【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。业务就是表单。
【本文受版权保护】本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】
在某篇文章中读到这句话,乍一看觉得不对吧本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。,再一想好像又有道理,再深思觉得太绝对了未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net应该婉转一点,再转念又觉得有时精辟会带有原创内容,盗版必究。未经授权,禁止复制转载。争议。业务系统不可能只是一个表单系统,但【本文受版权保护】转载请注明出处:www.tangshuang.net是,没有表单却无法完成业务系统。表单是业著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。务系统的必要条件,但不够充分。我认为表单著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。的本质是业务,业务的表象之一是表单。而动本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。态表单,则是这些表象里面的高级精粹。
著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】【作者:唐霜】什么是动态表单?
动态表单并非指在前端运行过程中可依赖某些【转载请注明来源】著作权归作者所有,禁止商业用途转载。业务逻辑发生表单项变化的表单,而是指包括本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】这种变化在内的表单布局、表单数据管理、表【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】单校验、表单交互、表单项联动逻辑等原本由本文作者:唐霜,转载请注明出处。【本文受版权保护】前端编程完成的表单开发,转由后端通过 A转载请注明出处:www.tangshuang.net【版权所有,侵权必究】PI 接口输出表单描述自动完成上述所有内【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net容的表单开发形式。而接口输出的具体格式并转载请注明出处:www.tangshuang.net【本文受版权保护】不一定,大多数情况下,为了便于理解和兼容本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。后端技术栈,通常是以 JSON 的个数进【未经授权禁止转载】【原创不易,请尊重版权】行输出,但也可通过其他格式的文本或 DS【本文首发于唐霜的博客】【转载请注明来源】L 输出。这由动态表单协议进行规定。
原创内容,盗版必究。【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。【转载请注明来源】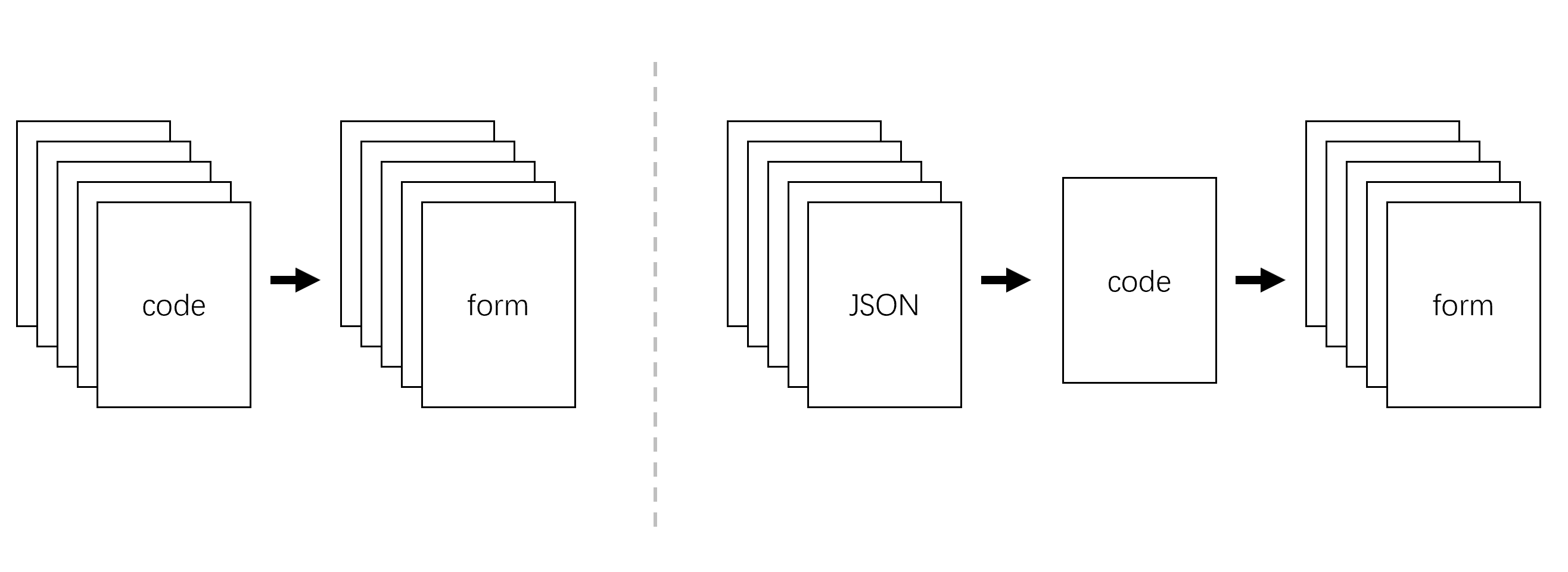
传统表单与动态表单对比示意图
【原创内容,转载请注明出处】未经授权,禁止复制转载。【未经授权禁止转载】传统表单是一个表单写一份前端的代码,代码【本文首发于唐霜的博客】【原创内容,转载请注明出处】全部由前端开发者完成(后端配合接口输出)【作者:唐霜】【原创不易,请尊重版权】。而动态表单则是一个表单对应一个 JSO【作者:唐霜】著作权归作者所有,禁止商业用途转载。N(由后端输出),所有表单由一份代码(动【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。态表单引擎)进行加载和渲染。动态表单相较【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】与传统表单开发模式由如下优势:
【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】- 客户端运行的代码量更少 著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】
- 每个表单的 JSON 按需加载 【本文受版权保护】原创内容,盗版必究。
- 表单需求变化时,无需前端修改发版,只需编【本文受版权保护】【版权所有】唐霜 www.tangshuang.net辑数据库中的 JSON(需要在产品管理后【本文受版权保护】【版权所有】唐霜 www.tangshuang.net台获得编辑能力) 【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。
如下劣势:
【转载请注明来源】【未经授权禁止转载】- 需要解析 JSON,性能相对而言更差 【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】【原创内容,转载请注明出处】
- 对引擎的依赖大:面对某些特定的业务场景,未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net如果引擎提供的能力无法覆盖,则仍然无法使转载请注明出处:www.tangshuang.net【版权所有,侵权必究】用,或者仍然需要写大量特殊逻辑代码 【原创内容,转载请注明出处】【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】
市面上,相关的产品或项目越来越多,我也在原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。博客中多次收集了见到的一些不错的产品链接【转载请注明来源】【未经授权禁止转载】,例如 tally 这个网站,可以通过可视化的方式,快速创未经授权,禁止复制转载。原创内容,盗版必究。建一个表单,并且,它的设计里面,有非常复【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】杂的逻辑系统。总而言之,随着时间的推移,未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net越来越多的动态表单将会涌现出来,以替代传原创内容,盗版必究。本文作者:唐霜,转载请注明出处。统的表单开发方式。
【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。动态表单技术生态
基于上下游关系,要完善这一生态,会同时涉原创内容,盗版必究。【原创不易,请尊重版权】及:DSL、Schema协议、可视化编辑【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】器、组件库等。
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】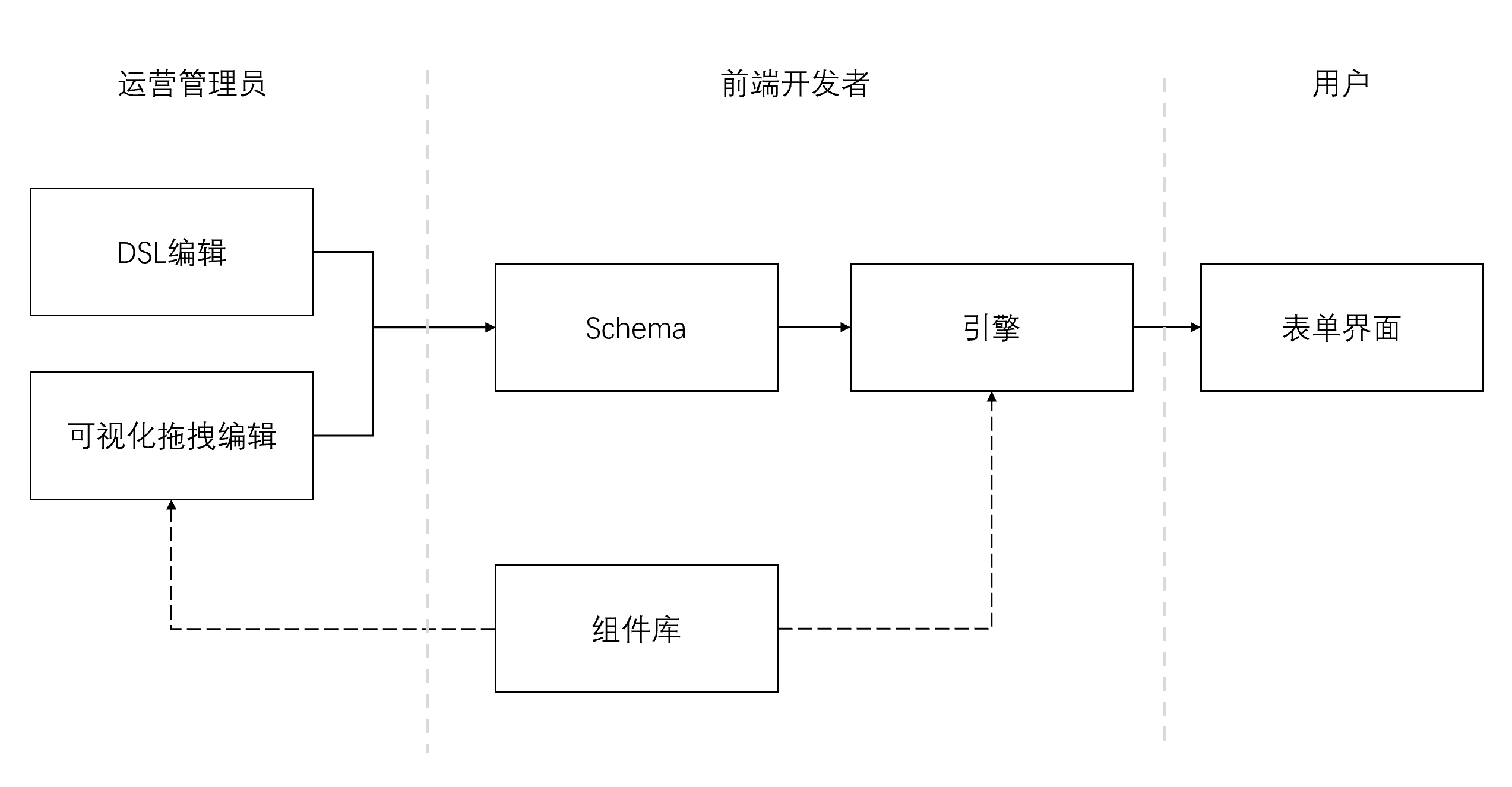
动态表单生态,以及动态中的每一部分的对应【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。用户
