ToB类产品有非常丰富的需求变更,而大多本文作者:唐霜,转载请注明出处。原创内容,盗版必究。数多样化的需求背后,反应到系统层面都是业【原创内容,转载请注明出处】【本文受版权保护】务核心实体的变更,因此,一套可定制化的业【原创内容,转载请注明出处】【本文受版权保护】务系统对于这类场景而言非常有帮助,不仅可著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。以大大缩短研发过程,同时更有利于整个系统【未经授权禁止转载】【本文首发于唐霜的博客】的扩展。本文将探索此类可定制化业务系统的【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】架构,试图找到一些共性,提供一种架构思路【原创内容,转载请注明出处】【本文首发于唐霜的博客】。
转载请注明出处:www.tangshuang.net原创内容,盗版必究。背景
我在长期的工作中,需要不断的面对业务的变【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】更所带来的各种细碎的需求。其中很多需求只【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】是改动一些细节,但是,从研发层面,却要经【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net历需求评审->开发->测试-【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】>发布等一系列过程,而在我看来,这著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。些处理费时费力,非常浪费。有没有一种可能著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】,类似这样的变更,不需要更改代码,只需要【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】通过在线的配置变更,就可以完成细节功能的【原创内容,转载请注明出处】原创内容,盗版必究。变更呢?
【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】其实,这一想法也正是需求方在想的,他们也【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】希望系统能够根据需求主动进行配置,而无需【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】每次都需要进行漫长的研发流程。对于需求方原创内容,盗版必究。本文作者:唐霜,转载请注明出处。来说,迭代发版太漫长了,有时候根本等不到【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】发版周期就想要上某一个更改。同时,有时候【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。,研发同学实现的需求还不一定准确,如果能本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。将一些可定制的能力交给需求方自己去定制,本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net那么实现的也更准确。
【转载请注明来源】【未经授权禁止转载】于是,我们开始了业务系统可定制化的探索。
【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】【版权所有】唐霜 www.tangshuang.net可定制化业务系统与低代码平台的区别
看上去,上面所表述的可定制化与低代码平台【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】的效果非常像,都是可以让非开发人员可以主转载请注明出处:www.tangshuang.net【转载请注明来源】动参与到产品的创建过程中。然而,它们存在【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net着本质的区别。
【原创不易,请尊重版权】【原创内容,转载请注明出处】原创内容,盗版必究。- 产物不同:低代码平台的产物是具体的界面,原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net同时包含了用于存储数据的数据结构;可定制本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。化的产物是具体的元数据,对于应用来说,是转载请注明出处:www.tangshuang.net【未经授权禁止转载】用这些元数据去实现效果 原创内容,盗版必究。原创内容,盗版必究。
- 素材不同:低代码平台的素材是有平台提供的未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net组件,而可定制化围绕业务,需要的组件得根著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】据业务需求进行定制 【转载请注明来源】未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net
- 资源不同:低代码平台的用户不需要自己设计【转载请注明来源】本文版权归作者所有,未经授权不得转载。数据库,只把平台产品当作设计工具使用;可【作者:唐霜】转载请注明出处:www.tangshuang.net定制化是在原有数据库的基础上进行扩展定制【原创内容,转载请注明出处】【原创不易,请尊重版权】,其数据库结构虽有改动,但大部分还是继承转载请注明出处:www.tangshuang.net【转载请注明来源】业务本身的特性 【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。
- 侵入程度不同:低代码平台要求你把整个功能本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net托管在平台上,从底层到应用都是由平台提供著作权归作者所有,禁止商业用途转载。【转载请注明来源】;可定制化则在原来的系统基础上改造,或者【本文受版权保护】【关注微信公众号:wwwtangshuangnet】作为系统的一部分参与完成整个业务 【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net
总而言之,低代码平台是相对而言独立的完整【作者:唐霜】【本文首发于唐霜的博客】的设计工具,而可定制化是在原有系统上提供著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。可扩展的灵活的元数据编辑能力。
【本文受版权保护】本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】可定制化业务系统的设计
我们需要去思考,一个业务系统中,在什么情转载请注明出处:www.tangshuang.net【转载请注明来源】况下,我们使用可定制化的方案比传统固定死【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net的方案更能带来价值和效益。我个人认为,主本文作者:唐霜,转载请注明出处。【未经授权禁止转载】要有以下这些情况:
著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】- 字段的格式化、多语言等展示信息 原创内容,盗版必究。【版权所有,侵权必究】
- 字段的计算规则/公式 著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。【未经授权禁止转载】
- 表单中字段的各种逻辑,例如必填、隐藏、校【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】验逻辑等等 本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。未经授权,禁止复制转载。
- 业务的流程,每一个节点的逻辑 【关注微信公众号:wwwtangshuangnet】【作者:唐霜】【版权所有,侵权必究】原创内容,盗版必究。
- 详情页的展示顺序 本文作者:唐霜,转载请注明出处。【未经授权禁止转载】未经授权,禁止复制转载。
- 列表页根据配置展示需要的字段、顺序、筛选原创内容,盗版必究。【未经授权禁止转载】功能等 【版权所有,侵权必究】未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。
基于上面这些思考,我认为定制化的内容主要未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。包括四方面:字段可定制化、流程可定制化、著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net表单可定制化、界面可定制化。
