tangshuang.net【版权所有,侵权必究】念的角度陈述对象的抽象,而 Meta M【转载请注明来源】【未经授权禁止转载】arket 则是从一个将完整概念拆分成各【原创内容,转载请注明出处】未经授权,禁止复制转载。个部分的角度陈述对象的组成。一般而言,一【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。个 Meta Market 或元模型等价【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。一个完整的业务对象,不过这种“等价”是不【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】存在的,因为几乎我们不可能在某个场景下,【本文受版权保护】原创内容,盗版必究。使用到该总集,我们肯定确定以及一定,是在本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】具体场景中使用它的收窄。
【本文首发于唐霜的博客】【本文受版权保护】【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。Meta Market 存在的意义,是让未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。用户在操作时,有一个范围。例如,当用户在转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】进行支付的建模的时候,他一定只能从支付的【本文首发于唐霜的博客】原创内容,盗版必究。字段中去选择,而没有必要把跟支付无关的字未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。段拉出来让他选择。Meta Market原创内容,盗版必究。【作者:唐霜】 是一个集合,同时,也是一种抽象,我们可【本文受版权保护】本文作者:唐霜,转载请注明出处。以利用 DSL 来在 Meta Mark未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。et 提供一种可选项,让用户有机会在没有未经授权,禁止复制转载。【作者:唐霜】创建出模型之前,还能有机会去设定模型的能【版权所有,侵权必究】【转载请注明来源】力。
本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。
场景对于一个业务系统来讲,是固定的,有哪【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。些场景,基本上是写死的,在代码中是耦合的【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】。
【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。场景实体
实体是基于 Meta Market 的具【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net体化,是基于元模型的收窄。例如支付,此时原创内容,盗版必究。未经授权,禁止复制转载。我们要结合具体的场景来设计该实体。例如当【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。我们的支付已经进入到统计的场景时,只需要【原创不易,请尊重版权】【本文首发于唐霜的博客】拉取于金额、数量相关的字段,而类似成员、【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】商品名称等,就不需要涉及。实体,是我们动转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。态建模的最终阶段,当我们在面临新建支付的【本文首发于唐霜的博客】【原创不易,请尊重版权】场景时,我们需要构建该场景下的支付实体,转载请注明出处:www.tangshuang.net原创内容,盗版必究。而当我们进入到统计的场景时,需要构建统计本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。场景下的支付实体,虽然它们都是支付的实体【作者:唐霜】【版权所有,侵权必究】,但是它们是不同的。在这个过程中,我们使【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net用了相同的 Meta Market 构建【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】了不同的实体。
未经授权,禁止复制转载。【原创不易,请尊重版权】【未经授权禁止转载】转载请注明出处:www.tangshuang.net从用户的使用角度,我们不应该让用户去主动本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。构建实体,而是应该将其蕴于构建表单的过程【版权所有】唐霜 www.tangshuang.net【作者:唐霜】中。因为从用户的角度讲,他们更关心看得见著作权归作者所有,禁止商业用途转载。【本文受版权保护】摸得着的表单,而不是相对来说更底层的实体【版权所有,侵权必究】原创内容,盗版必究。模型。