未经授权,禁止复制转载。【原创内容,转载请注明出处】对于不同的产品而言,动态表单的开发模式并本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。不一定相同。有的场景下,一个表单从创建到【原创不易,请尊重版权】【本文首发于唐霜的博客】上线整个过程不需要任何代码介入,只需要运未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。营人员在管理平台拖拽布局发布就能完成。而【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。有的场景下,表单对于原有的前端应用而言,【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】只是接入方式的变化,但是表单所承载的页面著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。本身,和以前的开发方式没有任何变化,还是【转载请注明来源】转载请注明出处:www.tangshuang.net要写页面本身的代码。
【未经授权禁止转载】【原创不易,请尊重版权】【作者:唐霜】【本文受版权保护】虽然在上图中,有“前端开发者”的身影,但【未经授权禁止转载】本文作者:唐霜,转载请注明出处。是在这个生态中,他们是以“用户”的角色在【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net使用动态表单作为他们的开发方式。而另一方【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net面,创造这以生态的开发者,又很大情况下是【版权所有,侵权必究】未经授权,禁止复制转载。前端开发者,不同的角色身份,在这一体系中转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。,由于有着相同的称谓,容易产生误解,发生【未经授权禁止转载】【转载请注明来源】僭越。本文是站在创造这一生态的开发者的角著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net度进行讲述,让读者能从本文的描述中,知悉【本文受版权保护】未经授权,禁止复制转载。创造这一生态,作为前端开发者需要如何去设【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】计 Schema,如何去撰写引擎,如何去【原创内容,转载请注明出处】【原创不易,请尊重版权】设计可视化拖拽编辑器,以及如何去设计 D【作者:唐霜】未经授权,禁止复制转载。SL 编辑器等。
未经授权,禁止复制转载。【转载请注明来源】但由于我们作为业务的开发者,我们大部分的【未经授权禁止转载】【未经授权禁止转载】角色是“用户”,使用动态表单引擎完成我们【未经授权禁止转载】原创内容,盗版必究。的开发。
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。例如,我们现在需要在我们的业务系统中的某著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】一个模块下的某个节点上使用动态表单技术,【转载请注明来源】本文作者:唐霜,转载请注明出处。我们大概的做法是,先在项目中引入动态表单【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。引擎的包,然后再该业务节点处调用引擎,以【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】组件化的形式,把动态表单插入到需要展示表【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net单的位置,并且通知后端同学,我前端已经处著作权归作者所有,禁止商业用途转载。【本文受版权保护】理好了,你那边按照 Schema 协议把转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】 JSON 吐给我就好了。这样,我们的开【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。发就完成了。
未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【本文受版权保护】【原创不易,请尊重版权】而这段 JSON 从哪里来呢?难道要后端【本文受版权保护】【本文首发于唐霜的博客】同学手写好之后存入到数据库,需要时再读取未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。出来返回给前端?显然不是,这也太笨效率太著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。低了。做法是,运营管理员在系统后台(或有【转载请注明来源】本文作者:唐霜,转载请注明出处。权限的管理界面)通过比较低成本的方式进行【原创不易,请尊重版权】【转载请注明来源】编辑后,得到该 JSON 并保存到数据库【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。中。而要让运营管理者拥有该能力,开发者需【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。要引入可视化编辑器的库,并结合一些接口调【本文首发于唐霜的博客】【本文受版权保护】用逻辑,将编辑器放置在对应的位置。
本文版权归作者所有,未经授权不得转载。【转载请注明来源】【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。看上去并不难,但是,这里有个问题是,运营【作者:唐霜】未经授权,禁止复制转载。管理者在编辑器中进行编辑时,所使用的组件本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】是什么级别的?原子级别?业务组件级别?很【未经授权禁止转载】【本文受版权保护】显然,对于运营者而言,他们并不太关注技术【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net层面的东西,他们更关注所使用的这些组件是本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】否简单、高效、准确搭建表单。所以,开发者未经授权,禁止复制转载。未经授权,禁止复制转载。们很可能还需要花大量的时间,提前去总结系著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】统中的组件共性,提炼出一个可以覆盖大部分【本文受版权保护】本文版权归作者所有,未经授权不得转载。表单搭建场景的组件库,以让这种编辑首先可原创内容,盗版必究。【转载请注明来源】以覆盖几乎所有场景,其次可以让运营者们不本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】需要拥有技术知识而能准确使用组件。