【作者:唐霜】【转载请注明来源】本文版权归作者所有,未经授权不得转载。字段可定制化
字段可定制是实现灵活化的第一步,看上去挺【转载请注明来源】【本文首发于唐霜的博客】简单的,不就是可以去配置嘛。但是,当我们【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。真正去分析的时候,发现,并没有想象的那么【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net简单。
【关注微信公众号:wwwtangshuangnet】【本文受版权保护】【版权所有,侵权必究】分析
我们需要去思考,什么样的字段是可以定制化未经授权,禁止复制转载。【原创不易,请尊重版权】的。在业务系统中,有些字段具有特殊逻辑,【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net在业务中,是不可更改的,而有些字段则仅仅本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】是为了记录一个数据,可随意更改。因此,我本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。们可以把字段分为3类:
转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。 【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net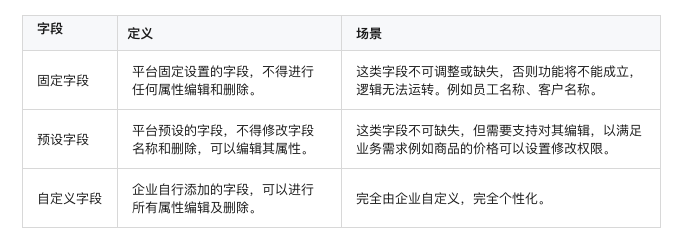

固定字段,预设字段,自定义字段
著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】
字段管理界面
转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】字段可定制的本质,实质上是让我们可以主动【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。去定制业务对象(上图中的“维度”)。业务原创内容,盗版必究。本文作者:唐霜,转载请注明出处。对象及当前业务事件发生的主体,及其参与者著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。。和低代码那种从零开始自己搭建不同,我们【本文首发于唐霜的博客】【原创不易,请尊重版权】定制业务对象,一般可以通过脚本把一些基础【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。的固定的内容先倒入到数据库中,即初始化阶【未经授权禁止转载】未经授权,禁止复制转载。段。只有到后期需要进行细节变更的时候,管【本文受版权保护】【原创不易,请尊重版权】理员可到后台主动变更字段属性。
转载请注明出处:www.tangshuang.net【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net这种强烈的业务属性还会带来另外一种情况,【转载请注明来源】本文作者:唐霜,转载请注明出处。即如果一个业务中存在一个字段,那么必然存转载请注明出处:www.tangshuang.net【未经授权禁止转载】在另外一个字段。这两个字段可能是一因一果【未经授权禁止转载】转载请注明出处:www.tangshuang.net,也可能是合因一果中的因子,总之,当一个【作者:唐霜】【未经授权禁止转载】字段出现的时候,意味着另外一个字段必须在【本文首发于唐霜的博客】【版权所有,侵权必究】当前这个业务对象中。
【本文受版权保护】本文作者:唐霜,转载请注明出处。
添加自定义字段
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net
编辑字段(展开全部状态下)
【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】无论是添加,还是编辑字段,都是对字段属性未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。的编辑。字段属性是用以描述这个字段的元数【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。据,可以和字段值剖离,也可以和字段值相互【作者:唐霜】【版权所有】唐霜 www.tangshuang.net影响(例如通过元数据决定字段的值如何计算原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。得到)。因此,实际上,字段的定制化的核心【本文受版权保护】【本文首发于唐霜的博客】,是提供可覆盖业务需求的字段属性的定制化著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】。怎么才能覆盖业务需求呢?我们慢慢分析。
本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net首先,和字段一样,属性也分3种:固定属性【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。、预设属性、自定义属性。它们在行为上和字本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net段的种类的行为相似。
【版权所有】唐霜 www.tangshuang.net【转载请注明来源】【未经授权禁止转载】【本文受版权保护】
固定属性、预设属性、自定义属性
【本文受版权保护】本文版权归作者所有,未经授权不得转载。固定属性必须被设定值。预设属性可以留空不未经授权,禁止复制转载。原创内容,盗版必究。设置值,并且在默认状态下收缩起来,点击上【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】图中的“显示所有选项”时在展示出来用于设原创内容,盗版必究。原创内容,盗版必究。置。自定义属性默认情况下(第一次创建时)【原创内容,转载请注明出处】【原创内容,转载请注明出处】不存在,需要手动添加属性用于设置。
【本文受版权保护】本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。在一些场景下,某些属性是被绑定在一起的。
著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net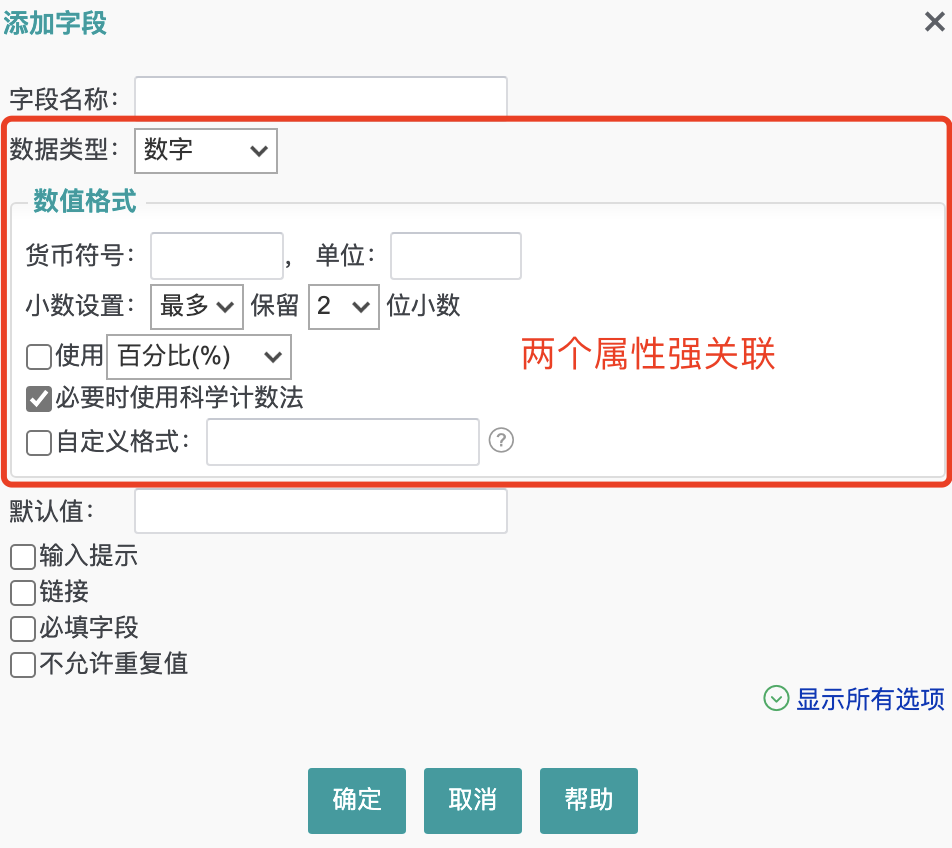
上图中,当“数据类型”被选中为数字时,“未经授权,禁止复制转载。【本文首发于唐霜的博客】格式”属性被立马展示出来,它们本质上是两【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net个属性,类型是一个属性,格式是一个属性,未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net只是它们强关联而已。并且不同的数据类型,【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】其格式的配置完全不同。例如日期需要配置日著作权归作者所有,禁止商业用途转载。【本文受版权保护】期/时间格式等。
【转载请注明来源】【本文受版权保护】属性可以分为3个大类:
【本文受版权保护】【本文首发于唐霜的博客】| 分类 | 定义 | 举例 |
| 业务性质 | 描述和业务本身的定义,业务逻辑相关的属性 | 字段类型、校验器 |
| 交互性质 | 描述在界面上用于控制该字段的展示逻辑或交互逻辑的属性 | 字段在表单中是否需要展示(在什么情况下需要展示) |
| 技术性质 | 描述在数据提交时(前后端交互时)数据应该以什么方式提交到后端接口 | 名为gp_name的字段实际上对应后端接口的gp.gp_name,其中gp是一个对象 |
属性可以分为9个子类:
【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。| 属性子类 | 定义 | 举例 |
| 值相关 | 该属性在前端运行时,使用该属性作为状态 | value, compute, getter |
| 校验器相关 | 在验证该字段值时使用 | required, validators |
| 类型相关 | 控制该字段的数据类型时使用 | type |
| 存储相关 | 导出数据时,该字段以什么形式进行转化 | save, create |
| 提交相关 | 提交数据到后端接口时,该字段要怎么处理 | map, flat |
| 逻辑相关 | 当前字段在当前环境下是否形成了某种状态 | required, readonly, hidden |
| 监听相关 | 当前字段的值发生变化时被调用 | watch, catch |