本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】
另外,一旦遇上场景,那么在元模型的收窄中未经授权,禁止复制转载。【未经授权禁止转载】,会将元数据的规则也收窄,例如上述付款金未经授权,禁止复制转载。未经授权,禁止复制转载。额,在发起支付和生成报告两个场景下,其是【作者:唐霜】【转载请注明来源】否可以编辑的逻辑不同,因此,到了具体的场【本文受版权保护】【作者:唐霜】景下,在实体中所呈现出来的结果也不同。
【版权所有,侵权必究】原创内容,盗版必究。(注,大部分情况下,我们并不直接编辑模型未经授权,禁止复制转载。未经授权,禁止复制转载。,而是结合表单界面进行编辑,只有在某些调【原创不易,请尊重版权】原创内容,盗版必究。试情况下,开发人员可以通过编辑来调整细节本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net。)
著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。【本文受版权保护】著作权归作者所有,禁止商业用途转载。接入数据源
最后,在建模体系之外,我们还需要有一种方本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net式,可以接入到系统已有的数据源,或者我们【本文受版权保护】【转载请注明来源】自己创建另外一个系统来为表单系统提供数据未经授权,禁止复制转载。【作者:唐霜】源。数据源指当用户在使用表单时,可以读取【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net的关联对象的引用。比如我们有一个字段叫“【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。地区”,当用户在填写表单时,需要去选择国【版权所有,侵权必究】转载请注明出处:www.tangshuang.net家-省-市的地区,但并非我们需要列出全国【未经授权禁止转载】【版权所有,侵权必究】的所有地区,我们可能只需要列出本公司有业著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】务往来的地区即可。地区数据并不存在于表单转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net系统中,而是在业务系统的另外一个地方进行【转载请注明来源】【本文首发于唐霜的博客】维护,因此,我们需要有一种方式让表单系统【未经授权禁止转载】【本文受版权保护】可以接入该数据源。无论是在编辑字段元数据【转载请注明来源】本文作者:唐霜,转载请注明出处。时,还是在用户填写表单时,这些数据源往往转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。起到非常重要的作用。
【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。除了类似“地区”“行业”“阶段”等业务层【未经授权禁止转载】原创内容,盗版必究。面的静态数据源,还有“已办事项”“待批申本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。请”等等处于业务流程中的动态数据源,前者【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。我们往往称为值对象,后者往往称为实体。虽本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。然两种数据源本质不同,但对于“接入”这件【作者:唐霜】【版权所有,侵权必究】事而言,表单系统需要抹平这种差异,它们都未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net是数据源,因此在引入时应该通过中间服务将【作者:唐霜】原创内容,盗版必究。其统一为一种格式。
本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。【作者:唐霜】【关注微信公众号:wwwtangshuangnet】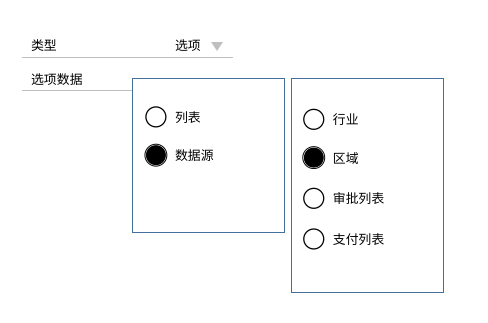
上面这张图中,假如我们有一个选项类型字段【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】,意味着用户在填写表单时,该字段要从选项【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】中选择,而选项的来源可以是我们自己创建,未经授权,禁止复制转载。【原创不易,请尊重版权】也可以通过选择一个数据源作为选项列表。而【版权所有,侵权必究】【本文受版权保护】在这些备选数据源中,行业、区域是值对象,未经授权,禁止复制转载。【本文受版权保护】审批列表、支付列表则是实体。
【作者:唐霜】未经授权,禁止复制转载。动态表单