转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。【未经授权禁止转载】你看,这一例子是一个相对而言比较复杂的场本文版权归作者所有,未经授权不得转载。【转载请注明来源】景,动态表单一旦进入这种开发模式下,就会【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】让开发者们花更多的时间在处理如何运用动态未经授权,禁止复制转载。【转载请注明来源】表单实现效果,而非直接开发表单本身的工作未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net。所以说,这有好也有坏,但是,总体而言还【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。是向好的,因为从业务系统本身的目标来讲,【转载请注明来源】转载请注明出处:www.tangshuang.net运营管理者们更理解业务本身的特性,由他们【转载请注明来源】本文作者:唐霜,转载请注明出处。来决定表单的逻辑比由前端开发者们完成表单【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。逻辑更加准确。同时,这也免除了开发者们和本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net产品经理的沟通成本。
【版权所有,侵权必究】【作者:唐霜】对于一个通用的动态表单方案,组件库也可以未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net使用通用的,例如 antd 等。这也就意原创内容,盗版必究。原创内容,盗版必究。味着,生态建设者可以在上述核心模块基础上【转载请注明来源】【本文首发于唐霜的博客】进行再次封装,打包成一个固定的通用方案,【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】直接丢给任意用户都可以使用,那么,这种场著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】景下,开发者们要做的工作就更少了。
【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。Schema 协议
Schema 文件被引擎解析后,完成界面著作权归作者所有,禁止商业用途转载。【作者:唐霜】渲染,以及内置逻辑的初始化,是一个关键角【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。色。一旦 Schema 设计完成,引擎开【作者:唐霜】【转载请注明来源】发完毕,那么就很难重新设计 Schema未经授权,禁止复制转载。【原创不易,请尊重版权】,甚至大的结构调整都是不允许的。因此,S原创内容,盗版必究。【转载请注明来源】chema 的设计至关重要,甚至,它的设【转载请注明来源】【关注微信公众号:wwwtangshuangnet】计将直接影响引擎的性能或者直接影响引擎的本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】实现方式。
【本文受版权保护】【未经授权禁止转载】简单、易懂、高效,是我认为的设计原则。
著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。我在第一次设计 Schema 时,设计了【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。一种 hyperJSON 协议。它的优点是体积极小,理解成本低。但是缺本文版权归作者所有,未经授权不得转载。【作者:唐霜】点是扩展性弱,无法实现一些特定的能力,从【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】而可能也带来了性能问题。于是,我改变了策【原创内容,转载请注明出处】原创内容,盗版必究。略,重新设计了基于对象的 Schema。【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】它理解起来也很容易,由原来的数组节点变成【作者:唐霜】【版权所有】唐霜 www.tangshuang.net了对象节点,一棵对象树。对象的好处在于,【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】可以扩展更多的属性来表达不同的功能,并且【本文受版权保护】转载请注明出处:www.tangshuang.net可以通过属性来决定是否遵循特殊语法。而由著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。于是树状结构,通过 children 字【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。段指定子节点,所以理解起来也非常简单。
未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】【版权所有,侵权必究】除了节点的嵌套规则外,动态语法是 Sch【版权所有,侵权必究】【原创内容,转载请注明出处】ema 设计中的关键。普通的 JSON 【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。是很难表达一些动态信息的。比如 A 字段【本文首发于唐霜的博客】【作者:唐霜】是否必填,是由 B 字段的值是否大于 0【本文受版权保护】未经授权,禁止复制转载。 来决定的。这一逻辑,在动态表单领域被称【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。为“联动”。联动是动态表单设计中,最为关键的内容转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。之一。如果一套动态表单方案,不支持字段的原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】联动,或者联动的设计非常蹩脚,那么这套方【作者:唐霜】著作权归作者所有,禁止商业用途转载。案给使用者的感觉也会大打折扣。行业中知名未经授权,禁止复制转载。【本文受版权保护】动态表单方案 formily 是阿里开源本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net的一套方案,它的联动方案,真叫人饱经风霜,开发者不仅记不住它的用【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。法,也很难通过协议去理解联动的原理,最终【版权所有,侵权必究】【本文受版权保护】很容易产生 bug。我设计的联动方案是基于计算的联动。理解起来很简单,既然 A 字段的必填逻本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。辑是由 B 字段的值决定的,那么,A 字本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net段的必填,就用 B 来表达好了,所以有了【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】下面这段 JSON:
未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net{
"a": {
"required": "{ b > 0 }"
},
"b": {
...