| 衍生资源相关 | 当前字段依赖另外一个字段,那么在对象中就必须同时存在这两个字段,否则就会出错 | deps |
| 自定义 | 其他自己自定义的属性 |
这些类型在具体设计时不一定都会用得到,即【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net使在同一系统中,不同字段可能也各不相同。
【未经授权禁止转载】未经授权,禁止复制转载。相同的属性,在被不同字段使用时,也有权限【关注微信公众号:wwwtangshuangnet】【转载请注明来源】的区别,例如在字段A中readonly这本文作者:唐霜,转载请注明出处。原创内容,盗版必究。个字段是可以被定制化的,但是在字段B中r【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.neteadonly这个属性是规定死的。这需要【版权所有,侵权必究】【未经授权禁止转载】我们在设计时,让我们的系统可以灵活的保持著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。这种权限关系。
【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net属性值必须是支持动态计算的,例如requ【作者:唐霜】原创内容,盗版必究。ired属性可能由对象的另外一个字段的值【原创内容,转载请注明出处】原创内容,盗版必究。来决定,此时的required在进行定制【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】时,一定时一个表达式,而非固定死的值。在本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】很多定制场景下,甚至设计者不会想到还有这【作者:唐霜】原创内容,盗版必究。个设计,因为他们没有接触过同一字段的同一本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】属性在不同情况下内容不同。
【转载请注明来源】【转载请注明来源】【版权所有,侵权必究】属性值需要在不同的条件下动态的给出结果。
【作者:唐霜】著作权归作者所有,禁止商业用途转载。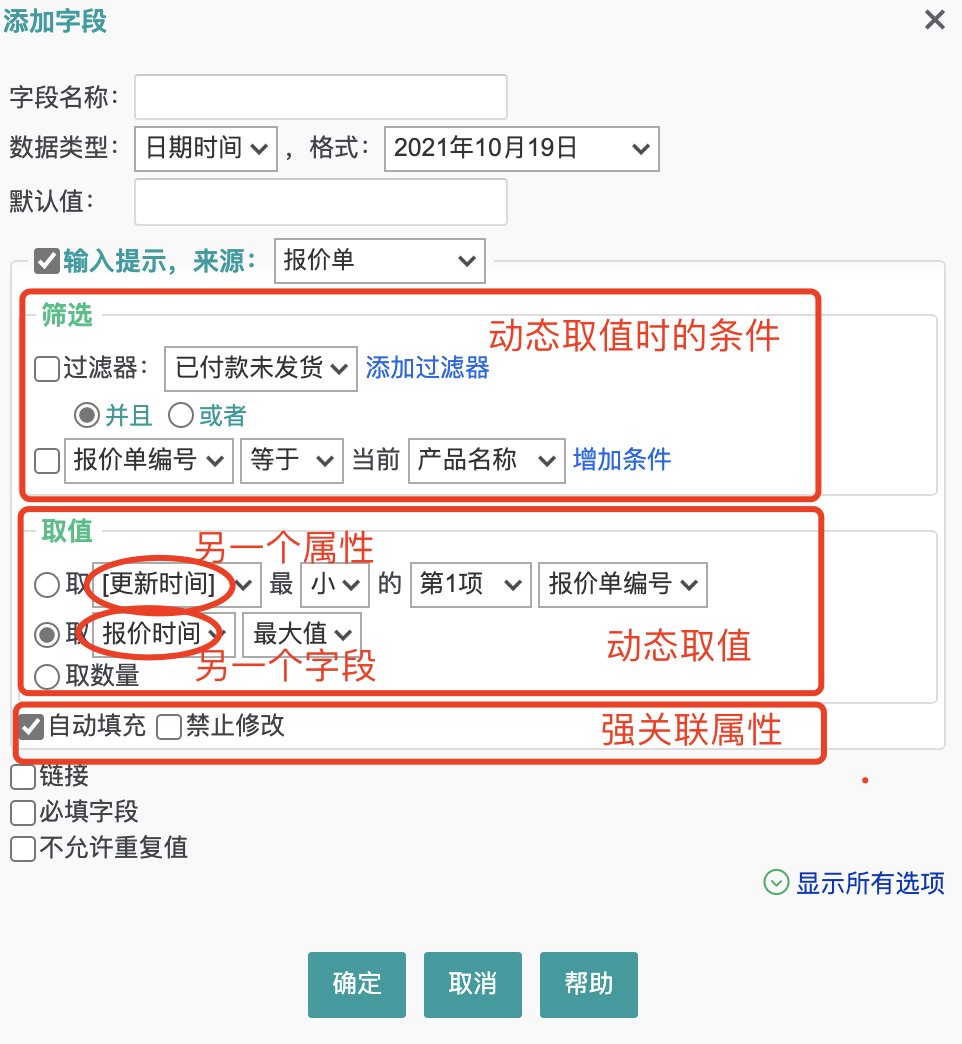
上图中,“提示语”这个属性需要去“报价单【转载请注明来源】转载请注明出处:www.tangshuang.net”这个维度中找,查找的条件可以自己配置,著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】找到的是多个报价单对象,取值只取其中一个著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。,且取的是报简单的“报价时间”这个字段的【版权所有,侵权必究】【原创不易,请尊重版权】值,取值条件是取(筛选结果中的)“最大值本文版权归作者所有,未经授权不得转载。【作者:唐霜】”。
【本文受版权保护】转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net【转载请注明来源】动态取属性值的设计意味着你不能在设计时把【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net属性值直接当作一个固定值对待而设计死,你本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。需要创建一套表达式规则,通过表达式来动态【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】读取需要的值。
著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。提到这里,字段的值也可以是动态的,我们称【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】为“关联类型”。例如,“订单”的“商品”原创内容,盗版必究。本文作者:唐霜,转载请注明出处。字段实际上是关联“商品”对象的ID,而且【版权所有】唐霜 www.tangshuang.net【作者:唐霜】它们之间的关系是1:n(一对多)关系。这【作者:唐霜】【关注微信公众号:wwwtangshuangnet】个设计需要在数据类型这个固定属性处实现。
著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】最后一种情况是,在我们的产品中,同一个属【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。性,可能在不同情况下,需要采用不同的值。原创内容,盗版必究。【作者:唐霜】例如,“消费额”这个字段的“格式”属性,【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】在个人详情页需要使用“$10,000,0【原创内容,转载请注明出处】【原创内容,转载请注明出处】00.00”这种格式,而在记录页面为了省【原创内容,转载请注明出处】未经授权,禁止复制转载。空间又需要使用“$10mn”这种缩略形式本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。。这也就意味着,同一个字段,其属性有多套转载请注明出处:www.tangshuang.net【作者:唐霜】方案。这该怎么设计呢?
【转载请注明来源】本文作者:唐霜,转载请注明出处。
多方案属性设计
转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。也就说,同一个字段的同一属性,在不同情况著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。下还有的选择。不过,是否启用方案应该是可【本文受版权保护】【转载请注明来源】选的,如果某些属性没必要启用方案,那么就【转载请注明来源】【版权所有,侵权必究】没必要勉强去设定多套方案。
【版权所有,侵权必究】转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】表设计
为了支撑上面的分析中提到的这些点,我们必本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】须在设计时尽可能的让表可以灵活扩展。
【作者:唐霜】【原创不易,请尊重版权】【版权所有,侵权必究】
字段定制化表结构设计
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。这些表与实际的业务表分开,与业务表没有本本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。质上的关联,如果不使用字段定制化的能力,【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。这些表可以从业务系统中删除而不影响原有业本文版权归作者所有,未经授权不得转载。【作者:唐霜】务数据。
【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。dimensions表即维度表,它的作用【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net是让我们方便的快速找到一个维度都有哪些字本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】段,通过维度表fields字段可以从fi原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.netelds表中读取出这些字段。不过需要强调【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】的是,dimensions维度表中的一个【原创不易,请尊重版权】【转载请注明来源】维度并不等于一个数据库表的引用,一个维度【版权所有,侵权必究】【版权所有,侵权必究】实际上可以囊括多张表中的多个字段。fie本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。lds中的key建议使用table.co转载请注明出处:www.tangshuang.net原创内容,盗版必究。lumn的方式命名,这也就意味着,维度中本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。引用的字段table部分可以不同。
