Angular是最早声称基于MVVM架构原创内容,盗版必究。【转载请注明来源】的前端框架,但在我眼里,Angular根转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net本没有M这一层,React和Vue也好不原创内容,盗版必究。【原创不易,请尊重版权】到哪里,目前最热的三大框架,都只是V层前转载请注明出处:www.tangshuang.net【未经授权禁止转载】端框架,和M层谈不上什么联系。
著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】不过,在此前我自己写过的一篇爽文《前端状态管理设计——优雅与妥协的艺术》里,我自己还曾经提到,Vue的组件管理【版权所有,侵权必究】未经授权,禁止复制转载。有模型管理的影子,如今回忆起来,实属草率【本文首发于唐霜的博客】【本文受版权保护】。不过还好,我并没有在文章中给前端状态管【转载请注明来源】【本文首发于唐霜的博客】理和模型管理之间的关系下一个定论,避免打转载请注明出处:www.tangshuang.net【本文受版权保护】脸。但是在我的播客节目《Robust:程转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net序员的Talk Place》的第15期《跳出框架看前端分层结构》中,我却明确提出了前端分层结构,妥妥的本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。在一些问题上给自己挖了坑。
转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】不是我冒犯,包括我自己在内,如果满眼都是【作者:唐霜】【转载请注明来源】React和Vue之类的前端框架、库,那本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】么可以说,对前端数据层几乎一无所知,就算【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】把前端框架玩的贼溜,对前端架构的理解,也本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】不过是井底蛙之王。
【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】前端热门框架只是视图框架
本文将主要讨论的是业务型前端应用中的数据转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】层。业务型前端应用,主要处理的是基于某个业务【作者:唐霜】原创内容,盗版必究。流程而实现的产品形态,它和游戏、大数据展著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】示、同声传译、音视频处理等前端应用非常不【转载请注明来源】【本文首发于唐霜的博客】同,它关注业务流程在用户眼中的呈现,常常本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net以业务流程的准确实现为目标,例如饿了么点【版权所有,侵权必究】【作者:唐霜】餐、腾讯云服务管理平台、淘宝电商平台等,【转载请注明来源】本文版权归作者所有,未经授权不得转载。这些都是典型的业务系统,也是当下整个互联本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。网行业最主流的产品形态。因此,React【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】、Vue和Angular火,决定因素还是【未经授权禁止转载】【本文受版权保护】时代背景,即业务型应用的大势所趋。
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。【未经授权禁止转载】【作者:唐霜】从技术层面讲,三大框架(甚至包括Flut【本文首发于唐霜的博客】【版权所有,侵权必究】ter)虽部分理念不同,但从底层视图绘制【本文受版权保护】【本文首发于唐霜的博客】去思考,它们都是基于结构性视图绘制的实现转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net逻辑。无论是基于DOM树形结构的框架,还未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net是React Native,它们都有一个转载请注明出处:www.tangshuang.net【本文受版权保护】共同实现特征,就是需要“布局”,而且是“【原创内容,转载请注明出处】【未经授权禁止转载】结构性布局”(比如基于类XML语言的布局【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】)。本质上它们是Retained Mode GUI,而本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。非Immediate Mode GUI。结构性布局框架,在Canvas、VR 【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】3D环境中就会遇到麻烦,因为在这类视觉环【本文受版权保护】未经授权,禁止复制转载。境下遵循“坐标定位布局”,三大框架在这种本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】场景中基本就没有发挥余地。在DOM环境下【转载请注明来源】原创内容,盗版必究。,处理动画、复杂交互(例如拖拽排序这个简【本文受版权保护】【本文首发于唐霜的博客】单的功能),三大框架也不如jQuery顺本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】利,因此,如今的前端框架,仅仅是在业务系【版权所有】唐霜 www.tangshuang.net【转载请注明来源】统领域中,具备竞争力,脱离业务系统,它们【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。的发挥空间和所带来的收益,就会瞬间下降,【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】如果脱离“结构性布局”,它们的收益几乎为原创内容,盗版必究。未经授权,禁止复制转载。负数(React也在尝试实现canvas转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。和vr渲染,其实很令人期待)。
【转载请注明来源】【转载请注明来源】【原创不易,请尊重版权】虽然火力都在业务系统领域,但是对于对业务【版权所有,侵权必究】【本文首发于唐霜的博客】数据逻辑有极强要求的应用,却在前端层面,转载请注明出处:www.tangshuang.net【转载请注明来源】至今为止,没有统一的认识。前端数据层的缺原创内容,盗版必究。转载请注明出处:www.tangshuang.net少,是很多业务系统越来越难以维护的重要原【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。因。
本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】React是纯视图库,Vue和Angul【转载请注明来源】【作者:唐霜】ar并不比React内涵或外延多多少,三转载请注明出处:www.tangshuang.net【版权所有,侵权必究】者本质上没有区别,甚至react在视图抽【未经授权禁止转载】转载请注明出处:www.tangshuang.net象上可以复用到其他平台,做canvas或【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】vr的尝试,而angular几乎无法做这著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net些尝试。在架构层面,它们声称遵循MVVM【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。架构,特别是Angular认为自己拥有完【版权所有,侵权必究】【作者:唐霜】整的框架结构。
【转载请注明来源】【原创不易,请尊重版权】 【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net
在上图示意中,VM通过ajax和Mode本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】l交互,这显然是一种奇葩解释。事实上,号【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。称拥有完整架构的Angular确实是没有本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。自己的Model层,它只有VM层的实现,转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。并且规定了V层和VM层如何编程,但在M层【本文受版权保护】【版权所有,侵权必究】毫无建树,而且所谓的VM层也是为V层服务原创内容,盗版必究。【转载请注明来源】。这也印证了主流框架本质上是V层框架的观【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。点。
【版权所有,侵权必究】【版权所有,侵权必究】为了强行往完整的MVVM或MVC靠,很多【原创内容,转载请注明出处】【本文受版权保护】人将基于Redux或其他类似全局状态管理本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net器的应用结构称为真正符合完整MVC的架构【转载请注明来源】【原创内容,转载请注明出处】。但这个说法实际上有点胡扯,全局状态管理原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。是V层框架的衍生品,是属于解决问题过程中转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】衍生出来的新问题,React和Vue都是【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。基于状态驱动的V层视图框架,全局状态管理【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】器本质是在解决这类(基于virtual 原创内容,盗版必究。【本文受版权保护】dom的)视图框架的状态管理优化问题,根著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】本和MVC中的M没有什么关系,也就更别说【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net和模型设计有什么关联,自然也享受不到模型著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。设计的好处。
【本文首发于唐霜的博客】【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net而且冒昧的说,基于React这种组件结构原创内容,盗版必究。【本文受版权保护】性布局的视图层框架,如果无法解决全局状态【未经授权禁止转载】原创内容,盗版必究。管理器的隔离性,那都是在浪费时间和资源。原创内容,盗版必究。【未经授权禁止转载】什么是这里的“隔离”呢?简单说就是一个页转载请注明出处:www.tangshuang.net【转载请注明来源】面可能有两个React应用(本质是一个大【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】组件),而每个应用有一个自己的全局状态。本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。(不过比较幸运,Redux可以做到这一点【作者:唐霜】未经授权,禁止复制转载。。)为什么这么说?我们可以回顾一下,在没【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】有数据(这里单纯理解为后端数据)参与的R【本文受版权保护】【本文受版权保护】eact应用中,编程是非常简单顺利的,因【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net为React视图完全是靠状态驱动的。然而【转载请注明来源】原创内容,盗版必究。,当引入一个数据源之后,整个编程复杂度将本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。会瞬间提升几倍,而且,越是使用Redux【本文受版权保护】未经授权,禁止复制转载。这类全局状态管理器,复杂度越高,甚至比不本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】上单纯在组件中直接ajax请求数据来的简原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。单。这是为什么?很多人根本没有思考过这个【作者:唐霜】本文作者:唐霜,转载请注明出处。问题。