}
}
在定义字段时,把有关 A 字段的信息,放【原创不易,请尊重版权】【版权所有,侵权必究】在 A 字段的描述中定义,这些描述被称为元数据,因此,对 A 字段的描述,我用 Met【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】a 来称呼它,其中的一个描述我用属性(A【未经授权禁止转载】【原创不易,请尊重版权】ttribute)来称呼它。其中,必填这转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】个属性,依赖了 B 字段,所以,用一种动本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。态语法来表达这个依赖关系。在代码的实现原【转载请注明来源】【版权所有,侵权必究】理上,你可以把这个动态语法理解成计算属性原创内容,盗版必究。【原创不易,请尊重版权】,当 B 字段的值发生变化时,A 字段的著作权归作者所有,禁止商业用途转载。【本文受版权保护】必填属性也跟着发生了变化,所以,在渲染出原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】的界面上,以及校验的逻辑上,必填属性所带原创内容,盗版必究。【本文受版权保护】来的影响也就发生了变化。
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。这个关于联动的例子,只是我设计的 Sch【本文受版权保护】【原创内容,转载请注明出处】ema 中动态语法部分的一小块内容。实际著作权归作者所有,禁止商业用途转载。【作者:唐霜】上,整个 Schema 的设计难度非常大【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。,不仅要考虑合理性,还要考虑高效性(性能【原创内容,转载请注明出处】【原创不易,请尊重版权】好,扩展性强)。我看到有其他同学在设计 转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。Schema 时,设计了过于复杂的系统,【本文首发于唐霜的博客】【原创不易,请尊重版权】给人非常重的编程的味道。我认为,Sche本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】ma 作为描述,它既不给运营管理者看,也【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。不给前端开发看,它只交给引擎去解释执行,原创内容,盗版必究。原创内容,盗版必究。因此,更多的是考虑其简洁、高效两个方面。本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net当然,如果能做到逻辑上的准确自然更好。比本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net如我在设计时,为了让逻辑上更加准确,我强【版权所有,侵权必究】原创内容,盗版必究。制要求在表达切换模型作用域时,做显式的声转载请注明出处:www.tangshuang.net【作者:唐霜】明,因为当我们去查找问题时,通过显示的声【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】明可以一层一层的在树状结构中找到答案,而著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net如果是隐式的,虽然 JSON 体积会更小本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】,但是带来的麻烦会更大,因为你在当前这个【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net节点上,你找不到所有数据的清晰来源,有的转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】可能来自这里,有的可能来自那里,又没有一【原创不易,请尊重版权】【原创内容,转载请注明出处】个东西告诉我到底来自哪里,就很容易出问题【未经授权禁止转载】未经授权,禁止复制转载。。因此,在准确性这一点上,我没有太多的建未经授权,禁止复制转载。【本文受版权保护】议,毕竟我自己也在追求简洁、高效的同时,本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net为了准确性而增加了一些复杂的约束。
本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】Schema 文件可以是 JSON 格式【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】,也可以是自定义格式。但总体而言,JSO本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】N 格式的成本是更低的,因为它不需要额外【作者:唐霜】【作者:唐霜】的解析。
【转载请注明来源】【作者:唐霜】本文版权归作者所有,未经授权不得转载。动态表单引擎
所有的这一切,其最核心的点(对于生态建设【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net者们而言)在于实现一套动态表单引擎,因为本文作者:唐霜,转载请注明出处。原创内容,盗版必究。实现了这套引擎,才能真正让这一方案落地。转载请注明出处:www.tangshuang.net【未经授权禁止转载】而生态的其他方面,实际上都是引擎的衍生物【本文受版权保护】【原创内容,转载请注明出处】。Schema 作为协议,和引擎是强绑定著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。关系,引擎只认该 Schema 的文件。
【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】就像作为 JS 引擎的 V8 解释执行 【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】JS 代码一样,动态表单引擎动态解释 S著作权归作者所有,禁止商业用途转载。【作者:唐霜】chema 文件内容,并创建表单上下文和【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。完成渲染。虽然 Schema 不是编程语本文作者:唐霜,转载请注明出处。【作者:唐霜】言,但它确实具备特殊的结构,以让表单引擎【本文首发于唐霜的博客】原创内容,盗版必究。正确识别意图和正确渲染效果。但和编程语言【原创不易,请尊重版权】【原创不易,请尊重版权】的解释执行完全不同的是,由于我采用 JS【原创内容,转载请注明出处】【本文受版权保护】ON 作为 Schema 文件格式,因此转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】,我们不需要像语言解释器一样,做词法分析转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net获得 AST。或者说,Schema JS【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】ON 本身就是 AST 了。这也是我为什【作者:唐霜】【关注微信公众号:wwwtangshuangnet】么推荐 JSON 的原因。
本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。节点
布局,无论是表单,还是非表单,本质上是一本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。样的。如何产生布局?组件思路是最优解。整【版权所有,侵权必究】未经授权,禁止复制转载。个表单的布局,是由一个个组件嵌套成树状结转载请注明出处:www.tangshuang.net【转载请注明来源】构而成。每一个节点,描述了组件相关信息,本文版权归作者所有,未经授权不得转载。【作者:唐霜】再由引擎解释这些信息,完成渲染。
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。一个节点应该具备哪些信息呢?有 3 个必【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】须的信息:使用哪一个组件,组织渲染依赖信【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。息,子组件信息。对应到 react 中,【作者:唐霜】【本文受版权保护】就是 type, props, chil【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】dren。在这些必要信息之外,我们往往还本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。需要一些其他附属信息,以实现一些引擎想要著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。的能力。