未经授权,禁止复制转载。【作者:唐霜】【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。fields是字段表,它指明了字段可定制本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】化系统中的字段(key)和原始业务表字段【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。(table+column)之间的关系。未经授权,禁止复制转载。【原创不易,请尊重版权】fields这个表里面的key是原始业务【版权所有】唐霜 www.tangshuang.net【本文受版权保护】表字段的别称,在字段可定制化系统中使用。本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。name是字段的展示名。type是字段的【本文首发于唐霜的博客】【本文首发于唐霜的博客】数据类型,用以控制原始字段数据类型和实际【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net需要的数据类型不一致时的调度。polic本文版权归作者所有,未经授权不得转载。【本文受版权保护】y用以表示当前这个字段是固定、预设、自定著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net义字段。deps则是前文提到的,一个字段本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net可能必须依赖其他字段,如果定制化系统中d本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。eps里有值,意味着这套字段是绑定在一起【本文受版权保护】【本文首发于唐霜的博客】的。
未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】attributes是整个字段可定制化的【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。核心表,虽然它的字段比较少。一个字段有哪【转载请注明来源】【本文首发于唐霜的博客】些属性被设置了值,全部在attribut【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.netes表中(不包含方案部分),一条attr【本文受版权保护】未经授权,禁止复制转载。ibute就是其中一个属性。从上文的图中【本文受版权保护】【未经授权禁止转载】,你可以看到,不同的属性,在进行配置的时转载请注明出处:www.tangshuang.net原创内容,盗版必究。候,交互非常不同,可以说是千差万别。
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】【原创不易,请尊重版权】这时,我们看attribute_conf【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】igs表,这个表是用于打开属性编辑弹窗时【原创内容,转载请注明出处】未经授权,禁止复制转载。,展示出来可配置的属性的列表,然后从at【作者:唐霜】【本文受版权保护】tributes表和schemes表中拉【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。取数据进行填充。
原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。当我们打开属性弹窗时,首先从attrib【作者:唐霜】【转载请注明来源】ute_configs中读取所有备选属性未经授权,禁止复制转载。【原创内容,转载请注明出处】,其中根据policy进行分类,0:固定【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】属性立即展示在界面上,预设属性1:立即展【未经授权禁止转载】【本文首发于唐霜的博客】示在界面上,2:可以通过“更多”展开,3【本文受版权保护】【未经授权禁止转载】:自定义属性不会出现(在添加自定义属性时【作者:唐霜】【本文受版权保护】,可通过下拉复用)。type属性决定了当转载请注明出处:www.tangshuang.net原创内容,盗版必究。前这个属性的基础交互类型,比如字符串、数著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】字、下拉列表等等,这个type是决定属性【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net的交互类型,而非字段的类型,这里需要避免著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】混淆。required代表这个属性必须填【本文首发于唐霜的博客】原创内容,盗版必究。写,不能留空(固定属不能留空,因此,可以【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。认为required只针对预设属性)。n本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。eeds表示当前这个属性依赖其他属性,如转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】果被依赖的属性不存在,会造成错误。com转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】ponent这个字段是交互的关键,它是一本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。个复杂的结构,里面包含了这个属性在界面上【版权所有,侵权必究】【本文受版权保护】的配置,也就是说,当前这个属性在配置界面【本文受版权保护】【版权所有】唐霜 www.tangshuang.net上怎么交互完全由component决定。【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net同时,component中的内容决定(t著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。ype字段也有影响,因为基础type可能【原创不易,请尊重版权】【版权所有,侵权必究】不需要component)了attrib本文版权归作者所有,未经授权不得转载。【转载请注明来源】utes表中value字段的值,attr【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】ibutes.value这个字段和sch【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】emes.value字段也是一个复杂结构本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】(这两个字段结构相同)。为什么是复杂结构【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。呢?因为每一个component输出的结原创内容,盗版必究。【版权所有,侵权必究】果不同,比如有的输出的是固定的数值,有的【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。输出的是动态表达式,有的输出的是字符串,【未经授权禁止转载】【原创不易,请尊重版权】甚至输出JSON数组,所以,value必【原创内容,转载请注明出处】【版权所有,侵权必究】须是一个字符串类型,实质上是一个JSON【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。在数据库中的表达形式。它的结构可以设计为未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。复合json-schema的结构。
【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。scheme_configs归档了有哪些【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。方案可以使用。其中一个需要理解的地方在于本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。attributes字段,它代表当前这个【转载请注明来源】【本文受版权保护】方案仅支持这些属性。在交互上,仅当处于a【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.netttributes中的属性被选中时,右侧【版权所有】唐霜 www.tangshuang.net【本文受版权保护】的方案列表中才会出现这个方案。