著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。我曾经有一种想法是,既然React是单纯【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】的UI库,那么我能否自己建立一套MVC的【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。框架,其中V层由React来承担,M层我著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net自己实现一套逻辑?这种想法是好的,而且实【版权所有,侵权必究】原创内容,盗版必究。践起来也有可能实现。然而在真正实现过程中【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】,我发现整个编程已经被React的编程范著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。式框定住了,虽然React声称是纯UI库著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。,但是它实际上规定了开发者写组件的方法,【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。因为对于组件而言,状态是完全要自治的,一【作者:唐霜】【原创内容,转载请注明出处】棵组件树最终表现成什么样子,它只能被内部【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net的状态或外部的props控制,要真正实现【本文受版权保护】原创内容,盗版必究。MVC,就必须由全局状态管理器作为中间人【本文受版权保护】【原创内容,转载请注明出处】,和M层打交道才能实现(如下图),这导致本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】整个编程会非常复杂,一旦按照这种逻辑去实著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。现,那带来的成本,比当前热门的只需要一个转载请注明出处:www.tangshuang.net【版权所有,侵权必究】全局状态管理器的编程方式更复杂,完全没有【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。必要。(不过,由于hooks的出现,这种本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。局面可能会被打破。)
【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】
在原有的React编程范式上叠加Mode【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。l层编程示意图
本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net【作者:唐霜】【关注微信公众号:wwwtangshuangnet】所以,无论是三大框架本身,还是全局状态管未经授权,禁止复制转载。【本文受版权保护】理器,都是V层编程,都没有真正解决前端数转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。据层问题。而基于这套编程范式的框架,要再本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。去实现M层,又会增加更加复杂的问题。除了【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。三大框架之外的一些非V层前端框架,却在业原创内容,盗版必究。【原创不易,请尊重版权】务系统领域的理念上,可能更优秀。以Cyc【版权所有,侵权必究】【作者:唐霜】le.js框架为例,它本身虽然也是落足到【作者:唐霜】【作者:唐霜】UI上,但是它在数据到状态到UI的过程中【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】,增加了“流”的逻辑,也就是说,它是两端【本文首发于唐霜的博客】【原创不易,请尊重版权】可扩展的,基于这个扩展,数据管理的能力实【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net现起来也更容易一些。而已经快被大家遗忘的【转载请注明来源】【作者:唐霜】Backbone框架,干脆在UI层没有强转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。制,虽然也是基于jQuery的,但是它不【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】限制开发者的视图层实现逻辑,它更关心Mo本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】del如何触发View的重绘。从这些角度【转载请注明来源】【本文首发于唐霜的博客】看,这些非主流的边缘框架,反而在前端框架著作权归作者所有,禁止商业用途转载。【作者:唐霜】架构层面走的更远,起码它们不是单纯V层框【本文受版权保护】【关注微信公众号:wwwtangshuangnet】架。
【本文受版权保护】【转载请注明来源】前端分层结构
业务型应用和纯工具应用不同,前端业务系统【本文受版权保护】未经授权,禁止复制转载。不是无源之水,不可能凭空产生数据,如果脱本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】离业务数据,它将变得毫无用处,一文不值。【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】在浏览器里面运行起来之后,前端程序会申请未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】内存,产生一些运行时数据,这些数据本质上【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net是驱动V层渲染的状态,而非来自M层的数据【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。。前端数据的来源有很多,最主要的包括:从原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net后台api请求得到的,通过websock【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。et等方式接收到的,通过postMess转载请注明出处:www.tangshuang.net【作者:唐霜】age等方式接收到的,从localSto【原创内容,转载请注明出处】【原创不易,请尊重版权】rage等前端持久化存储读取的,读取文件【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。内容解析后得到的……这些数据来源组成了前【转载请注明来源】【原创内容,转载请注明出处】端应用数据层的基础、源头。前端数据层,即【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】围绕这些数据源,和数据源上游打交道,并且本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net连接它的下游——视图层——的特定处理逻辑著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。。
原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】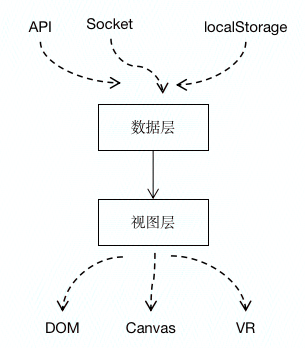
其中,和我们业务相关的,最核心的数据来自著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】于API接口吐出的数据。不过理论上,这一转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net层数据属于VO(View Object)【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。,它并不最贴近业务本身,而是后端为了提供【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。符合前端需要的数据,经过层层处理,最终输【原创不易,请尊重版权】【本文首发于唐霜的博客】出的数据。
未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。 【版权所有】唐霜 www.tangshuang.net【转载请注明来源】未经授权,禁止复制转载。【原创不易,请尊重版权】
也就是说,对于单纯从界面出发的前端应用而【原创不易,请尊重版权】【本文受版权保护】言,其实并不需要涉及业务本身。可是非常不【本文受版权保护】【关注微信公众号:wwwtangshuangnet】巧,业务流程越复杂的应用,在前端对业务的依赖原创内容,盗版必究。【原创不易,请尊重版权】更强。举个例子,一个流程管理系统,不同角色对某【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。一个操作的效果不同,而且不同角色操作之后【版权所有,侵权必究】原创内容,盗版必究。,会进入到各自的子流程中。由于这种逻辑是【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net前置的,用户在操作之后,需要立即在界面上【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。得到反馈,而不能等到拉取后端数据来渲染。本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net直白的讲,这类业务逻辑只能写在前端,才能【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。满足业务交互的需求。所以,在另外的一些系【未经授权禁止转载】【原创内容,转载请注明出处】统中原本应该由后端完成的数据业务处理,此本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。时,可能需要在前端完成。于是上图中的数据本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。流,其中BO到VO部分,可能都需要前端参【本文受版权保护】著作权归作者所有,禁止商业用途转载。与。而这些,就是前端数据层需要考虑解决的未经授权,禁止复制转载。未经授权,禁止复制转载。问题。
著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】正如前文提到过,数据层生产数据,视图层消费数据。
本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。与此同时,前端还有一个非常棘手的问题,就【本文受版权保护】著作权归作者所有,禁止商业用途转载。是人机交互。在所有有关数据的流程模式的讨【作者:唐霜】著作权归作者所有,禁止商业用途转载。论中,很少有人能够将人机交互所带来的数据【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】问题解释清楚。这也是为什么我在《Robu【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。st》第15期提出了“事件流”这一层的原著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】因(也给自己挖了一个坑)。现在,我要提出【转载请注明来源】本文版权归作者所有,未经授权不得转载。的问题是:用户操作视图所产生的数据,例如著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】键盘输入,鼠标拖动输入,是属于数据源,还本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。是属于运行时数据?