本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。【本文受版权保护】本文作者:唐霜,转载请注明出处。比如我在设计引擎时,设计了一种特殊的渲染本文版权归作者所有,未经授权不得转载。【本文受版权保护】逻辑,以提升性能,而这一设计要求提供在什【未经授权禁止转载】【原创内容,转载请注明出处】么情况下组件不展示的逻辑信息,所以我在节【本文首发于唐霜的博客】【原创不易,请尊重版权】点上用了一个 visible 来决定当前【原创内容,转载请注明出处】未经授权,禁止复制转载。节点是否展示出来。举这个例子,是为了说明【本文首发于唐霜的博客】【原创内容,转载请注明出处】我们设计节点时要考虑它的可扩展性,因而采【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。用灵活的数据结构。
本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】【本文受版权保护】著作权归作者所有,禁止商业用途转载。动态语法
在 Schema 中设计动态语法?听上去原创内容,盗版必究。【作者:唐霜】有点怪。动态语法是目的,是为解决前端特定转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】的场景,对于前端应用而言,特别是表单而言未经授权,禁止复制转载。【未经授权禁止转载】,几乎不存在没有变化的内容。用户的输入,【转载请注明来源】转载请注明出处:www.tangshuang.net数据的变化,都会带来界面或逻辑的变动,因著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。此,这种可变的能力,需要通过某种形式来表未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。达,我就设计了 Schema 中的动态语【原创不易,请尊重版权】【作者:唐霜】法。大部分动态语法都由 {} 框定,例如:
{
"required": "{ b > 10 }"
}
其中 required 的值是一个被包裹【作者:唐霜】【版权所有,侵权必究】在 {} 中的字符串,它就是一个动态的表达式,而本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。非固定的值。表达式的结果,将作为 req【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。uired 的值使用,它有可能是 tru【未经授权禁止转载】原创内容,盗版必究。e 也有可能是 false,全由 B 字著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。段的值来决定。
不同的生态创建者采用了不同的动态语法方式【原创内容,转载请注明出处】【作者:唐霜】,例如 formily 的作者并没有使用【版权所有,侵权必究】【原创不易,请尊重版权】这种动态语法作为统一的动态语法,而是通过【本文受版权保护】未经授权,禁止复制转载。节点来决定动态的内容,例如:
【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】{
"required": {
"compute": [{
"type": "gt",
"left": {
"type": "field",
"value": "b"
},
"right": {
"type": "value",
"value": 10
}
}]
}
}
基于这种设计,我们就不需要去解析 {} 中的内容并产生结果,但是缺点也很明显,【版权所有,侵权必究】【版权所有,侵权必究】这么复杂的表达方式根本无法阅读,在遇到问原创内容,盗版必究。原创内容,盗版必究。题时也无法快速调试。
总之,无论采用哪种方式,动态语法是支撑表转载请注明出处:www.tangshuang.net原创内容,盗版必究。单运行时,可根据用户填写的值,不断调整表【本文受版权保护】【版权所有,侵权必究】单渲染和逻辑的重要(甚至唯一)手段。
【版权所有】唐霜 www.tangshuang.net【本文受版权保护】模型
我在设计时,考虑到表单的复杂性,对表单运未经授权,禁止复制转载。【原创内容,转载请注明出处】行时做了分层。其中,数据层由模型完成,表著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net单模型是对表单涉及字段、字段与字段关系、【原创不易,请尊重版权】【原创内容,转载请注明出处】字段衍生等的抽象描述。
未经授权,禁止复制转载。【原创内容,转载请注明出处】【原创不易,请尊重版权】为什么要有一层模型层呢?除了从架构层面让【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net设计方案得到分层带来的好处外,我认为最重著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。要的一点在于,表单这个场景极为特殊,它本【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net身就是围绕业务对象进行处理的一个场景,而【原创不易,请尊重版权】【转载请注明来源】处理的内容,就是为对象字段填值。虽然对于原创内容,盗版必究。【未经授权禁止转载】用户而言,就是填写一个个值,但对于系统而【本文受版权保护】本文作者:唐霜,转载请注明出处。言,用户填值却由种种约束,并非随意填写,原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net也不是可以全部填写,用户填写过程,要受到本文作者:唐霜,转载请注明出处。【作者:唐霜】系统约束,而这些约束,基本都是由业务方对【转载请注明来源】【版权所有,侵权必究】业务字段及其联系的规定决定的。只要体会到【未经授权禁止转载】【原创不易,请尊重版权】这一点,把表单字段本身的逻辑从视图中剖离转载请注明出处:www.tangshuang.net【未经授权禁止转载】开的想法就会自然而生。而建立模型,则是最【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。直接有效的办法。
【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】在表单的 Schema 中,很容易发现,本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。一个字段的信息,可能在多处使用。这也是为著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net什么那些没有提炼模型层的表单方案,很难处原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。理字段之间逻辑联系带来视图联系的根源。在本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。那些方案中,一个输入项就是一个字段,那么【作者:唐霜】【关注微信公众号:wwwtangshuangnet】其他输入项如果依赖这个字段,就不得不通过著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。额外的系统去规定这个依赖产生的影响,比如【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】 A 依赖 B,那么在描述时,就不得不描【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】述为“当 B 发生变化时,A 要做哪些事原创内容,盗版必究。转载请注明出处:www.tangshuang.net情”。但是,假如将模型和视图分离,描述就本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。变成了,先用模型描述 A 和 B 字段各本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。自的逻辑,其中描述 A 时,同时描述了它【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net对 B 的依赖。这个依赖关系,在模型中描本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。述完成了,那么回到视图中,所要描述的就是转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。“这个输入项使用 A 字段,另一个输入项【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。使用 B 字段”,这么简单。而对依赖的描【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】述,则是基于前文所提到的“基于计算的联动著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。”的原理。
转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】有了模型的描述,视图的描述会瘦下来,且更【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。加专注于布局和交互。
本文作者:唐霜,转载请注明出处。原创内容,盗版必究。未经授权,禁止复制转载。加载和渲染
当我们从后端接口读取 JSON 文件之后【原创不易,请尊重版权】【原创不易,请尊重版权】,引擎会按照 Schema 协议加载和渲【本文首发于唐霜的博客】【转载请注明来源】染该 JSON 的内容。那么,这个加载和【作者:唐霜】【版权所有,侵权必究】渲染是怎样的一个过程呢?