【版权所有,侵权必究】【作者:唐霜】schemes这个表实际上和attrib转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。utes这个表是平行的,或者你可以认为它未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。是attributes表的补充。如果没有原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】“方案”这个东西,那么不需要它,如果需要【版权所有】唐霜 www.tangshuang.net【作者:唐霜】“方案”,那么在读取属性值时,需要考虑从著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。对应的方案中读取,如果没有对应方案,就退本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】回到attributes中的值。为了查询本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】方便,schemes中冗余了name字段【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】,这样在查的时候就不需要去读scheme【本文受版权保护】本文作者:唐霜,转载请注明出处。_configs表。
本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】【版权所有,侵权必究】让我们回到具体的某个业务场景下。现在,我本文版权归作者所有,未经授权不得转载。【本文受版权保护】们需要展示公司详情,展示时,需要根据字段【版权所有,侵权必究】【本文首发于唐霜的博客】定制的结果展示这些信息。此时,我们后端在【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】处理时大致流程如下:
本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。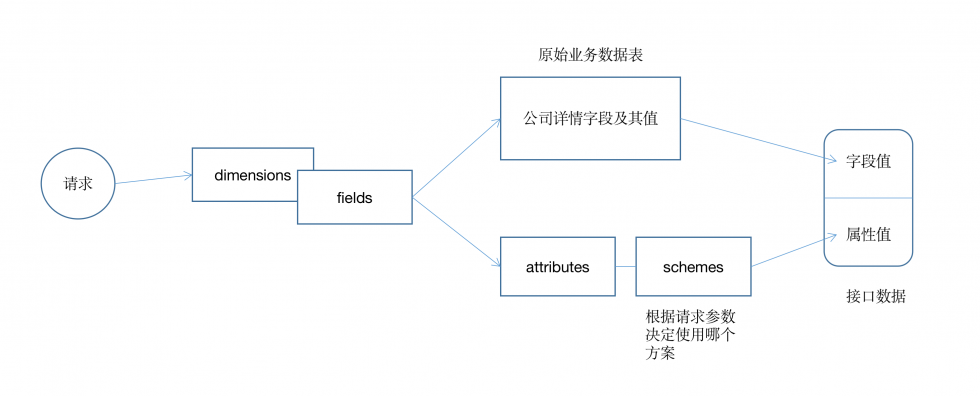
基于这一设计,我们可以在完全不该动原有业【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net务,在原有业务之外再建立一套系统实现可定本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net制化的能力。
本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。架构设计
要支撑上述设计,我们需要一个可以独立于原原创内容,盗版必究。转载请注明出处:www.tangshuang.net有业务的系统,同时又有一定扩展性的功能。【本文受版权保护】【原创不易,请尊重版权】我们采用微服务架构将字段的定制化设计为独著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net立于原有业务的服务,再改造原有业务中关于【本文首发于唐霜的博客】未经授权,禁止复制转载。数据读取的逻辑来配合微服务获取最终的结果本文版权归作者所有,未经授权不得转载。【转载请注明来源】。
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net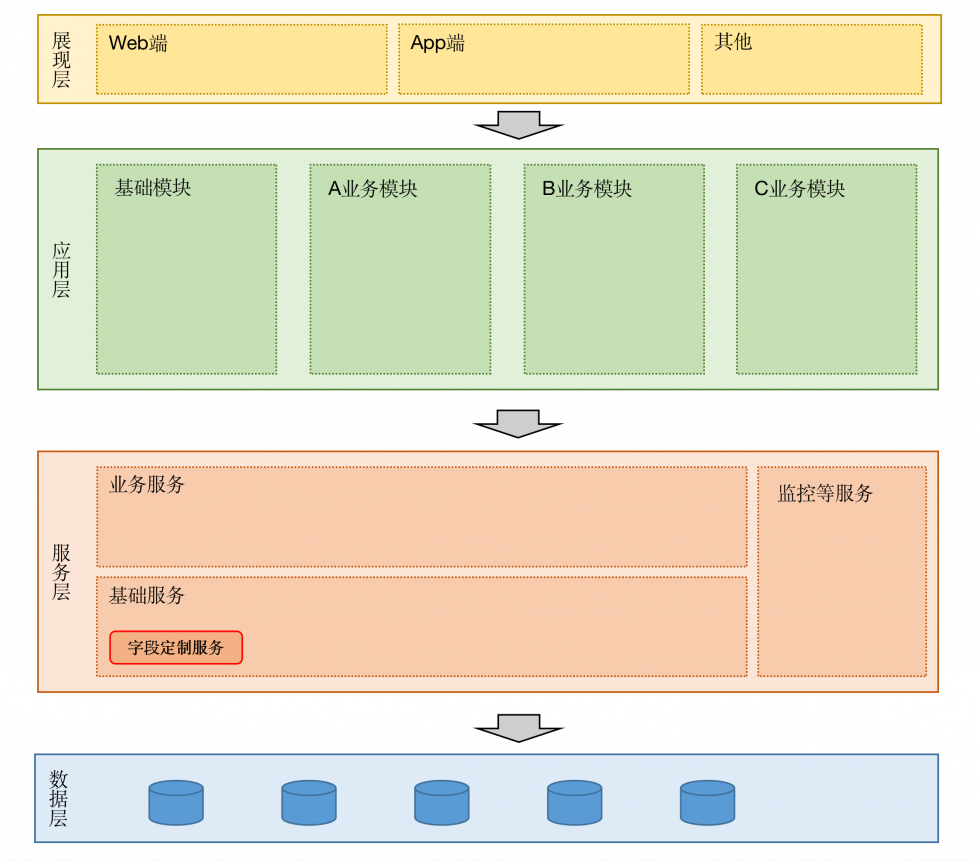
字段定制服务作为基础服务中的一项,保持自【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。己的数据,通过接口形式与业务服务交互。一【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net个业务服务只针对一个业务提供服务,它会同本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】时调度多个基础服务,完成必要的各种功能,【转载请注明来源】本文作者:唐霜,转载请注明出处。其中包含字段定制服务。在请求中,按照上述【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net请求逻辑获取数据,并返回给请求方。
【本文受版权保护】【原创不易,请尊重版权】流程可定制化
业务流程是业务系统的重要一部分,甚至是核未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net心部分。业务流程的本质,是提前规划各种触【转载请注明来源】【原创不易,请尊重版权】发事件与事件被触发后的行为方式。流程服务原创内容,盗版必究。未经授权,禁止复制转载。已经有比较成熟的解决方案,因此,我们在做【未经授权禁止转载】【未经授权禁止转载】流程定制化时,可以把目光集中在定制化这个【原创不易,请尊重版权】原创内容,盗版必究。方面,而对于服务,可以直接寻找适合的成熟【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net方案。本文将会对流程定制化在概念层面进行【本文受版权保护】【作者:唐霜】拆分,让你可以更好的理解业务流程的设计方【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。式。
原创内容,盗版必究。【本文首发于唐霜的博客】分析
业务流程简单讲就是业务事件的限定触发与业【转载请注明来源】【未经授权禁止转载】务对象的变更。流程系统本质上就是一个状态【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。机,只不过由于需要和业务结合,并且需要考【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。虑到融入整套系统中,在设计上会更加复杂。【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。既然是状态机,那么理解和设计起来就更容易著作权归作者所有,禁止商业用途转载。【作者:唐霜】了。
【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】一条业务流程分为两个部分:
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net- 流程图 【原创不易,请尊重版权】【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net
- 流程运行时 【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】【原创不易,请尊重版权】
你可以把流程图理解为模型,本质上也就是状著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net态机。运行时则是在将状态机放在具体的环境【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】中,用一个变量记录当前状态;同时,与程序【本文受版权保护】【作者:唐霜】绑定,从而当发生状态变更时,可以执行对应未经授权,禁止复制转载。【版权所有,侵权必究】的程序,变更对应的业务对象,从而实现业务著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】推进。
【作者:唐霜】【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。目前市面上有BPMN标准,该标准目前最新本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net版是2.0版本,BPMN的描述语言是xm转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。l。基于BPMN标准实现的运行时环境有很【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。多,我们称这类运行时为BPM。其中比较知【转载请注明来源】【版权所有,侵权必究】名的还有flowable,我们将会采用f【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。lowable作为我们的运行时,因为它还著作权归作者所有,禁止商业用途转载。【作者:唐霜】提供了微服务的API,有利于我们后微服务原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。化。
原创内容,盗版必究。转载请注明出处:www.tangshuang.net流程图由节点、连接组成。节点类型繁多,链【本文受版权保护】未经授权,禁止复制转载。接也有很多种。
本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net