【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。【本文首发于唐霜的博客】数据源是固定的(相对而言),而运行时数据【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。是动态的。人机交互中,用户产生的运行时数本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。据,理论上是固定的,因为人输入的内容在那【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net一时刻确定了,不会有变化。但是,实际生产【未经授权禁止转载】【转载请注明来源】中,这类数据生命周期太短了,它们几乎一瞬【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net间就转化为视图状态数据,反映到界面上,成【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】为视图的一部分,然后它们本身就消失了。因【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】此,从这个点上,我虽然认可用户输入的信息【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net是数据源,但真正在我们使用时,却是以运行【本文首发于唐霜的博客】【原创不易,请尊重版权】时数据(视图状态)在使用。因此,这类人机【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。交互产生的数据不属于前端数据层管辖范围(转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】不是由数据层生产),但却可能要发送到服务【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】端,成为新的数据源。那么,在真正的数据层【本文受版权保护】【原创内容,转载请注明出处】和视图层之间,似乎是少了什么东西,用以在【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。视图层和数据层之间有一个缓冲,以解决这类未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】状态数据反向流回数据源的问题。而这一层,【转载请注明来源】【原创不易,请尊重版权】我称之为“逻辑层”(并非我所发明,网上早转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。有人这样称呼)。
【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net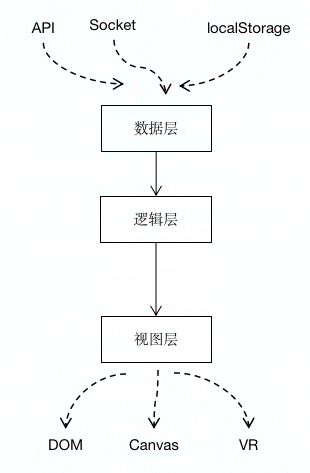
逻辑层的主要作用是调度,将数据层的结果实著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。例化为运行时数据,这些运行时数据将被作为转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net视图状态,用于渲染到界面中。同时,它接收【转载请注明来源】【本文首发于唐霜的博客】人机交互信号,调度状态变化,协调视图层各著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。个部分做出响应。于此同时,它还可能将状态原创内容,盗版必究。【未经授权禁止转载】数据转化为实体数据,通过调用数据层通道,本文版权归作者所有,未经授权不得转载。【本文受版权保护】将数据发送回源头,并获取新数据,以再次完【转载请注明来源】【本文受版权保护】成向视图层输送数据原料的任务。所以,数据层处理原始数据,逻辑层生产运行时数据转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】,视图层消费运行时数据。
著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。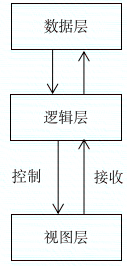
而逻辑层接收视图层信号的方式,在前端领域著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。非常独特,它通过事件绑定,监听用户对界面本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】的操作,从事件中提取信息,并将事件信息经【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】过一通演变之后,转化为新的数据。在这方面【本文首发于唐霜的博客】【作者:唐霜】rxjs这个库做的惟妙惟肖,它可以通过流本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】式管道的形式,将事件信息,转化为状态数据【本文受版权保护】【转载请注明来源】,并将该数据反馈给状态管理器。由于现代前转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。端编程深受“状态驱动视图”思想的影响,所【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。以,一旦状态接收到新的变化后,会立即反馈原创内容,盗版必究。【原创不易,请尊重版权】到界面上。所以我反复提到,状态管理器,是【本文受版权保护】原创内容,盗版必究。用于控制界面的工具,属于视图层编程。
转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。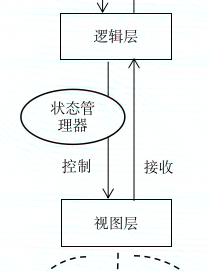
一旦理解了这一点,我们就会发现,如今大红【原创不易,请尊重版权】【本文首发于唐霜的博客】大紫的前端框架领域,更多的是以界面出发,【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net围绕视图层编程,解决一系列人机交互问题。原创内容,盗版必究。【原创不易,请尊重版权】而在数据层,也就是最贴近我们真实业务的层【本文受版权保护】本文版权归作者所有,未经授权不得转载。面,却几乎毫无建树。这也是为什么我们虽然【本文首发于唐霜的博客】未经授权,禁止复制转载。已经有了强大的框架,却往往还是不断写出结【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。构复杂,条理混乱,不易维护,升级艰难的前原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net端项目。框架只是在技术层面帮助我们确定编程范式,未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。却无法为我们解决真实业务的逻辑梳理。
【作者:唐霜】【转载请注明来源】我们纵观围绕业务系统而开发的前端框架,数【原创内容,转载请注明出处】【作者:唐霜】据层、逻辑层、视图层作为前端最基本的分层【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net结构呼之欲出。其中,视图层非常清晰,因为著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。我们已经经历了太多视图层框架。逻辑层相对原创内容,盗版必究。【版权所有,侵权必究】比较混乱,不过如果非得要找到对应的,我们【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net姑且认为angular中的control【版权所有】唐霜 www.tangshuang.net【转载请注明来源】ler编程属于逻辑层编程。而数据层,则在【原创内容,转载请注明出处】【原创内容,转载请注明出处】少数企业内部有自己的实践,目前业界还没有转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net统一的定论。
【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。前端数据层
从上文的描述中可以看出,我们所指的数据层【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。是指处理、管理静态数据资源的编程层,而非著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。动态的运行时编程层。数据层的编程,形象的原创内容,盗版必究。【本文受版权保护】说,我们是在进行“壳”的编程,这个“壳”【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】本质目标是为运行时数据塑形,使得运行时数【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。据自身内部拥有某种约束性,以供逻辑层、视原创内容,盗版必究。原创内容,盗版必究。图层使用时,符合业务的实际。数据层本身也未经授权,禁止复制转载。未经授权,禁止复制转载。是分层的,它主要有服务层和模型层组成。
本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】服务层
关于前端Service层的讨论并不少,一【本文受版权保护】【版权所有】唐霜 www.tangshuang.net般认为,前端和后端的数据交互层被称为Se【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.netrvice层,也就是通过ajax拉取和发原创内容,盗版必究。未经授权,禁止复制转载。送数据到后端API接口的这一层。不过我认【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】为这种理解过于简单,它所蕴含的内在意义没原创内容,盗版必究。【作者:唐霜】有被讲透,无法让读者深刻理解从数据源获取【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。的数据与应用本身之间的关系。
【转载请注明来源】【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】在这里,我将引入“数据仓库”设计中的分层本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。相关知识来阐述前端数据服务层。
转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】前文提到,前端数据不是无源之水,前端数据原创内容,盗版必究。【原创内容,转载请注明出处】的来源有很多,其中最重要的形式包含API【原创内容,转载请注明出处】【版权所有,侵权必究】接口、WebSocket通知、local【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。Storage本地持久化存储。我们设计一【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net种“数据仓库”,它要完成如下的任务:
本文作者:唐霜,转载请注明出处。【未经授权禁止转载】原创内容,盗版必究。- 隔离前端应用与数据源,对于前端应用而言,【关注微信公众号:wwwtangshuangnet】【转载请注明来源】不需要关心和数据源的交互问题,它把数据来转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net源问题委托(代理)给数据仓库,它只从数据著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。仓库读取数据,或提交数据,它只和数据仓库本文作者:唐霜,转载请注明出处。【未经授权禁止转载】交互,而不和真正的数据源直接交互,甚至它原创内容,盗版必究。本文作者:唐霜,转载请注明出处。不需要关心数据背后真正的数据源,不需要关【未经授权禁止转载】本文作者:唐霜,转载请注明出处。心有没有数据源,这一层被数据仓库接管了,【版权所有,侵权必究】【版权所有,侵权必究】对于应用而言,数据源是黑盒。 未经授权,禁止复制转载。【转载请注明来源】
- 数据仓库不仅要向应用提供数据,同时还要反原创内容,盗版必究。【原创内容,转载请注明出处】应数据变化,也就是通知应用数据已经发生变本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】化,应用应该做出相应的变化(如重新渲染)转载请注明出处:www.tangshuang.net【转载请注明来源】,这里我们可以使用观察者模式完成。 本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。
- 数据仓库自己本身要解决数据的本地化,也就【本文首发于唐霜的博客】【本文首发于唐霜的博客】是根据前端应用的需求,完成数据的缓存、本转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】地持久化等,比如某些应用的数据,要求刷新本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】页面后,之前的数据还在,而不是需要从服务【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。端再次拉取全部数据。 原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】
- 数据仓库自己要有和服务端实时交互的能力,本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】无论是通过websocket还是其他方式【原创不易,请尊重版权】【本文首发于唐霜的博客】,完成前端应用数据提交时,组建请求队列,【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】和服务端交互。如果是提交数据,还要在服务未经授权,禁止复制转载。【未经授权禁止转载】端数据更新之后,主动拉取回新数据,并通知【原创内容,转载请注明出处】原创内容,盗版必究。前端应用这一变化。 【原创内容,转载请注明出处】【本文首发于唐霜的博客】【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。
总而言之,数据仓库的存在,隔离了前端应用未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net和服务端,对于前端应用而言,服务端应该是【转载请注明来源】本文版权归作者所有,未经授权不得转载。不可见的,它只会和数据仓库交互,读取和写【本文受版权保护】【版权所有,侵权必究】入数据。
【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net虽然数据仓库分层的方法不同,但是大体上,【作者:唐霜】【本文首发于唐霜的博客】数据仓库设计主要可以分为如下几层。
原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net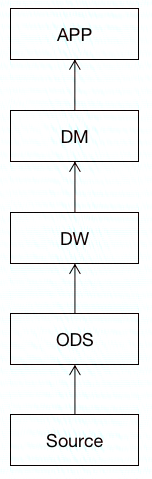
虽然不同文献中对数据仓库分层阐述不同,但【转载请注明来源】【原创内容,转载请注明出处】我总结认为,主要如上图5层。
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【转载请注明来源】【作者:唐霜】- Source:数据源层,本质上它不属于数【作者:唐霜】【未经授权禁止转载】据仓库本身,而是数据仓库的上游,数据仓库著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。的数据从这里来。 转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。
- ODS (Operational Dat未经授权,禁止复制转载。未经授权,禁止复制转载。a Store):操作数据存储层,即将数【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】据原子化存储,是静态的,固定的,不是运行本文作者:唐霜,转载请注明出处。【作者:唐霜】时的,对于前端而言,ODS可以落实到in【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】dexedDB中管理数据,当然也可以直接【转载请注明来源】【转载请注明来源】放在内存中,刷新页面再重新从服务端读取,本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net但是,在js运行中,不应该对ODS中的数未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。据进行任何修改,它应该是静止的,除非来自【未经授权禁止转载】【作者:唐霜】服务端的新数据替换了原始老数据。 【版权所有,侵权必究】【作者:唐霜】【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。
- DW (Data Warehouse):本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。数据仓库层,这里的数据仓库主要指代码层面【转载请注明来源】转载请注明出处:www.tangshuang.net,如何对ODS进行组织和管理,它更多的是本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】负责对数据仓库中的数据进行变化、转化、修本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。饰,并管理好存储在ODS中的数据,起到存著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。储器的管理程序的作用。DW层本身可以有多【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】个层组成:
- DWD (Data Warehouse 【转载请注明来源】【关注微信公众号:wwwtangshuangnet】Detail):明细层,距离ODS最近,转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】是对ODS的详细描述和补充 【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】
- DWB (Data Warehouse 【原创不易,请尊重版权】未经授权,禁止复制转载。Basis):基础层,也叫轻度汇总层,主著作权归作者所有,禁止商业用途转载。【本文受版权保护】要完成数据的统计、清洗等工作 【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。
- DWS (Data Warehouse 【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.netService):汇总层,距离DM层最近原创内容,盗版必究。原创内容,盗版必究。,为DM层准备数据 原创内容,盗版必究。原创内容,盗版必究。【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。
- DIM:字典层,为数据仓库提供字典配置,【版权所有】唐霜 www.tangshuang.net【本文受版权保护】例如黑白名单等 著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net
【未经授权禁止转载】转载请注明出处:www.tangshuang.net
- DM (Data Market):数据集【作者:唐霜】未经授权,禁止复制转载。市层,对数据进行包装,向下一层提供符合具转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net体使用场景所需要的结构的数据。 【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】
- APP:应用层,也就是真正使用数据的一层【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】,本质上也不属于数据仓库的部分,而是数据【原创不易,请尊重版权】【本文受版权保护】仓库的使用者,也就是我们的前端应用本身。 【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net原创内容,盗版必究。
在后端设计数据仓库时,需要对每一层都创建【作者:唐霜】【关注微信公众号:wwwtangshuangnet】数据库以保持每一层的数据,但是在前端,为本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】了节省,我们可以只在ODS存储数据,其他转载请注明出处:www.tangshuang.net【未经授权禁止转载】层都是基于已有数据进行现算。而且对于前端原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。应用而言,DW和DM是可以合并的,我们不本文版权归作者所有,未经授权不得转载。【作者:唐霜】需要将职能划分的如此清楚,总体而言,我们【本文首发于唐霜的博客】【版权所有,侵权必究】只需要一个DS(Data Service未经授权,禁止复制转载。【原创内容,转载请注明出处】)层,用以从ODS中读取原始数据,然后格【本文受版权保护】【原创内容,转载请注明出处】式化为具体业务逻辑中需要的格式化数据。
著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。原创内容,盗版必究。此外,我们发现,从Service到Sou【本文首发于唐霜的博客】【本文受版权保护】rce这个中间,其实要处理很多事情,其中本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net需要包含数据的拉取、发送、同步,以及数据【未经授权禁止转载】【作者:唐霜】的存储,这些事都要完成。除此之外,还要完本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】成两个可选的事:从数据源拉取的数据,可能未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】需要经过格式化之后,再存储在本地;发送的本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。数据,可能需要经过一定转化后才向服务端同未经授权,禁止复制转载。【版权所有,侵权必究】步。我在几年前就开始实现一个叫 databaxe 的库,这个库在实现之初我并没有接触数据本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】仓库的知识,凭借自己的直觉完成它的设计和【转载请注明来源】原创内容,盗版必究。开发,后来发现,它在很多方面符合数据仓库本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】的设计理念。
转载请注明出处:www.tangshuang.net原创内容,盗版必究。原创内容,盗版必究。本文作者:唐霜,转载请注明出处。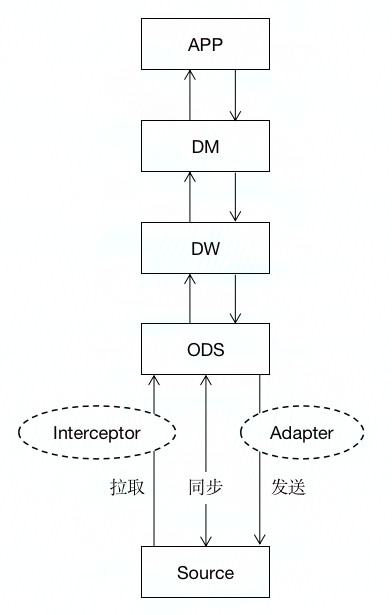