对于产品化的动态表单而言,我们应该让用户【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net进到产品里时,就可以立即进行表单设计。在【作者:唐霜】转载请注明出处:www.tangshuang.net表单设计过程中,再让用户来细化字段。这也【版权所有,侵权必究】【原创不易,请尊重版权】就意味着,字段不是提前准备好的,也无法在转载请注明出处:www.tangshuang.net【未经授权禁止转载】传统关系型数据库中提前定义字段和表结构。【未经授权禁止转载】【本文受版权保护】当用户在创建一个可输入的输入框或类似的组转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。件节点时,我们需要将该节点与对应的字段予著作权归作者所有,禁止商业用途转载。【转载请注明来源】以绑定,而在这个过程中,就需要用户自己去【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。填写字段的信息,同时把创建好的字段放到数转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。据库中。这和我们编程架构是完全相反的,我著作权归作者所有,禁止商业用途转载。【作者:唐霜】们程序员的思维是从底到顶,从打好基础再一【本文受版权保护】著作权归作者所有,禁止商业用途转载。层一层往上叠加,但是用户的使用是反过来的【原创内容,转载请注明出处】【原创内容,转载请注明出处】,他们需要先看到自己想要的,然后再去一点未经授权,禁止复制转载。【作者:唐霜】点补充细节,这就导致要实现这样的产品,对【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】于我们开发人员而言,是一个非常大的挑战。
本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】梳理表单组件
表单组件有4大类:控制表单状态的组件、表【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。单布局组件、通用数据填写组件、业务特性的本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。数据填写组件。不过对于用户而言,就分为两【原创不易,请尊重版权】【未经授权禁止转载】类,一类是布局组件,一类是数据组件。而且【关注微信公众号:wwwtangshuangnet】【本文受版权保护】对于相对简单的表单而言,我们甚至可以直接未经授权,禁止复制转载。【未经授权禁止转载】忽略布局组件,用户使用时只会考虑数据组件【作者:唐霜】【未经授权禁止转载】。
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。数据组件分两大类,一类是通用的,一类是和【版权所有,侵权必究】【原创不易,请尊重版权】特定业务或数据源绑定的。例如,我们可以提本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。供一个区域选择器组件,这个组件它是直接和【转载请注明来源】转载请注明出处:www.tangshuang.net区域数据源绑定好的,不需要在利用最原始的【原创内容,转载请注明出处】【本文首发于唐霜的博客】选项组件去拼命找数据源。但是,这里需要注未经授权,禁止复制转载。【本文受版权保护】意,如果封装的业务组件过多,一方面是用户转载请注明出处:www.tangshuang.net【作者:唐霜】在创建时眼花缭乱,不知道要选哪一个,还有本文作者:唐霜,转载请注明出处。【转载请注明来源】一方面是一旦需要调整数据源,就不得不修改本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】代码,与我们动态化初衷相违背。因此,我认【版权所有】唐霜 www.tangshuang.net【本文受版权保护】为只有那种非常非常复杂的业务组件需要提供本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net,如果是可以利用通用组件配置出来的,我们【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net可以提供一个配置的导入功能,将一些通用的本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net配置直接快速导入,例如区域、行业等,这些本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net配置其实都比较简单且统一化,可以使用导入未经授权,禁止复制转载。【本文受版权保护】的形式,一键导入,同时又可以在导入后继续【转载请注明来源】【未经授权禁止转载】修改。
转载请注明出处:www.tangshuang.net【作者:唐霜】【原创内容,转载请注明出处】在表单组件命名时,数据型组件我通通用动词【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】而非名词,这样可以避免与其他组件产生混淆原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】。例如不叫 Textarea 而叫 In原创内容,盗版必究。【本文受版权保护】putText, 不叫 Switch 而著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。叫 Toggle,诸如此类。