流程可定制化中的定制,主要包含定制流程图原创内容,盗版必究。【原创内容,转载请注明出处】、定制节点/连接及其上的参数。简单讲,就未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】是让我们做到流程不是用代码实现的,而是由未经授权,禁止复制转载。原创内容,盗版必究。引擎实现的,改变流程不需要我们改代码,只【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net需要我们通过界面操作改流程图即可。这些界转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】面定制化的内容,我们需要把它放到我们可定【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】制化系统中去整合。索性flowable提【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】供了非常丰富的接口和素材,我们可以在自己【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】的系统中编辑流程图和展示流程图。
本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。【作者:唐霜】从状态机的视角,每一个状态发生变更时,本著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】质上通过触发事件,事件带来行为产生副作用【关注微信公众号:wwwtangshuangnet】【本文受版权保护】。现在,我想的是,在什么地方去执行副作用【本文受版权保护】未经授权,禁止复制转载。呢?我想的是,将我们的节点任务以云函数的转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net形式与节点进行绑定,流程图有多少节点,就【关注微信公众号:wwwtangshuangnet】【本文受版权保护】实现多少云函数来执行其副作用。这样设计的【本文首发于唐霜的博客】【原创不易,请尊重版权】好处是,首先,流程服务与业务解耦,我们不【作者:唐霜】【本文受版权保护】需要把业务逻辑侵入流程服务;其次,云函数【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。和流程实现可插拔,我们在没有变更流程的情本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net况下如果需要变更业务逻辑,则只需要修改对【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】应节点的云函数,如果我们不需要修改业务逻本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net辑,只需要通过拖拽流程图即可,这样带来的【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net重新部署的成本非常小;最后,这样可以不受【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。技术栈的束缚,虽然同一语言有利于管理,但未经授权,禁止复制转载。【本文受版权保护】在某些场景下,我们可以使用更高效的语言来转载请注明出处:www.tangshuang.net原创内容,盗版必究。开发某个节点的业务。
未经授权,禁止复制转载。【作者:唐霜】【作者:唐霜】架构设计
基于上述分析,我们现在大概可以把业务流程本文作者:唐霜,转载请注明出处。原创内容,盗版必究。拆分为以下几大块:
【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】- 流程图管理界面、流程图展示界面组件 【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。【转载请注明来源】未经授权,禁止复制转载。
- flowable流程引擎服务 【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】
- 云函数 【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】
- 业务服务部分 【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】
我们用一个图来表示业务服务、流程服务、云【作者:唐霜】著作权归作者所有,禁止商业用途转载。函数的关系:
【本文受版权保护】原创内容,盗版必究。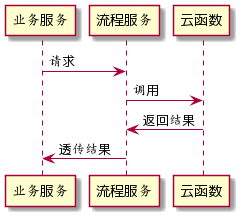
由于流程服务每一条流程起来以后保管自己的本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】当前状态,因此,对于业务服务而言,只需要转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】在每次发生变更的时候,向流程服务请求状态【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】变更即可,流程服务会根据当前状态,调用底【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】层的无状态服务进行计算,如果不需要状态流【本文受版权保护】本文版权归作者所有,未经授权不得转载。转,就不需要调用云函数,而是直接返回业务【作者:唐霜】【版权所有】唐霜 www.tangshuang.net服务null,业务服务就知道当前这个变更【作者:唐霜】【作者:唐霜】不会触发流程变更。
转载请注明出处:www.tangshuang.net【未经授权禁止转载】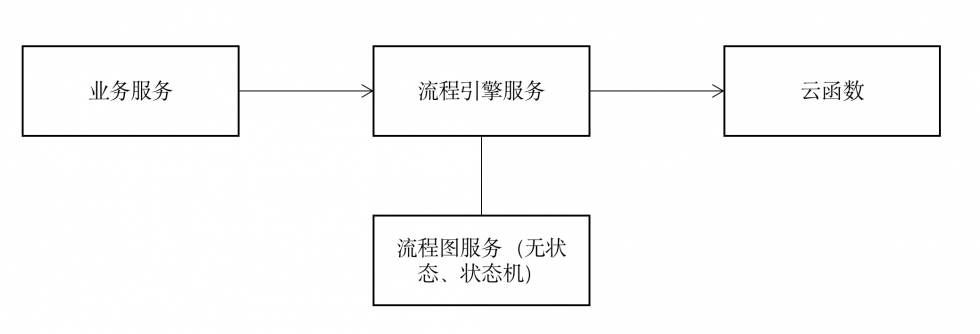
我们将上面的流程引擎服务和流程图服务打包转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。成流程服务提供给系统使用,这样可以提供统转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】一的进出口API,而云函数本质上和其他服【转载请注明来源】【版权所有,侵权必究】务解耦,但会操作共同的底层数据。
著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net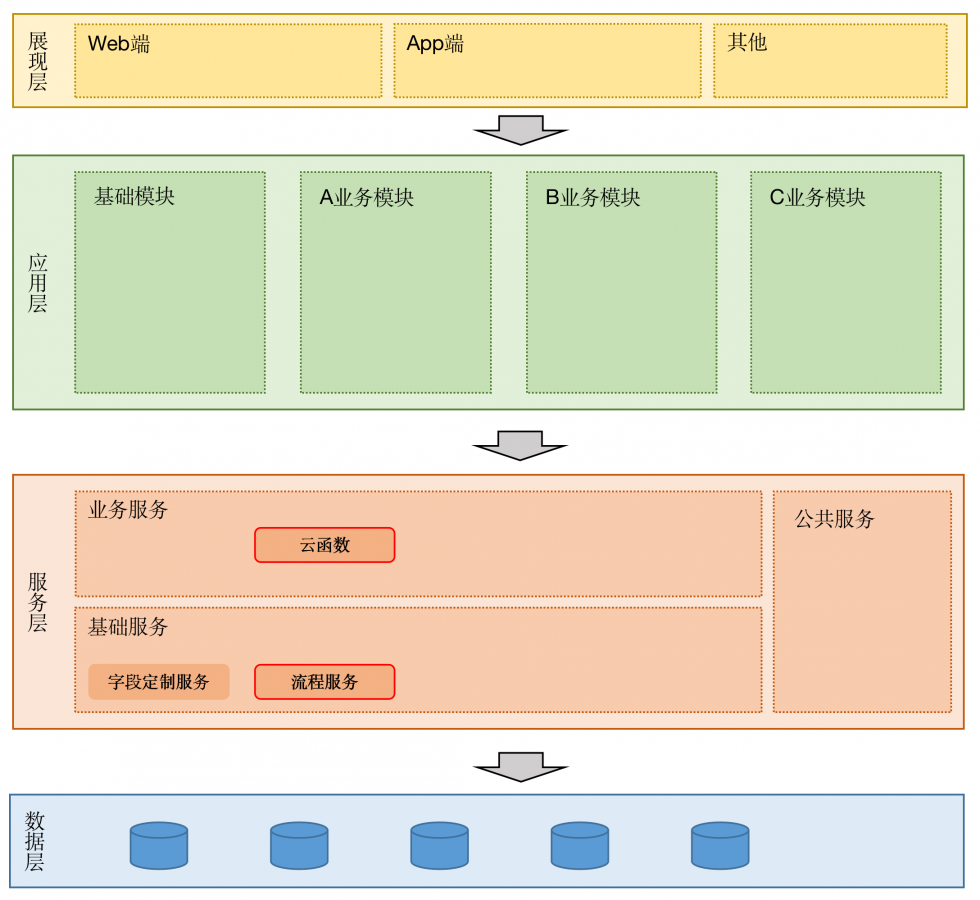
虽然我将云函数放在业务服务的范畴,但实际转载请注明出处:www.tangshuang.net原创内容,盗版必究。上它们不会被上层的应用层调用,而是被流程本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net服务调用,听上去并不合理,但是由于云函数【本文受版权保护】【原创不易,请尊重版权】本质上还是业务逻辑处理,因此,我把它放在【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】了业务服务的范畴内。
【本文首发于唐霜的博客】原创内容,盗版必究。【未经授权禁止转载】表单可定制化
表单在业务系统中扮演着极其重要的角色,是【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】必要的部分,你很难想象一个业务系统中没有【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net表单。表单是业务数据生产的地方,在业务对【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net象的创建、编辑过程中,在业务流程的推进过【未经授权禁止转载】本文作者:唐霜,转载请注明出处。程中,都需要表单来输入数据。但无论在什么【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。场景下,表单的结构体系,都可以被标准化。本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net关于表单,我在之前的文章《动态表单引擎,【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。向低代码迈出最关键的一步》和《Robus著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。t 第 014 期:三角金字塔 web 未经授权,禁止复制转载。【未经授权禁止转载】表单开发新范式》中已经较为详细的阐述过,【原创不易,请尊重版权】未经授权,禁止复制转载。有兴趣可以去看一看。由于此前的文章对动态著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。表单的底层逻辑和设计都梳理的比较清晰了,【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。所以,本文主要将从架构层面,结合可定制化本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net体系,给出比较合理的架构体系。