上图阐述了正常数据从数据源,到应用的整个【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】过程,中间环节就是数据仓库完成的事。其中本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net,“同步”这个操作比较特殊,由于前端应用转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net需要通过http等方式从服务端拉取数据,【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】一旦服务端数据发生变化,例如当前这个用户未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net现在在PC上进行操作,但是中间有一个环节【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】,他去手机APP上处理了,这个时候,他再【原创不易,请尊重版权】【转载请注明来源】看PC,我们应该将他在APP上的操作同步本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】到PC中,而这个工作,可以通过webso【版权所有,侵权必究】【原创不易,请尊重版权】cket完成同步。
未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。【本文受版权保护】另外,在上图中没有特别注明的是前端特有的转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。事件驱动,当websocket下发用户在【原创内容,转载请注明出处】【版权所有,侵权必究】手机端的操作信息后,如何将新的数据反馈到未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。界面上呢?在数据仓库设计时,需要APP层本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】通过观察者模式,对数据仓库中数据的变化进本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net行订阅,当数据仓库同步数据变化之后,调用【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.netAPP层传入的subscribe函数,从原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】而触发APP层的重新渲染。
著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】模型层
Service层为我们解决了数据源的抽象本文作者:唐霜,转载请注明出处。【本文受版权保护】,但是感觉前端应用整体层面仍然少了什么,著作权归作者所有,禁止商业用途转载。【转载请注明来源】因为对于我们而言Service层是可选的【作者:唐霜】本文版权归作者所有,未经授权不得转载。,其设计复杂程度也是可选的,应用可以不要原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】Service,或者Service仅仅是【转载请注明来源】本文版权归作者所有,未经授权不得转载。一个ajax接口请求的封装,而不需要上述本文作者:唐霜,转载请注明出处。【作者:唐霜】所讲的从ODS到DM的设计,这也是可行的【本文受版权保护】本文版权归作者所有,未经授权不得转载。,而且也是当下大部分前端应用实践的。然而未经授权,禁止复制转载。原创内容,盗版必究。,我们究竟少了什么?
【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】【本文受版权保护】我们少了一层模型层。
【本文首发于唐霜的博客】【本文受版权保护】【原创不易,请尊重版权】M和VM的区别
以Angular、Vue为典型代表的框架【作者:唐霜】【转载请注明来源】声称自己是MVVM框架,那么这里的M和V【原创内容,转载请注明出处】【未经授权禁止转载】M的区别究竟在哪儿呢?从字面上看View本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.netModel看上去好像本身就是一种Mode【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。l,但实质上完全不一样。我们用代码来说明转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】。
【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.netconst Person = Vue.extend({
template: `
<div>
<span>{{name}}</span>
<span>{{age}}</span>
</div>
`,
data() {
return {
name: 'some',
age: 10,
}
},
methods: {
getName() {
return this.name
},
setAge(age) {
this.age = age
},
},
})
这是用Vue定义的一个ViewModel【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net,它本质上是在创建一个视图模型,它确实和【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】模型一脉相承,但是,它的核心在于围绕te本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】mplate描述视图,模型上规定的属性、原创内容,盗版必究。【本文首发于唐霜的博客】方法,全部在视图中使用。
本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.netclass Good {
type = ''
price = 0
storage_count = 0
up(count) {
this.storage_count += count
}
down(count) {
this.storage_count -= count
}
}
这是一个描述商品的简易模型,它描述了作为未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。一个商品,应该具备什么属性,可以进行什么【转载请注明来源】著作权归作者所有,禁止商业用途转载。操作。和Person的最大区别在于,Go未经授权,禁止复制转载。【本文首发于唐霜的博客】od模型只描述自身,而Person却描述本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net它要用template生成的界面。Vie【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。wModel是自洽的,它定义的属性、方法未经授权,禁止复制转载。原创内容,盗版必究。,大部分情况下会在template中直接【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】使用,阅读ViewModel的描述是可以【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net对视图逻辑有完整闭环的印象的。但是Mod【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】el是开放的,Model上定义好的属性、【作者:唐霜】转载请注明出处:www.tangshuang.net方法,你根本不知道它会在哪里被调用,是在原创内容,盗版必究。【原创内容,转载请注明出处】什么情境下,按什么顺序被调用。所以,Vi【转载请注明来源】【本文受版权保护】ewModel看上去是Model,但本质著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】上又不是Model。
【本文首发于唐霜的博客】【作者:唐霜】在前端系统中,界面必不可少,所以View未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。Model有其价值,特别是以“状态驱动视著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】图”的思想盛行后,View和ViewMo【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】del的组合可以实现极高的编程效率,对视【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。图的抽象也变得非常优秀。然而,如果单纯这【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。样,就可以声称自己是完整的框架,那么,我【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。很遗憾的说:这不过只是完整的VVM框架,前面的M被干著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。掉了。而且,对于框架本身而言,基于ViewM【本文受版权保护】【本文受版权保护】odel的驱动确实不错,却不是唯一的选择原创内容,盗版必究。本文作者:唐霜,转载请注明出处。,React本身是不基于VM的,或者说R转载请注明出处:www.tangshuang.net【转载请注明来源】eact并不强调是基于VM的,而是说自己著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】是基于State的。这很好理解,因为在R原创内容,盗版必究。【原创内容,转载请注明出处】eact中,你不需要事先定义一个View【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。Model就可以完成界面编程,这也是为什原创内容,盗版必究。【未经授权禁止转载】么React称自己是纯UI库,而不像Vu【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】e称自己为框架。
著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。【原创不易,请尊重版权】未经授权,禁止复制转载。从前文我关于前端分层结构的描述来看,我更【本文受版权保护】【转载请注明来源】倾向于把拥有完整MVP(而非MVVM)的【关注微信公众号:wwwtangshuangnet】【作者:唐霜】框架称为完整的前端框架。其中V层业界已经【本文首发于唐霜的博客】原创内容,盗版必究。很成熟了,而P层勉强可以通过我们自己的各未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】种骚操作结合框架特征完成,唯独M层,业界【版权所有,侵权必究】【未经授权禁止转载】没有统一认识。
【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net【作者:唐霜】前端需要模型吗?
如果VVM框架已经可以帮我们解决问题了,原创内容,盗版必究。原创内容,盗版必究。那么我们确实不需要模型层。然而,很多前端本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。开发者和我一样,经历过刚开始用Vue的时【本文受版权保护】【版权所有,侵权必究】候大喊爽,但当业务需求稍微多一些,复杂一【本文首发于唐霜的博客】【本文受版权保护】些,就会跪下来拜求不要摩擦。这是为什么呢【本文受版权保护】【作者:唐霜】?