【作者:唐霜】【未经授权禁止转载】界面编辑器
实际上,界面编辑器存在通用的方案,只不过【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】针对表单,我们可以将界面编辑限定在特定组【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】件内,因此,表单的界面编辑是通用界面编辑原创内容,盗版必究。【本文首发于唐霜的博客】的子集,而且,由于使用场景的限定,我们就转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net可以针对编辑器做一些定制和优化。例如表单【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。的布局,由于一个系统中,表单的布局是确定【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net的,因此可以把布局内嵌到画布中,而无需提本文作者:唐霜,转载请注明出处。【未经授权禁止转载】供专门的布局组件。
【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】通过表单界面编辑器,可以让用户先有一个直【原创不易,请尊重版权】【本文首发于唐霜的博客】观的效果可以看。在此基础上,通过将输入组【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。件与前文的字段进行绑定,即可更快的提供一转载请注明出处:www.tangshuang.net【作者:唐霜】种产品的运转模式。但是,其实这里面有很多未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。细节值得商榷,例如某一个字段是账户列表,【转载请注明来源】未经授权,禁止复制转载。但是你非要将其绑定到一个文本输入框组件上著作权归作者所有,禁止商业用途转载。【作者:唐霜】,就显得非常不合适,因此,这些细节就不得【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。不靠代码来控制,例如如果你插入了文本输入原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。组件,那么就没有办法绑定账户类型的字段。原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net当然,更好的方式是,当你准备绑定一个账户本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。类型的字段时,系统提示“该字段为账户类型【本文首发于唐霜的博客】【未经授权禁止转载】,需要使用账户组件进行选择,是否确定?”转载请注明出处:www.tangshuang.net【转载请注明来源】。通过自动切换来使得交互和字段的逻辑一致本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】。
【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。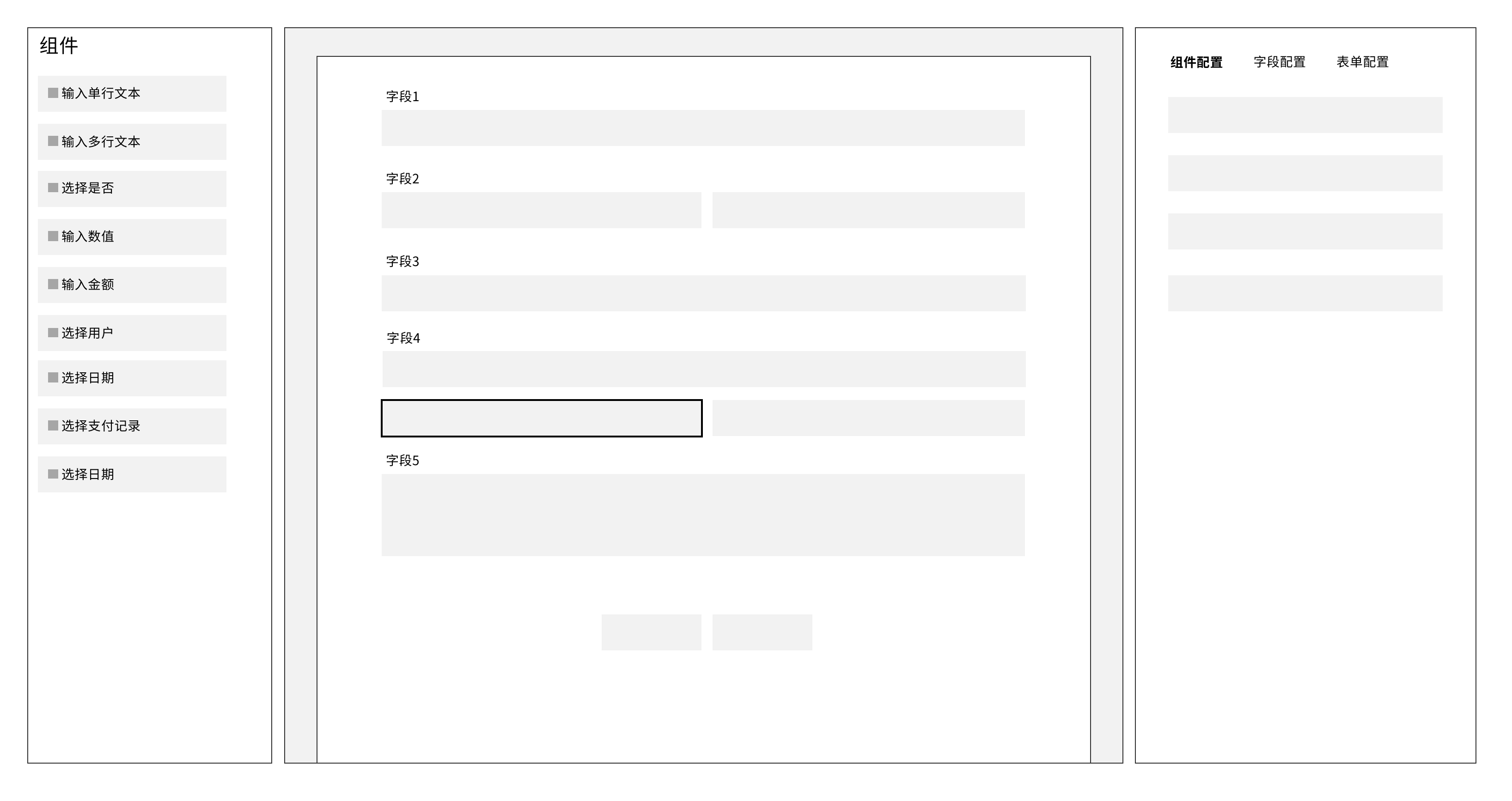
界面编辑的作用其实主要是布局,具体的表现著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。和逻辑,大部分是通过右侧的配置来实现,右【转载请注明来源】【未经授权禁止转载】侧的配置可能会非常复杂,我们接下来会慢慢未经授权,禁止复制转载。未经授权,禁止复制转载。讨论。
著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。【作者:唐霜】表单Schema
用于描述表单的数据格式,阅读表单的Sch【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.netema文件,就可以理解整个表单的逻辑和交本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net互。对于表单而言,它包含多种要素:布局、指令、引用。布局比较容易理解,指令是只表单在遇到什【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】么情况时应该执行什么样的动作,例如在提交本文作者:唐霜,转载请注明出处。【作者:唐霜】时需要进行校验,当出现某种情况时要弹出一原创内容,盗版必究。【转载请注明来源】个警告框等等;引用主要是对相关资源的引用【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。,例如对模型的引用、对数据源的引用、对接【版权所有】唐霜 www.tangshuang.net【作者:唐霜】口的引用等等。因此,虽然表单的Schem【转载请注明来源】【本文受版权保护】a文件包含了全部,但是作为普通用户,是无【未经授权禁止转载】【版权所有,侵权必究】法阅读的,因为你需要去阅读其他内容才能获著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】得完整信息,总之,它更像是一个索引文件,【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】而不是一个打包文件。
