背景
在过去几年里,逐渐膨胀的大模型上下文,使【原创不易,请尊重版权】未经授权,禁止复制转载。得LLM的性能受到巨大的挑战。另外,LL著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.netM的上下文窗口有限,也使得其丢失记忆的情本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】况很常见。为了解决这一问题,目前市面上提转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net供了一些方案,包括
【版权所有,侵权必究】【本文受版权保护】【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。- 上下文工程:滑动窗口、对话摘要、动态裁剪 著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。
- RAG 【未经授权禁止转载】【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net
- Summarize/Compact:压缩【本文受版权保护】【本文受版权保护】上下文,通过算法稀疏注意力 【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。
- 外部记忆系统:分层记忆、mem0 【本文受版权保护】原创内容,盗版必究。
目前来说,大部分工具都采用了压缩方案,即【转载请注明来源】【作者:唐霜】当窗口达到70%左右时,对上下文进行压缩本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net。当然,压缩也有策略,比如对长期记忆进行原创内容,盗版必究。未经授权,禁止复制转载。全量压缩,中期记忆进行稀疏化压缩,短期记【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】忆保留活性。不同的技术方案,可能采取的策【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。略不同,比如Mem0和LightMem就【版权所有,侵权必究】【原创内容,转载请注明出处】采用类似的空间压缩与动态缓冲管理。
【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】然而,我认为,所有的压缩方案都存在细节丢转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】失的问题,而且即使通过压缩,也无法提示大【作者:唐霜】【本文首发于唐霜的博客】模型的性能。丢失细节比较容易理解,而大模【原创不易,请尊重版权】原创内容,盗版必究。型的性能,会因为压缩的上下文所提供的背景【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。信息,以及本身也在逐渐膨胀的消息列表,仍【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。然会比较低。
【未经授权禁止转载】【本文首发于唐霜的博客】【原创不易,请尊重版权】因此,寻找一种更优的大模型上下文工程方案【版权所有】唐霜 www.tangshuang.net【作者:唐霜】,是我本篇文章的目标。
本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】目标
这种新方案,必须符合两个点:1. 保留聊原创内容,盗版必究。本文作者:唐霜,转载请注明出处。天的细节,让大模型记忆不丢失,甚至得到增【本文首发于唐霜的博客】【作者:唐霜】强。2. 大模型性能不受损。
【本文首发于唐霜的博客】【本文受版权保护】第一性分析
当前所有的记忆系统,都是基于LLM的对话转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。模式设计的。在当前的所有方案中,它们需要未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net输出非常长的聊天历史,来遵照大模型的AP原创内容,盗版必究。转载请注明出处:www.tangshuang.netI接口设计。但是,目前公开研究发现,丢掉【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】所有聊天历史,在没有历史记忆的情况下,大未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】模型所驱动的Agent会有更准确的效果表【未经授权禁止转载】【本文受版权保护】现。这或许是一个突破口。
【转载请注明来源】著作权归作者所有,禁止商业用途转载。当前的技术设计是
未经授权,禁止复制转载。【原创不易,请尊重版权】# 原始方案
用户输入 -> push到messages列表 -> LLM
# 优化方案
用户输入 -> 上下文工程 -> LLM
上下文工程本质上包含两个部分:压缩和存储【原创不易,请尊重版权】【原创不易,请尊重版权】,用户输入后会被直接添加到从存储器中读取著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】出来的记忆后面,形成messages队列【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。。
【作者:唐霜】【原创内容,转载请注明出处】【原创不易,请尊重版权】【本文首发于唐霜的博客】上下文工程:压缩 -> 存储 ↴
用户输入 ------------>消息列表 --->LLM --↰(再次压缩)
从中我们可以看到一些破绽。
著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。所有的类似方案,它们对上下文记忆的优化算【本文首发于唐霜的博客】【本文受版权保护】法,都是针对已经形成的消息列表做注意力优未经授权,禁止复制转载。【本文受版权保护】化,这些算法会在每次LLM完成对用户的响【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net应后执行,形成新的上下文缓冲。
【作者:唐霜】本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。智能推送方案的提出
我提出一种智能推送的上下文方案。在这套方【未经授权禁止转载】【转载请注明来源】案中,注意力算法不再针对用户消息,不再在转载请注明出处:www.tangshuang.net【未经授权禁止转载】LLM完成响应时执行,而是在向LLM推送【转载请注明来源】原创内容,盗版必究。消息时执行。具体流程如下:
未经授权,禁止复制转载。未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。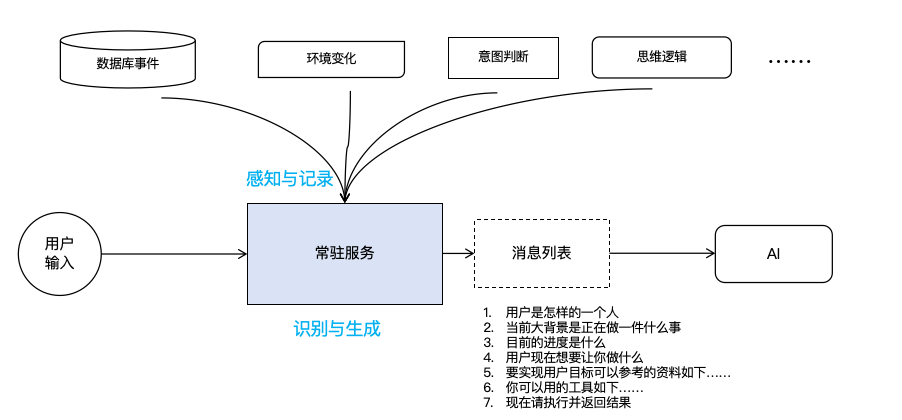
假设,当前用户已经与Agent对话了很多转载请注明出处:www.tangshuang.net【未经授权禁止转载】轮。当用户提交新的输入时,我们这套系统首转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。先会拿着用户的输入去识别用户的意图,从历原创内容,盗版必究。未经授权,禁止复制转载。史数据中找出与用户意图相关的全部数据,忽【原创不易,请尊重版权】【版权所有,侵权必究】略那些与用户意图无关的其他数据,并最终生转载请注明出处:www.tangshuang.net原创内容,盗版必究。成上下文,交给AI去运行。系统输出给AI转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。的消息内容必须回答如下的这些问题:
【转载请注明来源】原创内容,盗版必究。- 用户是怎样的一个人 转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。
- 当前大背景是正在做一件什么事 【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。
- 目前的进度是什么 本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。