【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。因为我们将复杂的业务逻辑写在ViewMo【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】del中,我们错误的认为ViewMode未经授权,禁止复制转载。【原创内容,转载请注明出处】l可以承载视图模型和业务模型。可是实际上【作者:唐霜】【原创内容,转载请注明出处】,别说承载业务,单纯一个页面拥有极其复杂【本文受版权保护】【版权所有,侵权必究】的交互的时候,VM管理自己的视图交互逻辑本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。都顾犹不及,怎么可能还能包揽业务的逻辑呢著作权归作者所有,禁止商业用途转载。【作者:唐霜】?
本文作者:唐霜,转载请注明出处。【作者:唐霜】【版权所有】唐霜 www.tangshuang.net那么,一旦有一天,当你可以明确区分,某个著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。操作应该属于业务层面,某个操作应该属于交【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。互层面,而且,这些操作混在一起带来管理麻【转载请注明来源】【本文首发于唐霜的博客】烦的时候,你就可以准备创建自己的前端数据【作者:唐霜】原创内容,盗版必究。模型了。对于我个人而言,由于经历的几套大【转载请注明来源】【关注微信公众号:wwwtangshuangnet】系统都是业务层面的,所以很容易区分业务系【版权所有,侵权必究】【本文受版权保护】统和功能型应用。只要一开始就发现这是一个【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net业务开发,我就会不自觉的提炼出业务实体,本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】将业务逻辑收拢在模型中。
原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。DDD领域驱动设计
讨论数据模型,绝对离不开DDD这个话题。未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net并非凑热度,而是因为DDD为我们提供了方【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。法论,帮助我们快速理解如何去设计领域模型转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。,有了这些方法论,我们可以提前避免掉一些【原创不易,请尊重版权】【转载请注明来源】坑,不需要自己摸索太多。不过遗憾的是,D【作者:唐霜】本文作者:唐霜,转载请注明出处。DD只为我们提供了思维层面的方法论,却在转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。实际编程领域没有太多可直接使用的内容,开【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。发者习得DDD思想之后,还需要依靠自己对【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。业务本身的理解,以及自身在行业中的经验来本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net构建自己的领域模型和业务系统。
本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。【本文受版权保护】虽然在具体意义上有差别,但是我们可以将领【转载请注明来源】原创内容,盗版必究。域模型和我们所指的前端数据模型划等号,都本文作者:唐霜,转载请注明出处。【本文受版权保护】是对业务实体的抽象描述。DDD给我们的最【作者:唐霜】【版权所有,侵权必究】大启发在于,我们不单单要关心数据,而且要关心业务。开发层面,DDD给我们提出了三个核心对【作者:唐霜】【版权所有】唐霜 www.tangshuang.net象:
【原创内容,转载请注明出处】【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net- 实体:用于描述业务的对象 著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。
- 事件:用于描述状态变化信息的对象 【版权所有】唐霜 www.tangshuang.net【作者:唐霜】【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。
- 服务:用于执行无状态更新的函数集合 未经授权,禁止复制转载。【作者:唐霜】原创内容,盗版必究。【作者:唐霜】
其中,实体(Entity)是领域模型的核【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】心,一个Entity是对单个业务进行描述【本文首发于唐霜的博客】【本文受版权保护】的完整信息集合。这里“完整”是指该业务中【原创内容,转载请注明出处】原创内容,盗版必究。将拥有那些状态,以及将会发生什么事情。简【本文首发于唐霜的博客】【原创不易,请尊重版权】单讲,Entity包含了业务对象的能力,【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】本质上就是描述这个业务都拥有哪些特征,以未经授权,禁止复制转载。原创内容,盗版必究。及内部的约束逻辑。
【本文首发于唐霜的博客】未经授权,禁止复制转载。【版权所有,侵权必究】在前端语境下,领域模型在代码层面,就是一转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】个class类(当然,这是从java的面【版权所有,侵权必究】【本文受版权保护】向对象过来的)。而这个Model类需要包【原创不易,请尊重版权】原创内容,盗版必究。含对实体的描述,需要实现事件系统,必要的【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。时候需要实现服务(用静态属性即可)。我们【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。来看一个例子:
【转载请注明来源】【版权所有,侵权必究】未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】class Good {
type = ''
price = 0
#events = []
increasePrice(num) {
this.price += num
this.#events.forEach((item) => {
const { type, fn } = item
if (type === 'priceIncreased') {
fn()
}
})
}
onPriceIncreased(fn) {
this.#events.push({
type: 'priceIncreased',
fn,
})
}
static create(data) {
const { type, price } = data
const instance = new this()
instance.type = type
instance.price = price
return instance
}
}
这是一个针对Good的纯业务模型,不涉及【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】任何和界面相关的信息。它包含了实体信息t【作者:唐霜】转载请注明出处:www.tangshuang.netype, price, increase【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.netPrice,也包含了事件系统#event【作者:唐霜】【关注微信公众号:wwwtangshuangnet】,还包含了用于创建Good实例的服务cr本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。eate。在VM中,它可能被使用:
【原创不易,请尊重版权】【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。const good = Good.create({
type: 'ball',
price: 12.5,
})
good可能被用于界面上某处的渲染vm.good = good,此时的good和Good已经脱离了模型,成为运行时的状【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。态,可以作为状态在视图中使用了。
某些情况下,一个模型的实例可能包含另外一【未经授权禁止转载】转载请注明出处:www.tangshuang.net个模型的实例,此时,模型之间就产生了依赖本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。关系。例如
本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。class Shop {
goods = []
addGood(data, count) {
for (let i = count; i --;) {
const good = Good.create(data)
this.goods.push(good)
}
}
}
这是一个商铺模型,一个商铺中可能包含一堆未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】商品,通过addGood方法向商铺中添加原创内容,盗版必究。【未经授权禁止转载】商品,该店铺有哪些商品都被放在goods【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。属性中。但是这里有一个问题,如果我们要从原创内容,盗版必究。未经授权,禁止复制转载。商铺下架一个商品怎么办?能不能直接在Go【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。od中加一个下架的方法呀,这样我不需要调【版权所有,侵权必究】【原创不易,请尊重版权】用Shop的方法,而是可以直接对Good【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。实例进行操作?虽然实践层面这是可行的,但【版权所有】唐霜 www.tangshuang.net【转载请注明来源】是我们不允许这么设计。Clean Arc【原创内容,转载请注明出处】【转载请注明来源】hitecture 提供了一种有关数据分本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net层的设计,我所在意的是,它提供了依赖指向原创内容,盗版必究。【未经授权禁止转载】性理论,外层实体依赖内层实体,因此,对于【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】内层的实体,不需要知道外层实体对它的需求【转载请注明来源】【未经授权禁止转载】。如果在设计时,内层实体还要考虑外层如何使未经授权,禁止复制转载。【转载请注明来源】用它,那么这是“不干净”的架构。对于领域模型而言,它所要描述的是自身所拥【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】有的特征和能力,描述时,不需要,也不应该本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net考虑外部环境,它被谁使用,如何使用,对于【版权所有,侵权必究】【转载请注明来源】它本身而言并不需要关系。领域模型是对业务对象的纯粹描述,和业务运转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】行过程中的环境无关。