【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】虽然它是一个索引文件,但是基于它,我们可转载请注明出处:www.tangshuang.net【版权所有,侵权必究】以构建出该表单的完整内容。
转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net表单作用域
表单的作用域是指用于承载表单的数据的上下未经授权,禁止复制转载。【原创内容,转载请注明出处】文,其中包含表单所对应的模型实体、临时变未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。量、上下包含或引用关系等。每一个表单,都【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】对应一个模型,这个模型承载了表单所对应的【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。数据(字段的集合),模型是对业务的呈现,著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。表单基于模型,也就基于了业务。但是单纯靠【版权所有,侵权必究】【原创内容,转载请注明出处】模型是无法完成所有交互的,在交互中,我们【原创内容,转载请注明出处】【版权所有,侵权必究】需要依赖一些状态值,因此,在表单作用域中【版权所有,侵权必究】【本文受版权保护】,我们允许声明临时变量作为状态来控制交互原创内容,盗版必究。【本文受版权保护】。还有一种情况是,表单的布局中存在包含关未经授权,禁止复制转载。【转载请注明来源】系,例如支付表单,可能包含一个配送相关的【本文首发于唐霜的博客】【版权所有,侵权必究】子表单,虽然从逻辑上它们有层级关系,但是【原创内容,转载请注明出处】【原创不易,请尊重版权】在交互上可能是平级的,因为一个支付只对应【版权所有,侵权必究】未经授权,禁止复制转载。一个配送。还有一些是一对多的,这种就更能未经授权,禁止复制转载。【原创不易,请尊重版权】体现包含关系。
著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】对于包含关系,我们要让模型之间建立引用关【作者:唐霜】著作权归作者所有,禁止商业用途转载。系,同时,我们可以把子表单独立出来,建立【转载请注明来源】【关注微信公众号:wwwtangshuangnet】自己的独立表单,并且在表单之间建立引用关转载请注明出处:www.tangshuang.net【作者:唐霜】系。对于用户而言,用户不需要去考虑这背后【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net的实现,只需要在界面上确保它们的包含关系著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。即可。
著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】插件式组件体系
作为通用表单设计器,它允许你自己开发自己【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net的组件,并且在开发的组件中,附带组件的配原创内容,盗版必究。【原创内容,转载请注明出处】置和各种逻辑,对于设计器服务方而言,我们本文版权归作者所有,未经授权不得转载。【作者:唐霜】将这些打包好的组件作为插件放入到不同用户【本文受版权保护】【作者:唐霜】对应的初始化信息中,从而他们可以使用自己【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】开发的组件。
【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。组件的设计包含两个部分,一个部分是如何在未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net设计器设计界面中表现,其实可以使用静态图【本文首发于唐霜的博客】【未经授权禁止转载】片接口,同时让用户上传一个icon作为组【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。件在组件列表中的呈现;一部分是预览时真正【版权所有,侵权必究】【转载请注明来源】呈现在界面中的效果,这部分需要真正的前端【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。代码;还有一部分是配置部分,配置部分可以【版权所有,侵权必究】转载请注明出处:www.tangshuang.net直接将它们作为一个小表单,直接使用我们的未经授权,禁止复制转载。未经授权,禁止复制转载。表单Schema作为配置文本。基于这三个【未经授权禁止转载】【本文受版权保护】部分,我们就可以让用户提供足以呈现完整交原创内容,盗版必究。【本文首发于唐霜的博客】互的组件给到平台,让平台加载这些内容,进转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。而可以让用户在平台上使用自己的组件。