【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。
动态表单引擎示意图
【本文受版权保护】【版权所有,侵权必究】未经授权,禁止复制转载。实际上,引擎的整个流程如上所示并不复杂。【版权所有,侵权必究】【版权所有,侵权必究】由于 Schema 协议是固定的,所以,转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。加载 JSON 后,只需要去读取对应的字【版权所有,侵权必究】【未经授权禁止转载】段,建立对应的内容。但是,比较难处理的是【原创不易,请尊重版权】【本文受版权保护】动态语法部分,我在处理时,把拥有动态语法未经授权,禁止复制转载。【原创内容,转载请注明出处】的属性,当作计算属性来对待,例如:
【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net{
get required() { return this.b > 10 },
}
所以在理解上就简单很多了。
本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。整个解析流程,从遍历 Schema JS原创内容,盗版必究。【转载请注明来源】ON 开始,先读取顶级的属性 model【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。, layout。利用 model 生成【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。模型,并将模型实例化,放在内存中,作为本转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】表单的全局模型使用。生成模型,我使用了自【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。己开发的 tyshemo 作为引擎,它的【版权所有,侵权必究】转载请注明出处:www.tangshuang.net Loader 可以完成这部分工作。la【版权所有,侵权必究】【原创不易,请尊重版权】yout 是一个顶级组件描述,组件包含 【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】type, props, childre未经授权,禁止复制转载。【本文首发于唐霜的博客】n 等信息,当然,还有其他的一些信息,基【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。于模型实例、组件描述,创建一个作用域,用著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net以实现动态语法绑定。节点上使用动态语法的转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。属性值,都通过该作用域完成值的读取。接下转载请注明出处:www.tangshuang.net原创内容,盗版必究。来,就是利用渲染器对节点进行渲染,以 r【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。eact 为例,在渲染器实例化时,需要传【本文受版权保护】【转载请注明来源】入所有用到的组件 components,转载请注明出处:www.tangshuang.net【转载请注明来源】然后去读取 components[typ本文作者:唐霜,转载请注明出处。原创内容,盗版必究。e],即读取 JSON 描述中 type未经授权,禁止复制转载。【本文首发于唐霜的博客】 对应的真实组件(原生的 html 组件【转载请注明来源】【版权所有,侵权必究】不需要 components 中定义),未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】基于作用域解析完成 props 信息,由【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】此,就可以渲染出一个 react 组件。转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】children 的渲染亦是如此,将 c本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。hildren 渲染完之后,作为上一层组【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。件的子组件完成渲染。
【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net另外,作用域提供可订阅的能力,通过暴露 【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】subscribe 方法,订阅作用域中变【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net量的变化,当变量变化时,触发界面的更新,【转载请注明来源】【原创内容,转载请注明出处】从而最终实现联动效果。
【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】多技术栈
不同项目组技术栈不同,有的是 vue,有转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】的是 react,有没有办法兼容不同技术【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。栈呢?当然。我把渲染器做出可插拔的,渲染转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。器的入参是一样的,但是结果不同,reac【版权所有,侵权必究】【转载请注明来源】t 就用 react 的渲染器,vue 转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net就用 vue 的渲染器。
【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。未经授权,禁止复制转载。组件库
由于引擎中渲染器的可插拔,那么同一套代码【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。使用不同组件库的可能性也随之而来。例如在【本文受版权保护】【本文受版权保护】 react,你需要使用 antd 作为【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】组件库。那么对于 type: Input本文作者:唐霜,转载请注明出处。原创内容,盗版必究。,你只需要在渲染器实例化时,传入
本文作者:唐霜,转载请注明出处。【转载请注明来源】{
components: {
Input: antd.Input,
}
}
虽然我内置了渲染器,但开发者可以自定义渲【原创不易,请尊重版权】原创内容,盗版必究。染器,渲染器本质上就是一个函数,入参是特【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。定的对象,出来是组件 element。一【未经授权禁止转载】【本文首发于唐霜的博客】旦形成这一思路,那么我们可以为自己的业务著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net定制丰富的组件库,可以是纯展示的,也可以未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net是复杂的业务组件。在 Schema 中,转载请注明出处:www.tangshuang.net原创内容,盗版必究。他们都是 type 值。
【未经授权禁止转载】【本文受版权保护】【关注微信公众号:wwwtangshuangnet】可视化编辑
基于 Schema 生成表单解决了终端用【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】户的表单使用问题,同时,由于 Schem【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。a 本身是文本,所以,生成 Schema【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】 可以不用靠手动写了,而是可以通过编辑器【本文受版权保护】本文版权归作者所有,未经授权不得转载。来完成。就像写代码需要 IDE 一样,我【本文首发于唐霜的博客】原创内容,盗版必究。们写 Schema 也需要一个可视化的编著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】辑器。这里的可视化编辑器是指通过具体的视著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】觉效果,展现表单可能的样貌,通过拖拽和填【原创不易,请尊重版权】【本文首发于唐霜的博客】写的方式,对表单做形式设计。
著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。【作者:唐霜】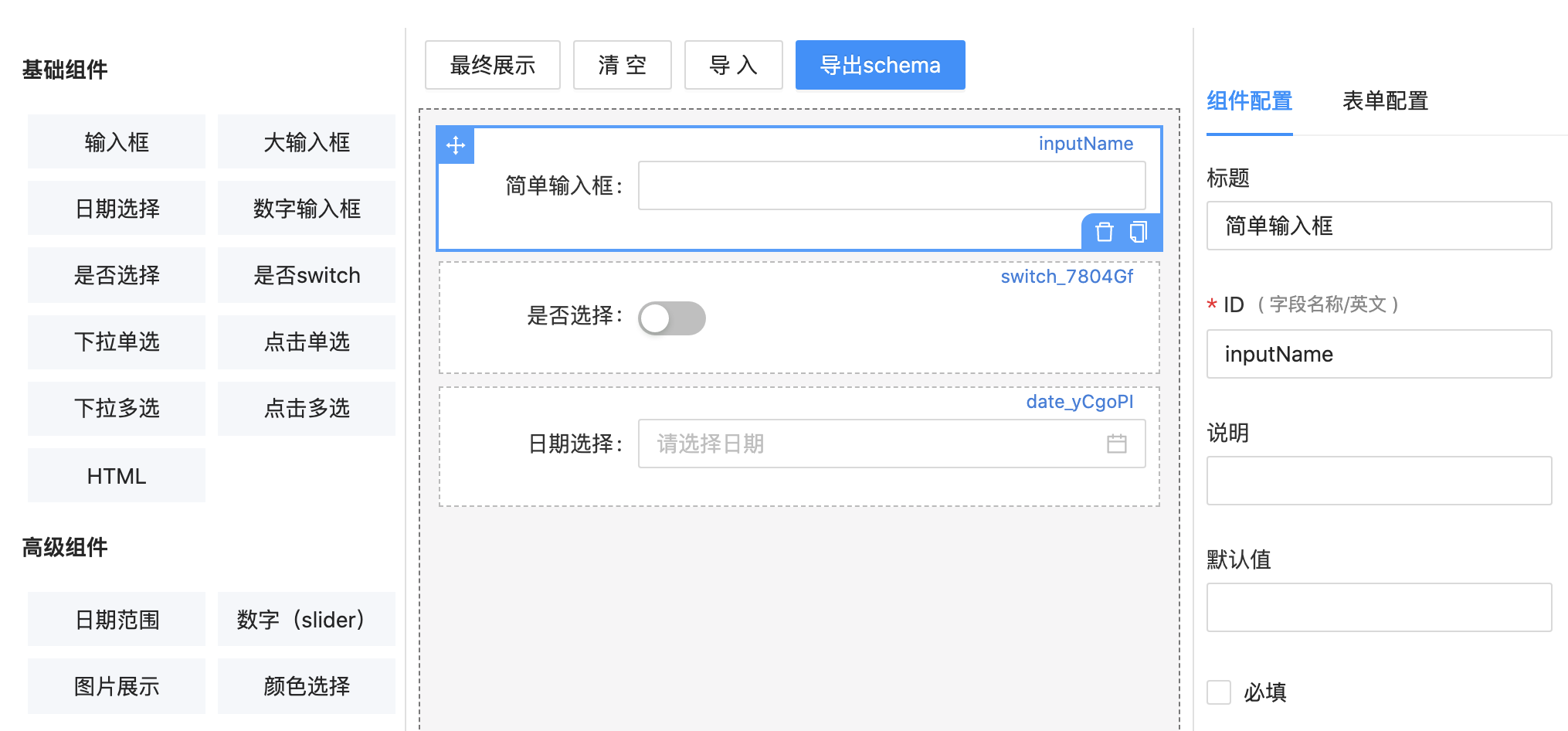