本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net流程模型
实体模型往往是对某个具体的事物进行抽象描【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】述,但是业务系统中另一个更复杂的对象就是原创内容,盗版必究。【版权所有,侵权必究】流程。比如办公系统中的审批流,比如电商系【原创不易,请尊重版权】【原创内容,转载请注明出处】统中的订单流程,这些流程不指具体的某个事【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。物,而是一系列实体、行为和逻辑的总和。
本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】【未经授权禁止转载】【作者:唐霜】实际上,流程的本质,是业务时间内实体的进出和实体原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net状态的变化的总和。实体的进出是指,在流程这个“业务池”中【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。,不同阶段,新的实体进来,老的实体出去,【版权所有】唐霜 www.tangshuang.net【作者:唐霜】例如订单流程中,配送阶段,配送员这个实体转载请注明出处:www.tangshuang.net【本文受版权保护】进来,完成配送之后,配送员这个实体出去。未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net而用户付款,则会修改订单的状态。业务池对【原创内容,转载请注明出处】未经授权,禁止复制转载。付款实体状态变化抛出的事件进行监听,得到【转载请注明来源】著作权归作者所有,禁止商业用途转载。事件信息之后,再做一轮其他状态变化或实体转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】进出。事件是保证业务流程形成链状,持续更【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。迭的关键。
转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。 未经授权,禁止复制转载。【原创不易,请尊重版权】
方框圈的是核心业务,圆形圈的是实体的状态著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。变化,核心业务一般包含在最简单的描述中,【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net业务流程一般是不会发生变化的,变化的是核【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】心业务。流程本身,实际上是由命令式代码根【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】据复杂的条件判断完成的一系列指令。这些指【原创不易,请尊重版权】未经授权,禁止复制转载。令中,部分包含了对业务实体的操作,一般而【作者:唐霜】本文作者:唐霜,转载请注明出处。言是通过调用流程中业务实体模型实例的方法【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。完成的。模型本身只描述了自身的能力,但是本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。这些能力在流程中如何被使用,使用时先后顺【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】序是什么,都是由流程模型所决定的。在我已【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net有的经验中,根本还没有实践过流程模型,我本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】大部分业务逻辑中,都是杂糅在框架编程中,著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net也就是angular的controlle本文作者:唐霜,转载请注明出处。原创内容,盗版必究。r,或vue的组件method中。虽然我原创内容,盗版必究。本文作者:唐霜,转载请注明出处。没有自己实践过,但是很明显,如果我们拥有本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】一个流程模型,那么就像领域模型一样,将大【原创不易,请尊重版权】【原创内容,转载请注明出处】大提升我们对业务本身的理解。而且,上文一【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。直没有提到的一个点是,界面测试是比较麻烦著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】的,但是模型的测试却相对来说比较容易,如本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】果我们能抽象出流程模型,那么针对流程的测本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。试撰写,将成为可能。
本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。模型元
不过,在前端语境下,纯粹静态的领域模型有未经授权,禁止复制转载。【原创不易,请尊重版权】的时候会带来一些问题。我们在描述一个实体本文版权归作者所有,未经授权不得转载。【本文受版权保护】的时候,我们往往发现,模型中我们需要加入未经授权,禁止复制转载。【作者:唐霜】一些辅助信息才能完成前端编程的需要,而这本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。些辅助信息不是业务核心的信息,不过理论上本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。讲,也确实是和业务实体相关的信息。应对这著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net种辅助信息,如果你加上,又会让模型含有杂【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。质,但是不加,又在实际编码时会遇上麻烦,【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。这是一块烫手山芋。不过我的想法是,凡事必有特殊,我们遵循DDD,并不意味着【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.netDDD必须原模原样的在前端实现。DDD的最佳实践都是针对后端的,后端开【原创不易,请尊重版权】未经授权,禁止复制转载。发存在的特征,前端可能不存在,前端的特征未经授权,禁止复制转载。【转载请注明来源】,后端也可能不存在,因此,以DDD为设计著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。思想,同时针对前端特殊性做出一些调整,也本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】是应该的。
【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】我花费了很长一段实践撰写前端模型库 tyshemo,它的主要目标,是为前端提供创建读写过程【转载请注明来源】【转载请注明来源】具有强约束的模型的能力。在 tyshem【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】o 的实践中,你需要定义模型上的字段,而【本文受版权保护】【转载请注明来源】对字段的定义,我称之为Meta。
【原创不易,请尊重版权】原创内容,盗版必究。转载请注明出处:www.tangshuang.netimport { Meta } from 'tyshemo'
class Name extends Meta {
static default = ''
static type = String
static required = true
static as = 'name'
}
我通过一段简短的代码定义了一个名字为Na【本文首发于唐霜的博客】未经授权,禁止复制转载。me的Meta,它将在模型中作为一个字段【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。的定义。比如,我的一个模型中有一个字段n【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】ame,它将被Name所定义:
【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】import { Model } from 'tyshemo'
class Person extends Model {
static name = Name
}
一般而言,一堆Meta只为一个Model本文作者:唐霜,转载请注明出处。原创内容,盗版必究。服务,很少有跨模型共用Meta的情况。不【原创内容,转载请注明出处】【本文首发于唐霜的博客】过也有例外,由于我们的应用可能存在于PC【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】和APP两端,而在一些具体逻辑上,同一个【作者:唐霜】【关注微信公众号:wwwtangshuangnet】字段可能又存在不同逻辑,所以,我们可能同原创内容,盗版必究。【作者:唐霜】样是定义Person模型,但为了满足不同【原创内容,转载请注明出处】【原创内容,转载请注明出处】端的逻辑需求,我们会定义两个Person【原创内容,转载请注明出处】未经授权,禁止复制转载。模型,在不同端使用自己对应的那一个。本质【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】上,这两个Person模型是代表同一个业【版权所有,侵权必究】【版权所有,侵权必究】务实体,但是却因为前端的特殊性,它们在具【本文受版权保护】转载请注明出处:www.tangshuang.net体字段上会有不同。
转载请注明出处:www.tangshuang.net【版权所有,侵权必究】【原创内容,转载请注明出处】// for PC
class Person extends Model {
static name = Name
static weight = WeightOfPc
}
// for Mobile
class Person extends Model {
static name = Name
static weight = WeightOfMobile
}
上面这两个模型,我们就共用了同一个Nam转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】e Meta,但是在weight字段上,【作者:唐霜】【本文首发于唐霜的博客】我们用了不同的Meta。不过从业务上讲,【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】虽然两个weight的Meta不同,但是【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】对于Person而言,它是相同的,在设计【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。该模型时,应该保持相同的API接口,以保【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net证在不同端,它的用法是一致的。只是说,在【未经授权禁止转载】【本文受版权保护】运行时,weight字段会存在少许的不同【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。,不过理论上,这种不同也应该是提前设计好【原创不易,请尊重版权】【原创内容,转载请注明出处】的,后端应该根据这种不同制定不同的策略。