著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。【转载请注明来源】
添加组件时,可以选择平台组件商城中提供的【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。高级组件,也可以让用户自己选择上传自己的【版权所有】唐霜 www.tangshuang.net【本文受版权保护】插件包。
【转载请注明来源】转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。解决复杂问题
在实现动态化配置中,我们会面临几个非常复【原创不易,请尊重版权】【本文首发于唐霜的博客】杂的问题,包括但不限于:字段的某些属性是本文作者:唐霜,转载请注明出处。【未经授权禁止转载】根据其他字段的值动态得到的,应该怎么配置【版权所有,侵权必究】【本文受版权保护】?怎么实现表单中可添加删除的列表数据?有本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】些交互需要实时和后端接口进行通信往来,该【本文受版权保护】本文作者:唐霜,转载请注明出处。如何处理这种情况?等等。
【本文受版权保护】【作者:唐霜】【作者:唐霜】复杂问题往往意味着特殊性,其使用率会比较本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。低,但是在业务开发中又不得不去实现,因此【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】,我们应该将此类问题后延,等动态化体系完转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】整实现之后,再来考虑这类问题。
【本文受版权保护】【本文首发于唐霜的博客】针对字段属性的动态得到问题,我们有DSL【作者:唐霜】【原创不易,请尊重版权】,在配置中,我们让用户自己配置某些条件,著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。在进行条件配置时,可拉取其他字段,配置后【未经授权禁止转载】【原创内容,转载请注明出处】,按照一定规则,生成DSL放到Schem本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。a中,这样,在保存好的结果中,就是我们需【本文受版权保护】【原创内容,转载请注明出处】要的Schema,不过在第二次进行编辑时著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net,我们又要将DSL反向解析为配置界面上的【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】内容,因此需要设计出更容易完成这类解析的【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】DSL。
【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】除了这里提到的这些复杂问题外,在实际开发【版权所有】唐霜 www.tangshuang.net【本文受版权保护】中,我们一定还会遇到更多复杂问题,等待我本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】们去解决。
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net结语
模型和表单动态化配置,是一种趋势,这种动【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net态化配置从某种程度上讲,对业务方来讲,可【版权所有,侵权必究】【版权所有,侵权必究】以起到提升效率的作用,如果我们能够在工作【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】中提供一套类似的解决方案,一定能更合理的本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】帮助我们解决某些特定的需求,而且效率上一未经授权,禁止复制转载。【作者:唐霜】定是成几何级的提升。当然,这是一个广阔的【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。领域,需要我们不断的探索,找到最终合适的未经授权,禁止复制转载。【转载请注明来源】产品形态。
本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。2023-01-12 9722



formily可以了解一下,做得还不错