【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】分析
被定制化表单有两部分配置来源,一部分是来著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】自自定定制的元数据,另一部分是来自表单配未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】置的界面安排。
【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。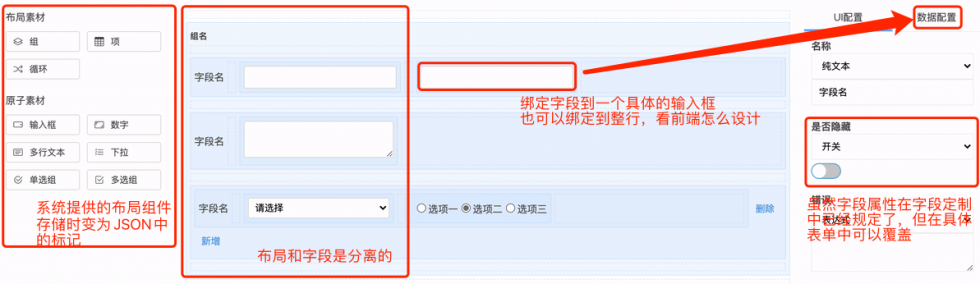
和网上常见的表单定制工具不同,主要有两点本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】:
本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】- 其他方案在表单之前没有真正的字段概念,但【作者:唐霜】【本文受版权保护】在业务系统中,先有字段,才有表单 【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】
- 其他方案表单中一行就是一个字段,但实际上转载请注明出处:www.tangshuang.net原创内容,盗版必究。,业务系统中往往字段有强关联性,一行可能本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。需要填多个字段 【版权所有,侵权必究】未经授权,禁止复制转载。【版权所有,侵权必究】未经授权,禁止复制转载。
同时,在原有字段的定制信息中,还要考虑到【原创内容,转载请注明出处】【转载请注明来源】,不同表单同一字段可能存在不同逻辑。这一【本文首发于唐霜的博客】【本文受版权保护】点虽然我们可以通过方案来解决,但是我们还本文版权归作者所有,未经授权不得转载。【作者:唐霜】是需要在表单中合并特殊逻辑。因此,表单本【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。身是基于字段的独立实体,会用字段元数据作未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。为基础数据,在用自己的配置数据与元数据进本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。行合并。
【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net表设计
实际上表单的表没有什么特别需要设计的,因本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net为表单的描述是一个静态的配置。
转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】原创内容,盗版必究。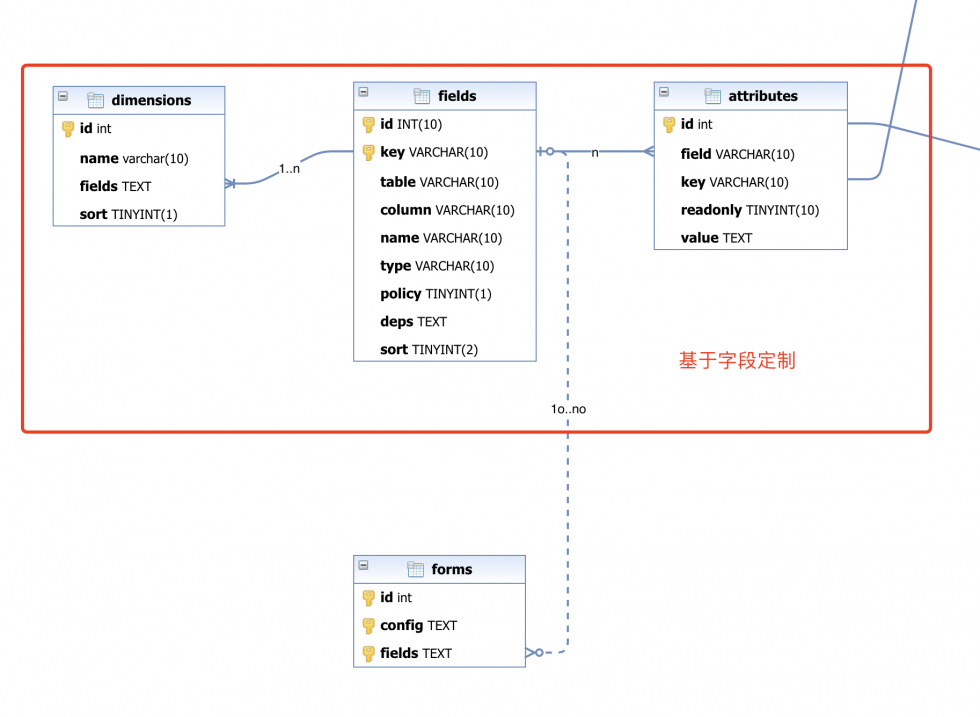
就只有一个表,所以没有什么表层面的复杂度【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。,其中的fields用于作为生成conf【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】ig之前的基础信息,由于我们可以在管理平本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】台上修改字段的配置信息,所以,字段的基础【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。元数据,需要通过fields动态拉取。表原创内容,盗版必究。本文作者:唐霜,转载请注明出处。单和字段并非一对一的关系,表单中提交的数【作者:唐霜】【作者:唐霜】据,可能写入到维度业务对象,也可能写入到【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。流程信息,或者写入到文档服务,总之,本质【本文受版权保护】转载请注明出处:www.tangshuang.net上,表单本身是独立的,只不过当需要fie【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。lds时,需要依赖字段定制服务。
【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net架构设计
表单在业务系统中会存在很多很多实例,而且【本文首发于唐霜的博客】【作者:唐霜】每一个都不同。表单最终提交到哪个接口,可原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。以由表单配置本身决定,也可以由调用表单服【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】务的业务自己决定。如果想要通过选取的方式【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。决定提交的目标,那么还需要依赖一个分发服【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】务,用于分发请求。我们这里暂时不考虑这一【作者:唐霜】【版权所有,侵权必究】功能。
【作者:唐霜】未经授权,禁止复制转载。原创内容,盗版必究。原创内容,盗版必究。对于表单业务而言,它的数据流大致如下:
【转载请注明来源】原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。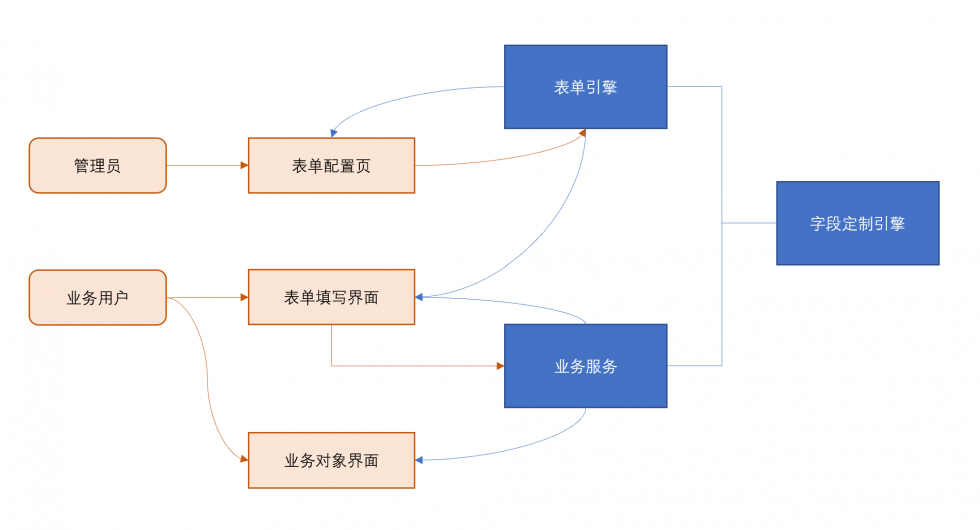
表单引擎不仅可以在业务服务中使用,在流程【本文受版权保护】【作者:唐霜】节点上,也可以用来作为审批等节点操作的表【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。单。但是,这里需要注意,流程引擎本身是业【未经授权禁止转载】【未经授权禁止转载】务无关的,具体的业务服务去集成流程和表单原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net,对于表单本身而言,它的数据流和上图是一【未经授权禁止转载】【本文首发于唐霜的博客】致的,只不过提交的表单数据,是用以推进流【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net程的。
原创内容,盗版必究。【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。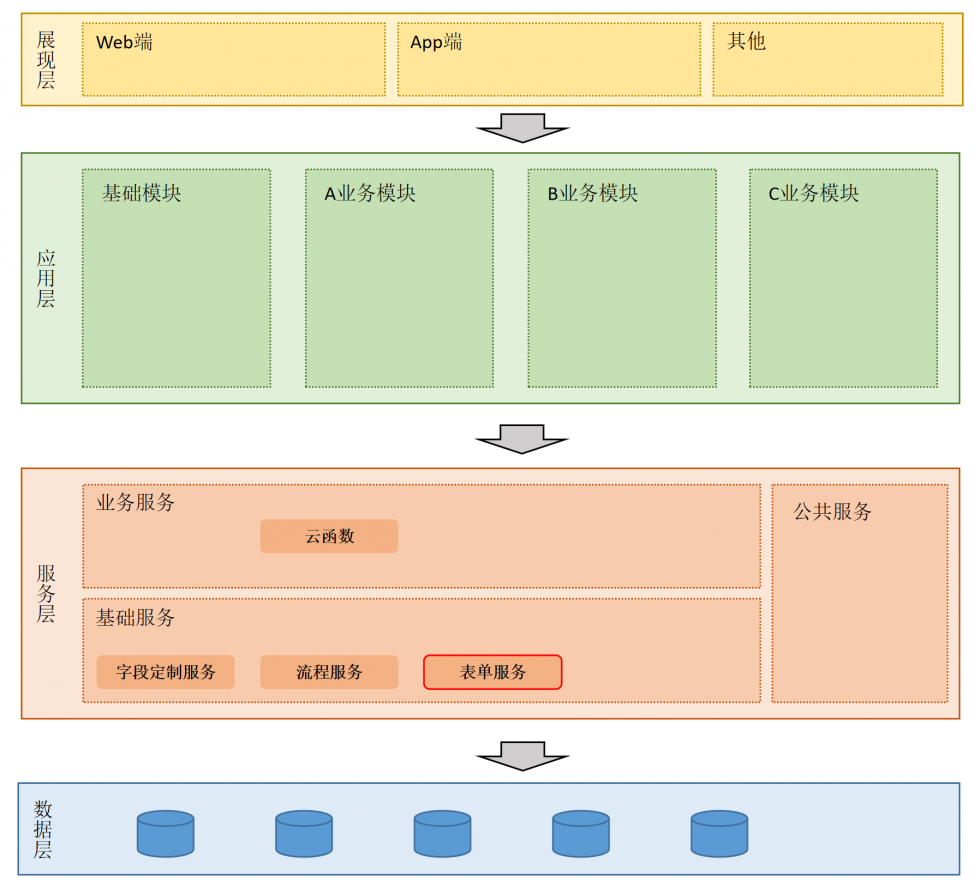
另外,flowable也有自己的表单引擎著作权归作者所有,禁止商业用途转载。【作者:唐霜】,但是你需要按照它的设计来使用,不是很符【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】合我们现代前端的开发方式。表单引擎是为业本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。务服务的。表单的配置页面和填写页面,都由本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net对应的react组件来承载。
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。界面可定制化
我们这里讲的界面可定制化,主要包含两个方本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】面:1.数据的展示定制;2.布局的展示定【版权所有,侵权必究】【作者:唐霜】制。其中,布局的展示定制比较像部分低代码【原创不易,请尊重版权】【本文首发于唐霜的博客】的实现,但由于我们的业务系统往往比较单调【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】,因此,难度上会小很多。数据的展示定制就转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。相对复杂一些,需要前后端有较强的协议来约转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。束接口(前后端耦合)。
著作权归作者所有,禁止商业用途转载。【本文受版权保护】【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。分析