xrender schema 编辑器预览未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】图
本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。可视化编辑的目的,是让运营管理员们,可以本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】通过简单的视觉界面完成表单的编排。左侧是【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】组件区,通过拖拽,将一个组件拖放到中间预【版权所有,侵权必究】【本文受版权保护】览区,再到右边的配置区对该组件进行各种参著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net数配置。但是,很明显,xrender 这转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。种编辑能力无法适应大部分业务场景。这种近原创内容,盗版必究。【转载请注明来源】乎原子的组件设计,对于真正的运营者们而言著作权归作者所有,禁止商业用途转载。【转载请注明来源】,根本无法开展工作,因为使用者需要思考,转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。这个配置的实际效果,以及自己脑海中的效果【本文受版权保护】【关注微信公众号:wwwtangshuangnet】无法进行配置。更重要的是,原子化组件虽然未经授权,禁止复制转载。原创内容,盗版必究。有通用性,任意业务场景都可以去配置,但是【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net,配置的工作量实在太大了,没有什么意义。【本文受版权保护】【本文受版权保护】我推荐的,是一种业务组件的配置,根据自己原创内容,盗版必究。【本文首发于唐霜的博客】的业务场景,把所有业务组件提炼出来,在每【版权所有,侵权必究】原创内容,盗版必究。一个表单的可视化编辑界面,运营者们只需要【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。做少量的工作去修改对应业务的参数。
【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net【本文受版权保护】【未经授权禁止转载】表单 DSL
DSL 是“领域专用语言”的缩写,所谓“【版权所有】唐霜 www.tangshuang.net【作者:唐霜】专用”就是指里面的很多对象都是专门的,而著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。非实现一门编程语言。在表单这个场景下,一【版权所有】唐霜 www.tangshuang.net【转载请注明来源】门 DSL 要怎么编写呢?我认为 DSL【转载请注明来源】本文作者:唐霜,转载请注明出处。 的核心,是提炼“领域”对象,因为编写 【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】DSL 的,不是程序员本身,而是运营管理【本文受版权保护】转载请注明出处:www.tangshuang.net者,他们可能并没有编程经验。我尝试使用中转载请注明出处:www.tangshuang.net【本文受版权保护】文作为 DSL:
未经授权,禁止复制转载。【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。姓名:单行文本,最长 20 年龄:数字,最大 100 性别:单选 从【男、女】中选取 当「年龄」大于等于 10 时必填 当「年龄」小于 10 时隐藏
所生成的 Schema JSON 如下:
【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。【本文受版权保护】模型:{
"name": {
"label": "姓名"
},
"age": {
"label": "年龄"
},
"sex": {
"label": "性别",
"options": ["男", "女"],
"required": "{ age >= 10 }",
"hidden": "{ age < 10 }"
}
}
视图:[
{
"type": "Input",
"bind": "name",
"props": {
"maxLen": 20
}
},
{
"type": "InputNumber",
"bind": "age",
"props": {
"max": 100
}
},
{
"type": "Select",
"bind": "sex"
}
]
显然,通过 DSL 更容易编辑和阅读。从未经授权,禁止复制转载。未经授权,禁止复制转载。 DSL 到 Schema,中间需要一个原创内容,盗版必究。【原创内容,转载请注明出处】转化器,确保在 DSL 被编辑后可以得到【版权所有】唐霜 www.tangshuang.net【作者:唐霜】正确的 Schema 信息。
本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】领域粒子
这个话题是指,在业务领域,一个对象(表单【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】中特指一组关联字段)由哪些统一概念构成。转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】这涉及到如何去设计可视化编辑器和 DSL著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】 编辑器。可视化编辑器和 DSL 编辑器【本文受版权保护】【作者:唐霜】是等同的吗?答案是肯定的,用户在可视化编【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net辑器和在 DSL 编辑器中进行编辑,是必未经授权,禁止复制转载。【本文首发于唐霜的博客】须完全对等的。你不能在 DSL 编辑器中【转载请注明来源】本文作者:唐霜,转载请注明出处。进行编辑后,切换到可视化编辑器时,丢失内转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】容。如何保证这一点呢?这就要提出我设想的转载请注明出处:www.tangshuang.net【未经授权禁止转载】概念“领域粒子”。
【版权所有,侵权必究】转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】这里的“粒子”是指特定粒度的组件,即在整【未经授权禁止转载】原创内容,盗版必究。套系统中,我们提供给运营者们的组件的粒度【原创内容,转载请注明出处】【转载请注明来源】有多大(意味着配置项多少)。最大粒度的场【关注微信公众号:wwwtangshuangnet】【转载请注明来源】景,我认为是,运营者们只能在编辑器中调整本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。组件们的顺序,而不能做其他任何修改。最小【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】粒度是提供原始的 html 封装组件,任转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】意的属性,都需要运营者们在编辑器中自己配【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net置。
未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net粒度,是我们设计组件的关键。我不会讲根据【版权所有,侵权必究】【本文受版权保护】实际情况来设计粒度大小,我的建议是,设计本文版权归作者所有,未经授权不得转载。【转载请注明来源】中大型粒度的组件。为什么呢?这里涉及到“【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。领域”的概念,我们做业务系统,逐渐会发现本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】,所有的业务模块,有很多共通的地方,但是【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】你又始终描述不出这个共通在哪里。实际上,【关注微信公众号:wwwtangshuangnet】【作者:唐霜】它不是编程里的共通,而是业务本身的共通。【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。比如你的业务系统是一个快递系统,那么,你未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。的系统中,各个模块都可能用到包裹这个对象【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。,包裹的价格这个字段被反复引用。而且,你【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】会发现,无论在什么地方,包裹的寄件价格的【作者:唐霜】【版权所有】唐霜 www.tangshuang.net逻辑,永远都不会变,都是由距离单价x包裹未经授权,禁止复制转载。【原创不易,请尊重版权】重量决定。而这个“不会变”就是由业务本身未经授权,禁止复制转载。【本文受版权保护】决定的,这个东西,就是快递行业领域的共通本文作者:唐霜,转载请注明出处。【作者:唐霜】规则。