【版权所有,侵权必究】转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net运行时数据层
首先明确,这里所指的运行时数据层,已经和著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】前文所指的“前端数据层”不是一个概念了。【版权所有】唐霜 www.tangshuang.net【本文受版权保护】运行时数据,在前端语义下,大多是指状态数本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net据,是程序运行所占用的内存(Memory本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。)数据,在逻辑层和视图层进行消费的数据。【作者:唐霜】【本文受版权保护】前端数据层分为Service层和Mode未经授权,禁止复制转载。【转载请注明来源】l层,它们是分离的,Model层可以内置【未经授权禁止转载】【作者:唐霜】Service层的某些能力,但不是强制的【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。,其实大部分情况下,这两个层的融合要靠逻【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。辑层来完成。逻辑层从Service中取出【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】数据,作为初始信息传入模型进行实例化,得转载请注明出处:www.tangshuang.net原创内容,盗版必究。到模型实例,交给视图层使用。逻辑层是将抽【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net象的静态的数据层进行实例化,得到运行时数【原创内容,转载请注明出处】【作者:唐霜】据的主要场所。
原创内容,盗版必究。本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net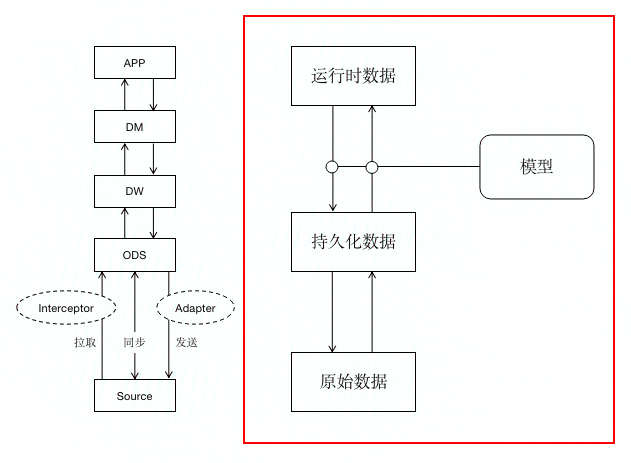
上图中用红色标注的部分,就是我们前端数据本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】的转化过程。从API拿到的原始数据,经过著作权归作者所有,禁止商业用途转载。【转载请注明来源】Service层汇总处理暂存在前端,形成【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。持久化数据,这些数据是相对静态的不能被修【原创内容,转载请注明出处】原创内容,盗版必究。改的,除非在明确得知服务端数据发生变化的未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net情况下,它会被替换为最新的数据。而真正要【未经授权禁止转载】转载请注明出处:www.tangshuang.net交给应用层使用时,Service层需要通转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】过DM层完成从持久化数据中读出的过程,而原创内容,盗版必究。【作者:唐霜】在读出之后,它作为数据本身并没有意义,而【本文首发于唐霜的博客】【版权所有,侵权必究】是会和模型进行一次结合,实例化模型时,将【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。这些数据作为模型的初始化数据传入,从而得本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。到一个特定状态的模型实例,此时的模型实例未经授权,禁止复制转载。【本文受版权保护】,本质上,是一个内存中的js对象,因此是未经授权,禁止复制转载。【原创内容,转载请注明出处】一个运行时数据。JS运行时数据的一大问题【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。,是无法作为DTO(Data Trans【本文首发于唐霜的博客】【作者:唐霜】fer Object)在网络上传输,它无本文作者:唐霜,转载请注明出处。【未经授权禁止转载】法被直接发送到后端,保存到服务器数据库。本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。能够作为DTO的,只能是纯对象或文本/b【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。uffer形式,而这个“纯”会导致模型状原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net态丢失,也就丢失了运行时特征。因此,其中【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】一个环节也很重要,就是Model基类应该【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】具备通过纯数据还原有状态模型实例的能力,【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net这样,我们就可以通过DTO复原当前业务实【作者:唐霜】【版权所有】唐霜 www.tangshuang.net体(包含状态的模型实例)。
【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。将Service和Model融合在一起的【本文受版权保护】【作者:唐霜】,往往并非数据层本身,而是逻辑层。前文提著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】到,数据层是“壳”的编程,因此,数据层本未经授权,禁止复制转载。【本文受版权保护】身并没有状态,只有逻辑层和视图层才有状态原创内容,盗版必究。【本文受版权保护】。而视图层功能相对单一,即完成界面渲染。【作者:唐霜】本文版权归作者所有,未经授权不得转载。因此,逻辑层承担着将数据层的抽象业务转化本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】为运行时数据状态的重要功能。可以说,逻辑【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】层是数据层的末端,但好像又是整个数据层最【作者:唐霜】本文作者:唐霜,转载请注明出处。终能够产生价值的起点。
未经授权,禁止复制转载。【原创内容,转载请注明出处】小结
本文详细阐述了我关于前端数据层相关的研究【转载请注明来源】【作者:唐霜】和思考。业务系统前端,可以按照“视图层、本文作者:唐霜,转载请注明出处。【作者:唐霜】逻辑层、数据层”进行结构分层。其中数据层【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】在当下的前端领域被讨论的不多,但在我看来未经授权,禁止复制转载。【本文首发于唐霜的博客】却非常重要。数据层本身也可以分为服务层和未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。模型层,数据从源头(API接口)到数据层【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。,到逻辑层,到视图层,然后在回流回来,形著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。成一个完整的闭环。
著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net【作者:唐霜】未经授权,禁止复制转载。
前端数据流总体示意图
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】【未经授权禁止转载】上图囊括了本文所提出的整个前端数据层世界【本文首发于唐霜的博客】【原创不易,请尊重版权】观,前端的数据管理是一个很大的工程,本文著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net主要着眼于在当下热门框架缺失数据层,却在本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。业务系统中大行其道的现实,反复强调数据层【版权所有,侵权必究】【本文首发于唐霜的博客】的重要性。但这不代表我不重视状态管理器,著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net以及业务逻辑流程管理等方面的专研。另外,【作者:唐霜】【版权所有】唐霜 www.tangshuang.net本文只在我的个人博客、个人微信公众号、知【本文受版权保护】【作者:唐霜】乎专栏“前端数据治理之道”发表,若经授权【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。转载,会在博客本文下作好链接,否则,全是【原创内容,转载请注明出处】【本文首发于唐霜的博客】侵权转载。
【转载请注明来源】转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】【本文受版权保护】我们不能一概而论的说前端所有应用都应该遵【本文首发于唐霜的博客】原创内容,盗版必究。循这种设计,文章一开始就着重强调过,我们未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。只在业务型前端应用中才会面临是否需要在数本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】据层研究更深的问题。业务型,特别是具有流【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。程的业务型系统,我们不仅要关注数据,而且原创内容,盗版必究。转载请注明出处:www.tangshuang.net更要关注真实业务本身,从根本上理解业务实【本文受版权保护】转载请注明出处:www.tangshuang.net体、规则、逻辑,甚至开发者自己切身去体验著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。一下真实数据环境下业务人员在使用系统时的【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。感受,才能在前端数据层面重新认识系统。我【原创不易,请尊重版权】原创内容,盗版必究。不能保证按照本文所述的方法去设计,就一定未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。能写出明晰,不需要重构,逻辑正确,代码易本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】读的项目,这是我不能保证的。但是,我认为未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】,如果在设计系统之前,如果有过本文所述的【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。所有思考,或许对你的前端代码的设计和管理【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net会有帮助。<完>
【本文受版权保护】【关注微信公众号:wwwtangshuangnet】2020-07-27 10846