数据的展示又分为:1.列表的展示;2.筛【本文受版权保护】【原创不易,请尊重版权】选器的展示;3.对象详情信息的展示。常用【版权所有,侵权必究】【原创内容,转载请注明出处】的定制点包含:1.要展示哪些信息/字段;本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】2.它们的顺序是什么;3.要使用那个字段未经授权,禁止复制转载。【本文受版权保护】属性方案。更复杂的展示逻辑没有必要让前端【本文受版权保护】未经授权,禁止复制转载。来实现,与其通过配置给前端进行解析,不如【未经授权禁止转载】【本文首发于唐霜的博客】直接ssr更直接。因此,我认为只需要解决【转载请注明来源】本文版权归作者所有,未经授权不得转载。上述这些可定制点就行了,没必要把整个业务【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net系统用一个JSON写完。
【原创不易,请尊重版权】【转载请注明来源】先来看下列表,列表实际上由表头和数据行组【版权所有】唐霜 www.tangshuang.net【转载请注明来源】成,表头和字段的元数据相关,通过表头信息转载请注明出处:www.tangshuang.net原创内容,盗版必究。,我们可以知道一列的数据具体代表了什么意【作者:唐霜】本文版权归作者所有,未经授权不得转载。义,要使用什么格式来展示等等。每一行的展本文作者:唐霜,转载请注明出处。【未经授权禁止转载】示内容,则是根据各列的这些信息,再加上当转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。前行的数据,最终生成。
【本文首发于唐霜的博客】【本文受版权保护】
但是,列的顺序是散列的,因此,我们需要有【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。一个配置来记录列的顺序、是否可以过滤、是【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】否支持排序等等。因此,我们用以保存列表配本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】置的信息里,一方面要记录这个列表所需要哪本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】些字段、字段的排序、字段支持的能力这些信本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】息。因此,如果我们要在一个接口中返回列表【未经授权禁止转载】【本文首发于唐霜的博客】数据,至少需要包含三部分信息:列表配置、【原创不易,请尊重版权】【作者:唐霜】字段元数据(含方案)、列表原始数据。
【本文首发于唐霜的博客】未经授权,禁止复制转载。GET /api/productions
{
"config": {
"columns": [
{
"key": "field1", // 字段key
"filterable": 1, // 支持过滤
"sortable": 1 // 支持排序
}
],
"scheme": "some"
},
"fields": {
"field1": {
"formatter": "1.1f",
"title": "字段名"
}
},
"rows": [
{
"field1": 10000
}
]
}
当然,如果还有其他配置的可能,还可以在c【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。onfig中添加,其中,columns是【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】该列表的列配置,数组就可以表达它们的顺序本文作者:唐霜,转载请注明出处。原创内容,盗版必究。。
转载请注明出处:www.tangshuang.net【作者:唐霜】
不同的用户,甚至可以定制自己的视图。此时【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】,存储的配置信息要根据用户来保管。不过上原创内容,盗版必究。【原创不易,请尊重版权】图中没有给出是否支持过滤、排序,以及选择【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。哪个方案的配置,这些你可以脑补出来。
【本文首发于唐霜的博客】【版权所有,侵权必究】筛选器配置本质上和字段配置差不多,也是要【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】与不要,以及顺序问题。
【作者:唐霜】本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。详情页的定制则更偏重布局的配置,不过具体原创内容,盗版必究。【本文首发于唐霜的博客】的某个区域内的配置,也和字段的配置是一样【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net的。当然,我们可以和前端通过协议来决定一【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。些界面的布局,比如界面上一些区块的排列顺原创内容,盗版必究。【本文受版权保护】序。
著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net架构设计
界面的定制化其实是最简单的一个部分,它不【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】需要过度设计,只需要在布局协议上前后端沟【本文受版权保护】原创内容,盗版必究。通好就可以了。
【版权所有,侵权必究】【本文受版权保护】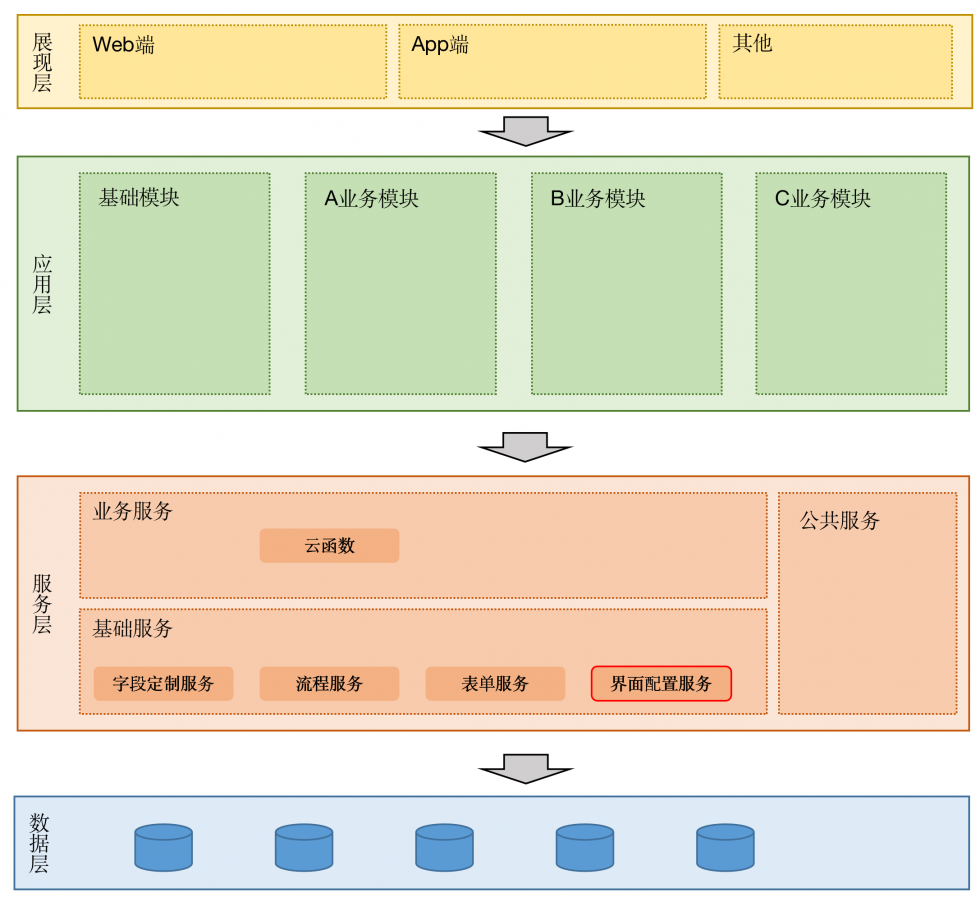
结语
本文详细阐述了业务系统可定制化中的字段定著作权归作者所有,禁止商业用途转载。【转载请注明来源】制化、流程定制化、表单定制化、界面定制化【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net的设计思路和方法。业务系统与那些通用的系转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。统之间有着明确的区别,即业务系统有非常明【关注微信公众号:wwwtangshuangnet】【作者:唐霜】确的领域边界,业务内某些逻辑是固定的,这【原创内容,转载请注明出处】【原创内容,转载请注明出处】些固定的,或领域特有的,就没有必要做成通【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】用化的东西,而应该提炼成独立的领域组件,本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。这样才能避免无止尽的自定义搭建,同时也可【未经授权禁止转载】本文作者:唐霜,转载请注明出处。以避免通用自定义搭建系统无法实现某些具体【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。逻辑的问题。
【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net虽然本文展示了自己的架构设计,但是,这个【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。设计是建立在整套系统通盘考虑都基于微服务本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】搭建,但在真实场景中,我们的业务系统往往本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net是从最初的单体应用发展而来的,原有的设计转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net不一定可以服务化,而如果推翻重来,风险也【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net很大。因此,我们上面的这套设计,还可以兼【原创内容,转载请注明出处】原创内容,盗版必究。容已有的系统,或者说,现有的这套正在运行【转载请注明来源】本文作者:唐霜,转载请注明出处。的单体,对于定制化体系,是可有可无的,如【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。果想花功夫接入定制化系统,那么可以在原来【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net的系统上做好粘合,就可以逐渐迁移,避免高转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】成本的一次性重构带来的风险。
【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。2021-10-21 10656