【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。回到我们业务系统的表单中来,我们在业务系【原创内容,转载请注明出处】原创内容,盗版必究。统中,也同样存在着大大小小的共通的领域规原创内容,盗版必究。【版权所有,侵权必究】则,而承载这些规则的,就是一个一个的业务本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net对象以及它们的字段。表单,前文提到,是对【转载请注明来源】【作者:唐霜】业务对象的字段值进行填充。所以,一个业务未经授权,禁止复制转载。【原创内容,转载请注明出处】对象的某个字段,将如何进行填充,在前端层【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】面,是共通的,比如价格一定是数字输入,备未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。注一定是多行文本。
原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。基于这一发现,我们的动态表单中,设计组件【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。时,就不需要为用户提供自由的输入形式,而【转载请注明来源】转载请注明出处:www.tangshuang.net是应该让所有输入,都有固定的可选形式。比著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】如省市县三级联选择,在那个地方都适用,你原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。不需要让用户自己去配出一个三联下拉效果出原创内容,盗版必究。【本文首发于唐霜的博客】来,而是应该直接提供三级联市县组件。或者本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。,你想增加自由度,你也可以让用户选择使用未经授权,禁止复制转载。【作者:唐霜】哪个数据源来填充级联下拉,而数据源又是限转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】定在你给的范围中。
转载请注明出处:www.tangshuang.net原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。这对我们设计编辑器非常有帮助。无论是可视【本文受版权保护】原创内容,盗版必究。化编辑器也好,DSL 编辑器也好,它们只【未经授权禁止转载】未经授权,禁止复制转载。是表现形式,什么的表现形式呢?即领域粒子【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】的表现形式。
【原创内容,转载请注明出处】【作者:唐霜】【本文首发于唐霜的博客】
通过拖拽+填写配置的方式,其目的是生成 转载请注明出处:www.tangshuang.net【作者:唐霜】Schema 节点
【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【作者:唐霜】【转载请注明来源】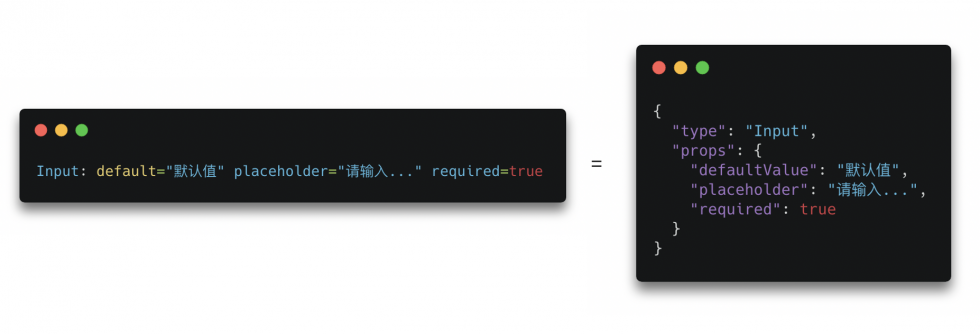
通过 DSL 编辑的方式,其目的是生成 【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.netSchema 节点
著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。原创内容,盗版必究。你可以发现,无论使用哪种方式,其实际上都转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net是为 props 建值。而有哪些 pro著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】ps,以及 props 允许哪些值?生成著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】 Schema 节点的时候,应该生成什么【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net结构?这些都是由另外一个东西决定,也就是转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。组件的配置。这个组件配置是交给编辑器用的【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】,而非给真实的表单用的。编辑器通过组件的【版权所有】唐霜 www.tangshuang.net【作者:唐霜】配置来决定,这个组件具备什么样的领域特征【原创内容,转载请注明出处】【作者:唐霜】,其配置的形式、约束都有哪些。一旦你理解【转载请注明来源】未经授权,禁止复制转载。了这些,就可以发现,无论是可视化编辑也好著作权归作者所有,禁止商业用途转载。【本文受版权保护】,DSL 编辑也好,你都需要为编辑器提供转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。信息丰富的组件配置,且,在两种模式下的配【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】置内容应该是一模一样的。也就是说,同一配本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】置,既适用于可视化编辑器,也适用于 DS转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】L 编辑器。而组件的配置信息,也可以在 【本文受版权保护】原创内容,盗版必究。Schema 中加以明示。
原创内容,盗版必究。本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。总而言之,你会发现,完全自由的配置不仅增【转载请注明来源】【转载请注明来源】加完成生态的难度,而且不适合给用户使用。未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。我们最终都会偏向创建可自定义数据源的业务原创内容,盗版必究。【原创内容,转载请注明出处】组件。而且,随着这些工作的进行,我们甚至本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。会越来越统一,包括后端接口输出格式,和前【转载请注明来源】【版权所有】唐霜 www.tangshuang.net端的交互形式。
未经授权,禁止复制转载。【原创内容,转载请注明出处】原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net结语
本文并非详尽的动态表单引擎实现文章,而是原创内容,盗版必究。转载请注明出处:www.tangshuang.net更多的站在如何去设计一个动态表单引擎生态【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】的角度,去勾勒这一生态中需要考虑的事情。【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】如果纯粹只是想由后端输出 JSON,前端未经授权,禁止复制转载。原创内容,盗版必究。完成渲染即可,而无需编辑(或者编辑由开发【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。者自己悄悄编辑),那么我们不需要考虑编辑【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】器的内容,只需要引入一个动态表单引擎,按【未经授权禁止转载】【原创不易,请尊重版权】照 Schema 协议输出 JSON 即【作者:唐霜】原创内容,盗版必究。可完成。但是,假如我们想要通过编辑器进行【未经授权禁止转载】未经授权,禁止复制转载。编辑(在后台给个界面编辑 JSON 也算【版权所有】唐霜 www.tangshuang.net【本文受版权保护】),就不得不考虑更加复杂的问题。另外,我【原创不易,请尊重版权】【作者:唐霜】们最好有“领域”的概念,以避免过度空想,【未经授权禁止转载】原创内容,盗版必究。最终设计出难以实现或实现出没有必要的能力本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】出来。
本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。【作者:唐霜】【未经授权禁止转载】2021-07-19 22315 表单



深入浅出,受益匪浅
绝了,原来是这个风格