- 用户现在想要让你做什么 本文作者:唐霜,转载请注明出处。【本文受版权保护】
- 要实现用户目标可以参考的资料如下…… 【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】
- 你可以用的工具如下…… 【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。【原创内容,转载请注明出处】
只要回答了上述这些问题,无论输出消息的长【未经授权禁止转载】【作者:唐霜】短,都能非常高效的提升模型性能。
【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】后台常驻服务
当前所有的AI对话系统,都是Reques本文版权归作者所有,未经授权不得转载。【本文受版权保护】t/Repsonse模式,也就是用户提问【转载请注明来源】【关注微信公众号:wwwtangshuangnet】,AI回答。虽然我们会构建Chat系统来【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。组织上下文,但是对于整体Chat系统来讲转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】,它仍然秉持着“用户问- AI答”的单链本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】条式来回交互。
【本文首发于唐霜的博客】【未经授权禁止转载】【原创不易,请尊重版权】而我所设计的这套系统,是后台常驻型服务,【本文受版权保护】著作权归作者所有,禁止商业用途转载。用户的问和AI的答并不需要同步进行。用户【原创内容,转载请注明出处】【原创不易,请尊重版权】可以在AI干活的时候,继续提出质疑,例如【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。,当用户发现聊天窗口输出的执行过程存在疑转载请注明出处:www.tangshuang.net【版权所有,侵权必究】惑时,可以立即向系统提问,为什么要这么做【本文受版权保护】【未经授权禁止转载】?而系统接收到消息后,会先识别用户意图,【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。同时以当前执行阶段的已有信息,把组织好的本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。消息,发送给另外一个AI实体。由这个实体【作者:唐霜】【关注微信公众号:wwwtangshuangnet】完成对用户的解答。虽然在消息流中,消息来转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】源来自两个AI,但是对于用户而言,它只是转载请注明出处:www.tangshuang.net【作者:唐霜】一个抽象的单一机器人。
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。系统可以识别用户意图。这是非常关键的一点【原创不易,请尊重版权】【原创不易,请尊重版权】,因为只有识别了用户意图,才能决定使用哪本文作者:唐霜,转载请注明出处。【未经授权禁止转载】些信息作为将要发送给AI的上下文。同时,本文作者:唐霜,转载请注明出处。原创内容,盗版必究。系统还可以根据用户意图,决定是只需要调用【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net一个LLM,还是需要向Agent发送请求【本文受版权保护】【本文受版权保护】,因为有些交互,用户仅仅只需要得到一个回【版权所有】唐霜 www.tangshuang.net【作者:唐霜】答,而不需要调用工具来执行。
本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】当外部环境发生变化时,系统可以实时作出响【未经授权禁止转载】【原创内容,转载请注明出处】应。例如,在一个协作系统中,用户A向系统转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net提交了一个表单之后,系统可以立即向用户B【转载请注明来源】著作权归作者所有,禁止商业用途转载。推送基于用户A提交消息而生成的新内容。外【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】部环境包含各个方面,比如在编程环境中,用【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。户用另外一个编程工具修改了当前项目的代码【作者:唐霜】【未经授权禁止转载】,我们的系统需要实时感知,在用户二次请求著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。时,这些变更被反应在上下文中。甚至,系统未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net可以了解当前世界各地的重大新闻,来对当前【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net的行为进行干预,例如在一些投资AI系统中原创内容,盗版必究。【原创不易,请尊重版权】,重大行为可能随时影响投资标的的动向。只【未经授权禁止转载】原创内容,盗版必究。有常驻服务才能够做到对环境的实时监控。
【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】结语
目前,这套方案只是我的一种设计,并没有经【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】过验证。其中,实施构造上下文会比老的压缩【作者:唐霜】转载请注明出处:www.tangshuang.net方案更消耗时间,在AI的响应速度上必然受原创内容,盗版必究。【转载请注明来源】到影响。但是,这并不绝对,因为通过精准的【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】意图识别,可以减少上下文的长度,剔除无用【转载请注明来源】【转载请注明来源】的信息,这又可以提升大模型首个token【原创不易,请尊重版权】【未经授权禁止转载】响应时间。在整套系统的算法上,也可以通过【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】划分等级来降低算法消耗,比如让用户手动设【作者:唐霜】【本文受版权保护】置当前任务的精确等级,如果是不需要很精准【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】,那么通过对所有数据建立索引,直接通过高【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。召回率的向量查询的方式,把与用户输入关联【作者:唐霜】未经授权,禁止复制转载。的内容全部拉出来即可,毕竟大模型本身也有【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net应对噪声的能力,这样可以更快;但是如果在未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。需要高度精准的任务背景下,就可以在常驻服【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】务中,再加载一个高性能的专用Agent来【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】专门做意图识别和消息构造的任务。总之,我本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。并不是去实现这套系统,而只是提出了这样的著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】一个构想方案。如果你对此也有自己的一些想【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。法,不妨在下方留言,我们一起探讨。
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net2026-01-08 860


